 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoFLUX: Distillation-Driven Compression of Large Text-to-Image Generation Models for Mobile Devices
Feb 06, 2026While large-scale text-to-image diffusion models continue to improve in visual quality, their increasing scale has widened the gap between state-of-the-art models and on-device solutions. To address this gap, we introduce NanoFLUX, a 2.4B text-to-image flow-matching model distilled from 17B FLUX.1-Schnell using a progressive compression pipeline designed to preserve generation quality. Our contributions include: (1) A model compression strategy driven by pruning redundant components in the diffusion transformer, reducing its size from 12B to 2B; (2) A ResNet-based token downsampling mechanism that reduces latency by allowing intermediate blocks to operate on lower-resolution tokens while preserving high-resolution processing elsewhere; (3) A novel text encoder distillation approach that leverages visual signals from early layers of the denoiser during sampling. Empirically, NanoFLUX generates 512 x 512 images in approximately 2.5 seconds on mobile devices, demonstrating the feasibility of high-quality on-device text-to-image generation.
RFDM: Residual Flow Diffusion Model for Efficient Causal Video Editing
Feb 06, 2026Instructional video editing applies edits to an input video using only text prompts, enabling intuitive natural-language control. Despite rapid progress, most methods still require fixed-length inputs and substantial compute. Meanwhile, autoregressive video generation enables efficient variable-length synthesis, yet remains under-explored for video editing. We introduce a causal, efficient video editing model that edits variable-length videos frame by frame. For efficiency, we start from a 2D image-to-image (I2I) diffusion model and adapt it to video-to-video (V2V) editing by conditioning the edit at time step t on the model's prediction at t-1. To leverage videos' temporal redundancy, we propose a new I2I diffusion forward process formulation that encourages the model to predict the residual between the target output and the previous prediction. We call this Residual Flow Diffusion Model (RFDM), which focuses the denoising process on changes between consecutive frames. Moreover, we propose a new benchmark that better ranks state-of-the-art methods for editing tasks. Trained on paired video data for global/local style transfer and object removal, RFDM surpasses I2I-based methods and competes with fully spatiotemporal (3D) V2V models, while matching the compute of image models and scaling independently of input video length. More content can be found in: https://smsd75.github.io/RFDM_page/
EDiT: Efficient Diffusion Transformers with Linear Compressed Attention
Mar 20, 2025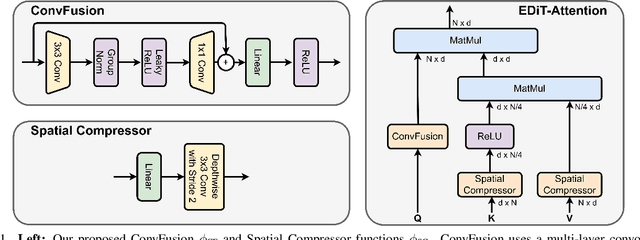
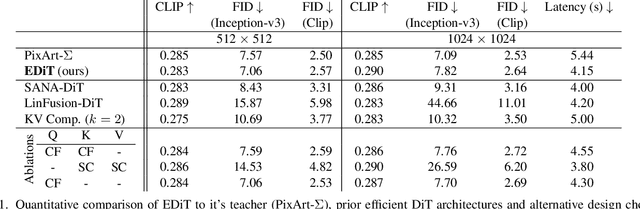
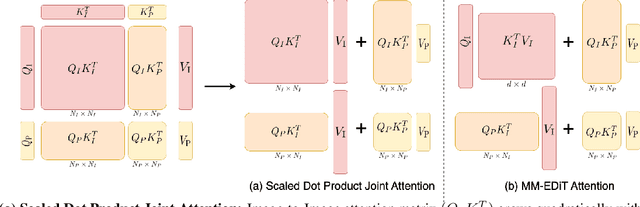
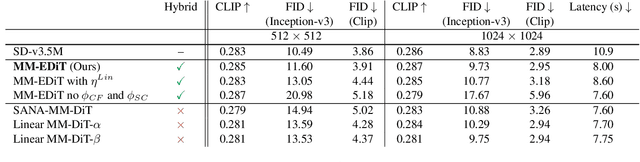
Diffusion Transformers (DiTs) have emerged as a leading architecture for text-to-image synthesis, producing high-quality and photorealistic images. However, the quadratic scaling properties of the attention in DiTs hinder image generation with higher resolution or on devices with limited resources. This work introduces an efficient diffusion transformer (EDiT) to alleviate these efficiency bottlenecks in conventional DiTs and Multimodal DiTs (MM-DiTs). First, we present a novel linear compressed attention method that uses a multi-layer convolutional network to modulate queries with local information while keys and values are spatially aggregated. Second, we formulate a hybrid attention scheme for multi-modal inputs that combines linear attention for image-to-image interactions and standard scaled dot-product attention for interactions involving prompts. Merging these two approaches leads to an expressive, linear-time Multimodal Efficient Diffusion Transformer (MM-EDiT). We demonstrate the effectiveness of the EDiT and MM-EDiT architectures by integrating them into PixArt-Sigma(conventional DiT) and Stable Diffusion 3.5-Medium (MM-DiT), achieving up to 2.2x speedup with comparable image quality after distillation.
Upcycling Text-to-Image Diffusion Models for Multi-Task Capabilities
Mar 14, 2025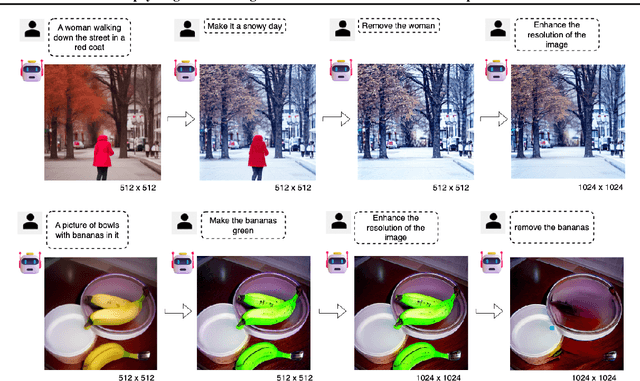
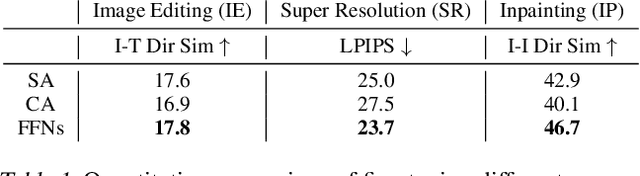
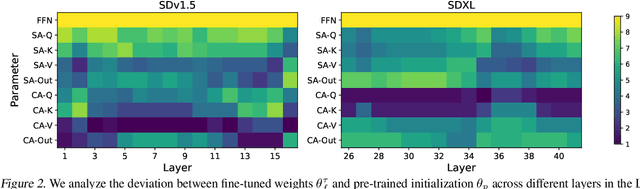
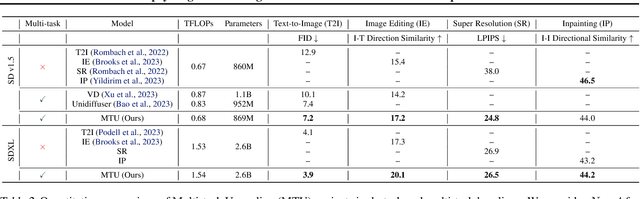
Text-to-image synthesis has witnessed remarkable advancements in recent years. Many attempts have been made to adopt text-to-image models to support multiple tasks. However, existing approaches typically require resource-intensive re-training or additional parameters to accommodate for the new tasks, which makes the model inefficient for on-device deployment. We propose Multi-Task Upcycling (MTU), a simple yet effective recipe that extends the capabilities of a pre-trained text-to-image diffusion model to support a variety of image-to-image generation tasks. MTU replaces Feed-Forward Network (FFN) layers in the diffusion model with smaller FFNs, referred to as experts, and combines them with a dynamic routing mechanism. To the best of our knowledge, MTU is the first multi-task diffusion modeling approach that seamlessly blends multi-tasking with on-device compatibility, by mitigating the issue of parameter inflation. We show that the performance of MTU is on par with the single-task fine-tuned diffusion models across several tasks including image editing, super-resolution, and inpainting, while maintaining similar latency and computational load (GFLOPs) as the single-task fine-tuned models.
Edge-SD-SR: Low Latency and Parameter Efficient On-device Super-Resolution with Stable Diffusion via Bidirectional Conditioning
Dec 09, 2024



There has been immense progress recently in the visual quality of Stable Diffusion-based Super Resolution (SD-SR). However, deploying large diffusion models on computationally restricted devices such as mobile phones remains impractical due to the large model size and high latency. This is compounded for SR as it often operates at high res (e.g. 4Kx3K). In this work, we introduce Edge-SD-SR, the first parameter efficient and low latency diffusion model for image super-resolution. Edge-SD-SR consists of ~169M parameters, including UNet, encoder and decoder, and has a complexity of only ~142 GFLOPs. To maintain a high visual quality on such low compute budget, we introduce a number of training strategies: (i) A novel conditioning mechanism on the low resolution input, coined bidirectional conditioning, which tailors the SD model for the SR task. (ii) Joint training of the UNet and encoder, while decoupling the encodings of the HR and LR images and using a dedicated schedule. (iii) Finetuning the decoder using the UNet's output to directly tailor the decoder to the latents obtained at inference time. Edge-SD-SR runs efficiently on device, e.g. it can upscale a 128x128 patch to 512x512 in 38 msec while running on a Samsung S24 DSP, and of a 512x512 to 2048x2048 (requiring 25 model evaluations) in just ~1.1 sec. Furthermore, we show that Edge-SD-SR matches or even outperforms state-of-the-art SR approaches on the most established SR benchmarks.
You Only Need One Step: Fast Super-Resolution with Stable Diffusion via Scale Distillation
Jan 30, 2024
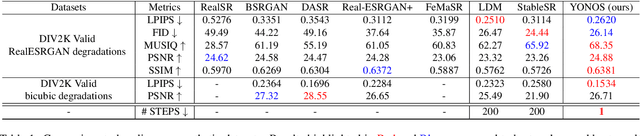
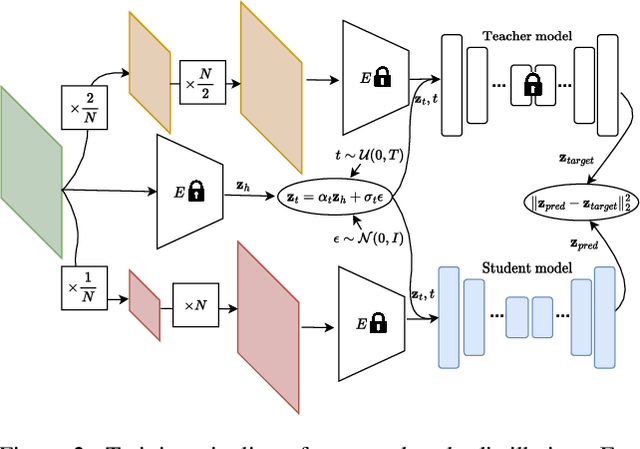

In this paper, we introduce YONOS-SR, a novel stable diffusion-based approach for image super-resolution that yields state-of-the-art results using only a single DDIM step. We propose a novel scale distillation approach to train our SR model. Instead of directly training our SR model on the scale factor of interest, we start by training a teacher model on a smaller magnification scale, thereby making the SR problem simpler for the teacher. We then train a student model for a higher magnification scale, using the predictions of the teacher as a target during the training. This process is repeated iteratively until we reach the target scale factor of the final model. The rationale behind our scale distillation is that the teacher aids the student diffusion model training by i) providing a target adapted to the current noise level rather than using the same target coming from ground truth data for all noise levels and ii) providing an accurate target as the teacher has a simpler task to solve. We empirically show that the distilled model significantly outperforms the model trained for high scales directly, specifically with few steps during inference. Having a strong diffusion model that requires only one step allows us to freeze the U-Net and fine-tune the decoder on top of it. We show that the combination of spatially distilled U-Net and fine-tuned decoder outperforms state-of-the-art methods requiring 200 steps with only one single step.
Unified Fully and Timestamp Supervised Temporal Action Segmentation via Sequence to Sequence Translation
Sep 01, 2022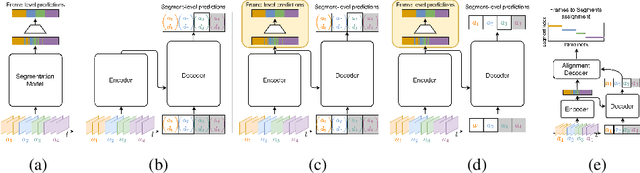
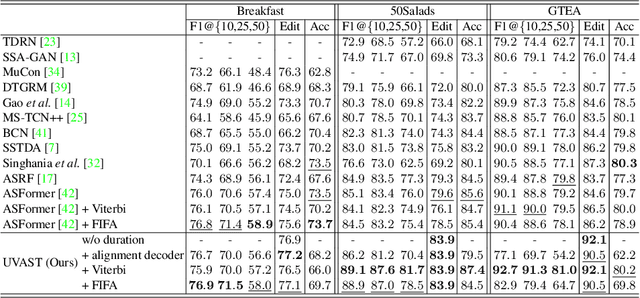
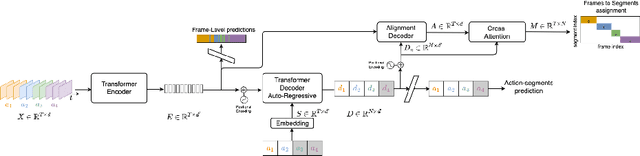
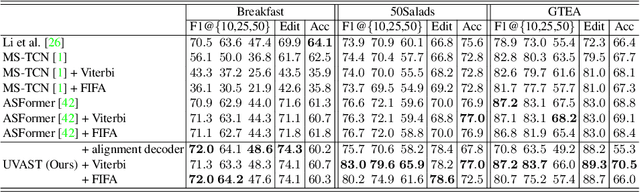
This paper introduces a unified framework for video action segmentation via sequence to sequence (seq2seq) translation in a fully and timestamp supervised setup. In contrast to current state-of-the-art frame-level prediction methods, we view action segmentation as a seq2seq translation task, i.e., mapping a sequence of video frames to a sequence of action segments. Our proposed method involves a series of modifications and auxiliary loss functions on the standard Transformer seq2seq translation model to cope with long input sequences opposed to short output sequences and relatively few videos. We incorporate an auxiliary supervision signal for the encoder via a frame-wise loss and propose a separate alignment decoder for an implicit duration prediction. Finally, we extend our framework to the timestamp supervised setting via our proposed constrained k-medoids algorithm to generate pseudo-segmentations. Our proposed framework performs consistently on both fully and timestamp supervised settings, outperforming or competing state-of-the-art on several datasets.
Ranking Info Noise Contrastive Estimation: Boosting Contrastive Learning via Ranked Positives
Jan 27, 2022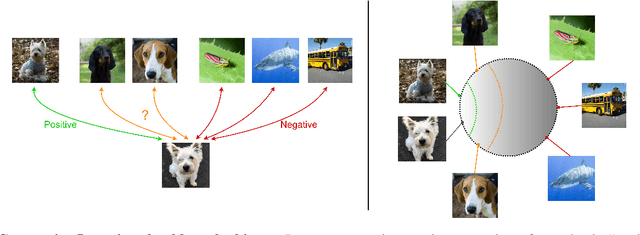

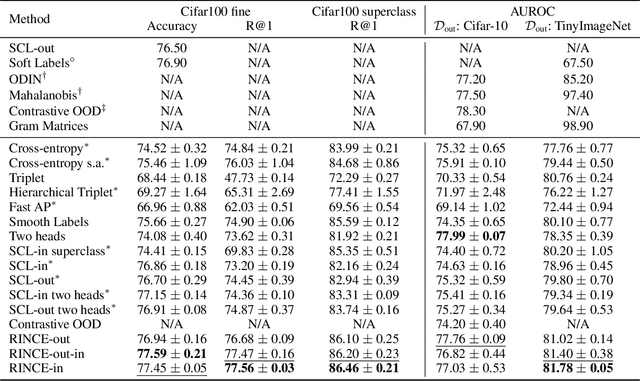
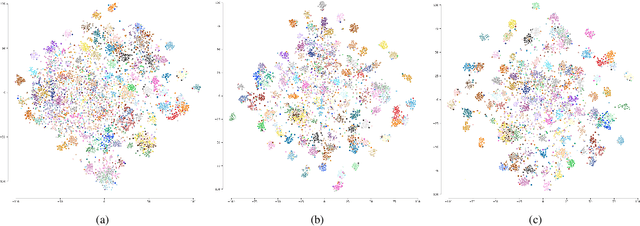
This paper introduces Ranking Info Noise Contrastive Estimation (RINCE), a new member in the family of InfoNCE losses that preserves a ranked ordering of positive samples. In contrast to the standard InfoNCE loss, which requires a strict binary separation of the training pairs into similar and dissimilar samples, RINCE can exploit information about a similarity ranking for learning a corresponding embedding space. We show that the proposed loss function learns favorable embeddings compared to the standard InfoNCE whenever at least noisy ranking information can be obtained or when the definition of positives and negatives is blurry. We demonstrate this for a supervised classification task with additional superclass labels and noisy similarity scores. Furthermore, we show that RINCE can also be applied to unsupervised training with experiments on unsupervised representation learning from videos. In particular, the embedding yields higher classification accuracy, retrieval rates and performs better in out-of-distribution detection than the standard InfoNCE loss.
Taylor Swift: Taylor Driven Temporal Modeling for Swift Future Frame Prediction
Oct 27, 2021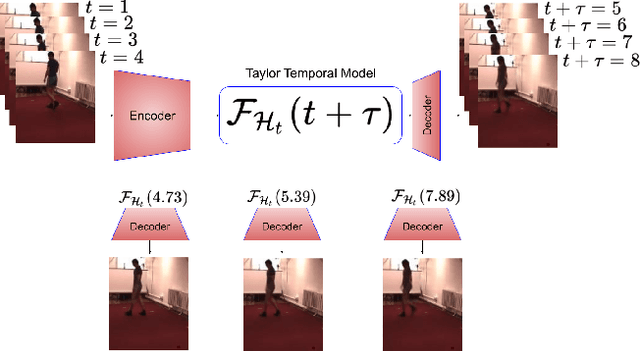
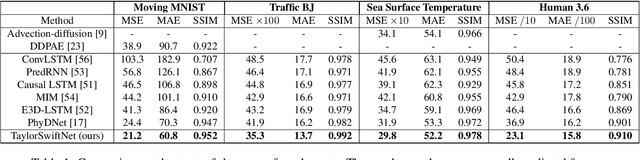
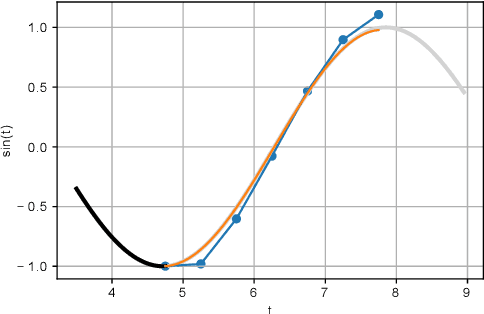

While recurrent neural networks (RNNs) demonstrate outstanding capabilities in future video frame prediction, they model dynamics in a discrete time space and sequentially go through all frames until the desired future temporal step is reached. RNNs are therefore prone to accumulate the error as the number of future frames increases. In contrast, partial differential equations (PDEs) model physical phenomena like dynamics in continuous time space, however, current PDE-based approaches discretize the PDEs using e.g., the forward Euler method. In this work, we therefore propose to approximate the motion in a video by a continuous function using the Taylor series. To this end, we introduce TayloSwiftNet, a novel convolutional neural network that learns to estimate the higher order terms of the Taylor series for a given input video. TayloSwiftNet can swiftly predict any desired future frame in just one forward pass and change the temporal resolution on-the-fly. The experimental results on various datasets demonstrate the superiority of our model.
Long Short View Feature Decomposition via Contrastive Video Representation Learning
Sep 23, 2021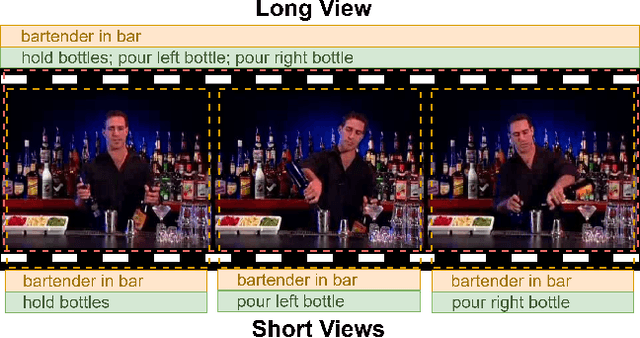
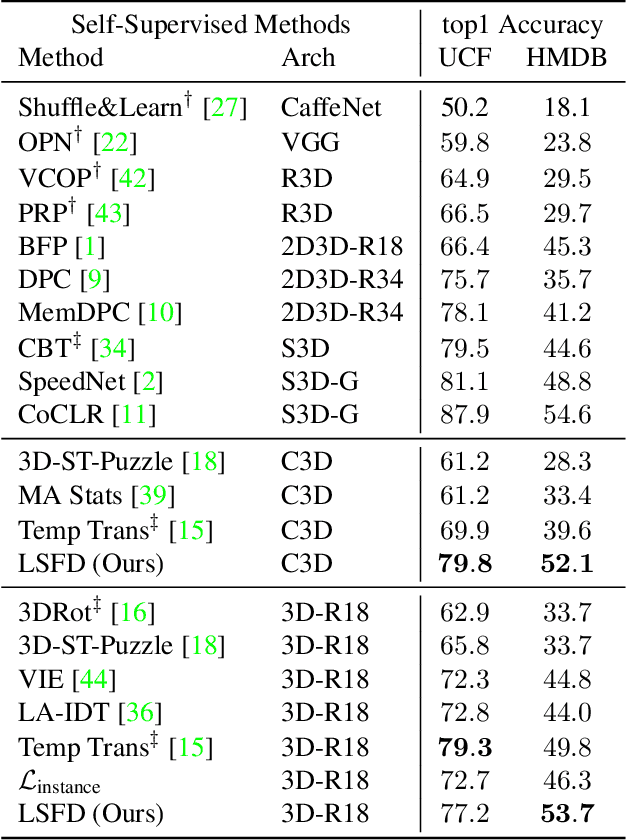
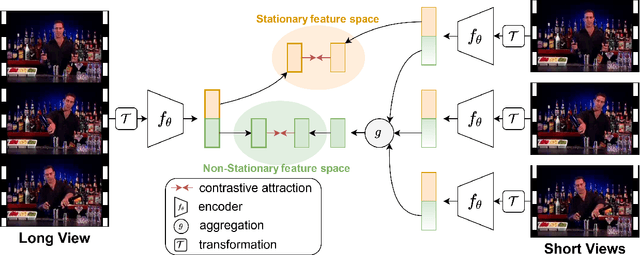
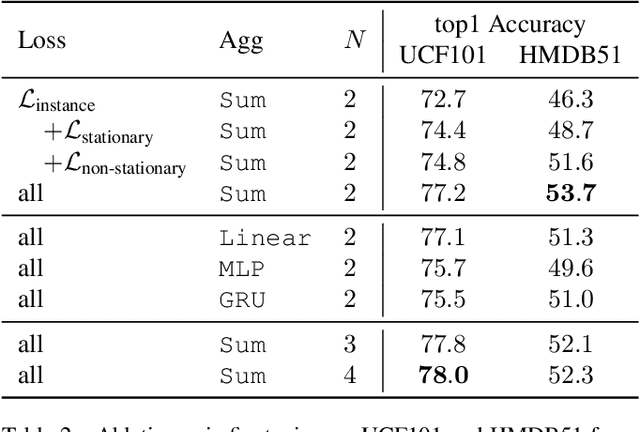
Self-supervised video representation methods typically focus on the representation of temporal attributes in videos. However, the role of stationary versus non-stationary attributes is less explored: Stationary features, which remain similar throughout the video, enable the prediction of video-level action classes. Non-stationary features, which represent temporally varying attributes, are more beneficial for downstream tasks involving more fine-grained temporal understanding, such as action segmentation. We argue that a single representation to capture both types of features is sub-optimal, and propose to decompose the representation space into stationary and non-stationary features via contrastive learning from long and short views, i.e. long video sequences and their shorter sub-sequences. Stationary features are shared between the short and long views, while non-stationary features aggregate the short views to match the corresponding long view. To empirically verify our approach, we demonstrate that our stationary features work particularly well on an action recognition downstream task, while our non-stationary features perform better on action segmentation. Furthermore, we analyse the learned representations and find that stationary features capture more temporally stable, static attributes, while non-stationary features encompass more temporally varying ones.