 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpcycling Text-to-Image Diffusion Models for Multi-Task Capabilities
Paper and Code
Mar 14, 2025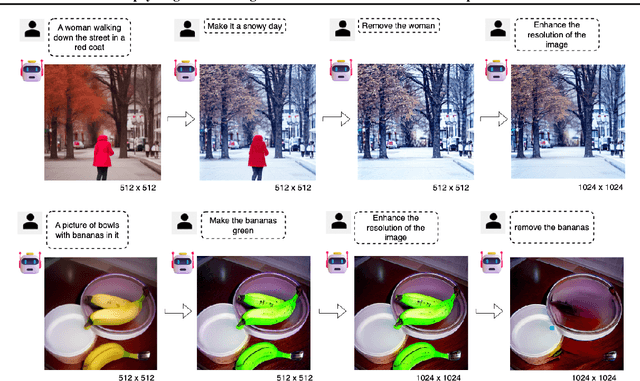
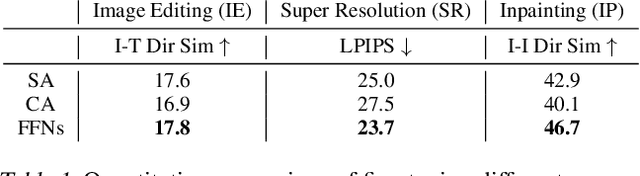
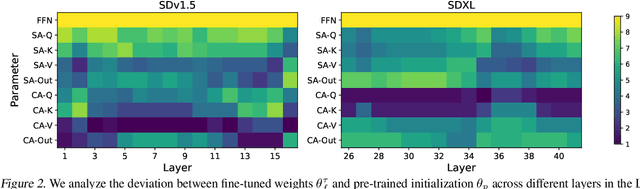
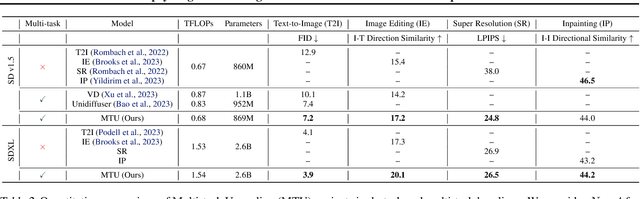
Text-to-image synthesis has witnessed remarkable advancements in recent years. Many attempts have been made to adopt text-to-image models to support multiple tasks. However, existing approaches typically require resource-intensive re-training or additional parameters to accommodate for the new tasks, which makes the model inefficient for on-device deployment. We propose Multi-Task Upcycling (MTU), a simple yet effective recipe that extends the capabilities of a pre-trained text-to-image diffusion model to support a variety of image-to-image generation tasks. MTU replaces Feed-Forward Network (FFN) layers in the diffusion model with smaller FFNs, referred to as experts, and combines them with a dynamic routing mechanism. To the best of our knowledge, MTU is the first multi-task diffusion modeling approach that seamlessly blends multi-tasking with on-device compatibility, by mitigating the issue of parameter inflation. We show that the performance of MTU is on par with the single-task fine-tuned diffusion models across several tasks including image editing, super-resolution, and inpainting, while maintaining similar latency and computational load (GFLOPs) as the single-task fine-tuned models.