 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFDM: Residual Flow Diffusion Model for Efficient Causal Video Editing
Feb 06, 2026Instructional video editing applies edits to an input video using only text prompts, enabling intuitive natural-language control. Despite rapid progress, most methods still require fixed-length inputs and substantial compute. Meanwhile, autoregressive video generation enables efficient variable-length synthesis, yet remains under-explored for video editing. We introduce a causal, efficient video editing model that edits variable-length videos frame by frame. For efficiency, we start from a 2D image-to-image (I2I) diffusion model and adapt it to video-to-video (V2V) editing by conditioning the edit at time step t on the model's prediction at t-1. To leverage videos' temporal redundancy, we propose a new I2I diffusion forward process formulation that encourages the model to predict the residual between the target output and the previous prediction. We call this Residual Flow Diffusion Model (RFDM), which focuses the denoising process on changes between consecutive frames. Moreover, we propose a new benchmark that better ranks state-of-the-art methods for editing tasks. Trained on paired video data for global/local style transfer and object removal, RFDM surpasses I2I-based methods and competes with fully spatiotemporal (3D) V2V models, while matching the compute of image models and scaling independently of input video length. More content can be found in: https://smsd75.github.io/RFDM_page/
NanoFLUX: Distillation-Driven Compression of Large Text-to-Image Generation Models for Mobile Devices
Feb 06, 2026While large-scale text-to-image diffusion models continue to improve in visual quality, their increasing scale has widened the gap between state-of-the-art models and on-device solutions. To address this gap, we introduce NanoFLUX, a 2.4B text-to-image flow-matching model distilled from 17B FLUX.1-Schnell using a progressive compression pipeline designed to preserve generation quality. Our contributions include: (1) A model compression strategy driven by pruning redundant components in the diffusion transformer, reducing its size from 12B to 2B; (2) A ResNet-based token downsampling mechanism that reduces latency by allowing intermediate blocks to operate on lower-resolution tokens while preserving high-resolution processing elsewhere; (3) A novel text encoder distillation approach that leverages visual signals from early layers of the denoiser during sampling. Empirically, NanoFLUX generates 512 x 512 images in approximately 2.5 seconds on mobile devices, demonstrating the feasibility of high-quality on-device text-to-image generation.
EDiT: Efficient Diffusion Transformers with Linear Compressed Attention
Mar 20, 2025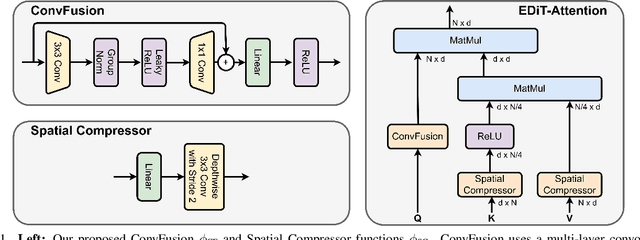
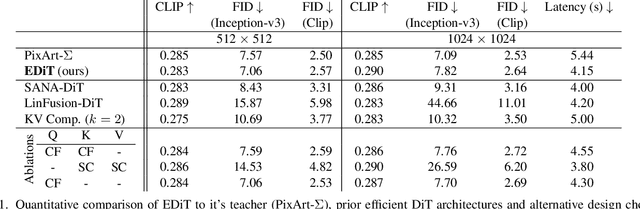
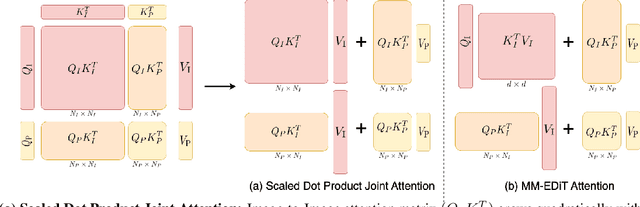
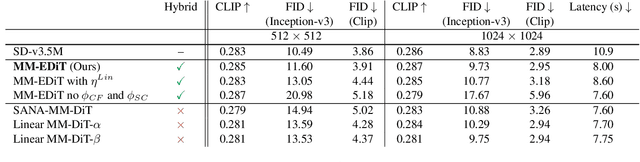
Diffusion Transformers (DiTs) have emerged as a leading architecture for text-to-image synthesis, producing high-quality and photorealistic images. However, the quadratic scaling properties of the attention in DiTs hinder image generation with higher resolution or on devices with limited resources. This work introduces an efficient diffusion transformer (EDiT) to alleviate these efficiency bottlenecks in conventional DiTs and Multimodal DiTs (MM-DiTs). First, we present a novel linear compressed attention method that uses a multi-layer convolutional network to modulate queries with local information while keys and values are spatially aggregated. Second, we formulate a hybrid attention scheme for multi-modal inputs that combines linear attention for image-to-image interactions and standard scaled dot-product attention for interactions involving prompts. Merging these two approaches leads to an expressive, linear-time Multimodal Efficient Diffusion Transformer (MM-EDiT). We demonstrate the effectiveness of the EDiT and MM-EDiT architectures by integrating them into PixArt-Sigma(conventional DiT) and Stable Diffusion 3.5-Medium (MM-DiT), achieving up to 2.2x speedup with comparable image quality after distillation.
Upcycling Text-to-Image Diffusion Models for Multi-Task Capabilities
Mar 14, 2025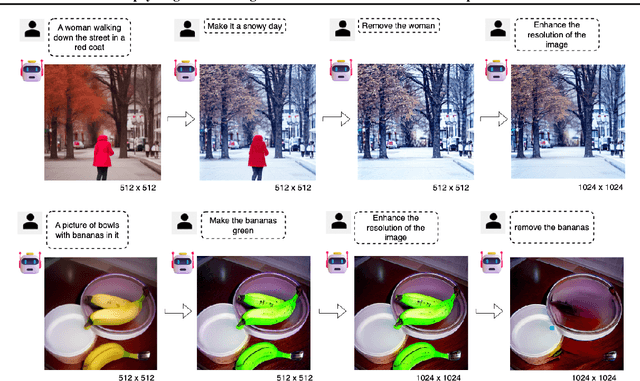
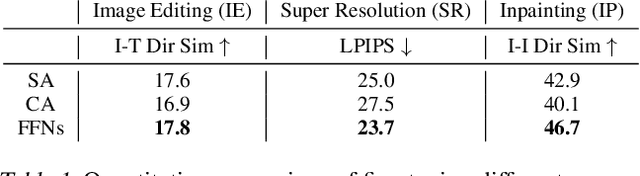
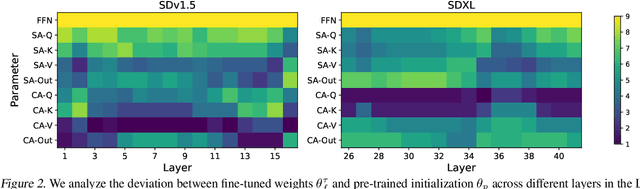
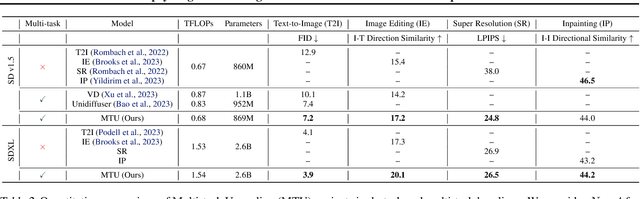
Text-to-image synthesis has witnessed remarkable advancements in recent years. Many attempts have been made to adopt text-to-image models to support multiple tasks. However, existing approaches typically require resource-intensive re-training or additional parameters to accommodate for the new tasks, which makes the model inefficient for on-device deployment. We propose Multi-Task Upcycling (MTU), a simple yet effective recipe that extends the capabilities of a pre-trained text-to-image diffusion model to support a variety of image-to-image generation tasks. MTU replaces Feed-Forward Network (FFN) layers in the diffusion model with smaller FFNs, referred to as experts, and combines them with a dynamic routing mechanism. To the best of our knowledge, MTU is the first multi-task diffusion modeling approach that seamlessly blends multi-tasking with on-device compatibility, by mitigating the issue of parameter inflation. We show that the performance of MTU is on par with the single-task fine-tuned diffusion models across several tasks including image editing, super-resolution, and inpainting, while maintaining similar latency and computational load (GFLOPs) as the single-task fine-tuned models.
Neural Semantic Surface Maps
Sep 09, 2023We present an automated technique for computing a map between two genus-zero shapes, which matches semantically corresponding regions to one another. Lack of annotated data prohibits direct inference of 3D semantic priors; instead, current State-of-the-art methods predominantly optimize geometric properties or require varying amounts of manual annotation. To overcome the lack of annotated training data, we distill semantic matches from pre-trained vision models: our method renders the pair of 3D shapes from multiple viewpoints; the resulting renders are then fed into an off-the-shelf image-matching method which leverages a pretrained visual model to produce feature points. This yields semantic correspondences, which can be projected back to the 3D shapes, producing a raw matching that is inaccurate and inconsistent between different viewpoints. These correspondences are refined and distilled into an inter-surface map by a dedicated optimization scheme, which promotes bijectivity and continuity of the output map. We illustrate that our approach can generate semantic surface-to-surface maps, eliminating manual annotations or any 3D training data requirement. Furthermore, it proves effective in scenarios with high semantic complexity, where objects are non-isometrically related, as well as in situations where they are nearly isometric.
Neural Convolutional Surfaces
Apr 05, 2022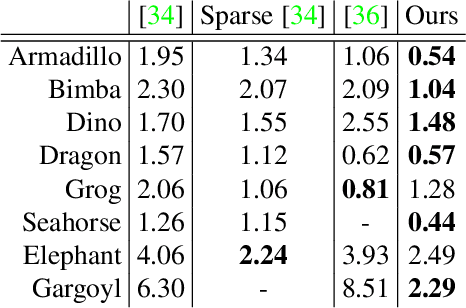

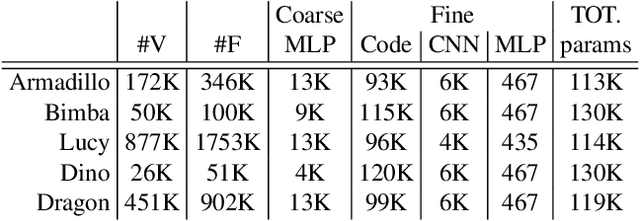

This work is concerned with a representation of shapes that disentangles fine, local and possibly repeating geometry, from global, coarse structures. Achieving such disentanglement leads to two unrelated advantages: i) a significant compression in the number of parameters required to represent a given geometry; ii) the ability to manipulate either global geometry, or local details, without harming the other. At the core of our approach lies a novel pipeline and neural architecture, which are optimized to represent one specific atlas, representing one 3D surface. Our pipeline and architecture are designed so that disentanglement of global geometry from local details is accomplished through optimization, in a completely unsupervised manner. We show that this approach achieves better neural shape compression than the state of the art, as well as enabling manipulation and transfer of shape details. Project page at http://geometry.cs.ucl.ac.uk/projects/2022/cnnmaps/ .
Neural Surface Maps
Mar 31, 2021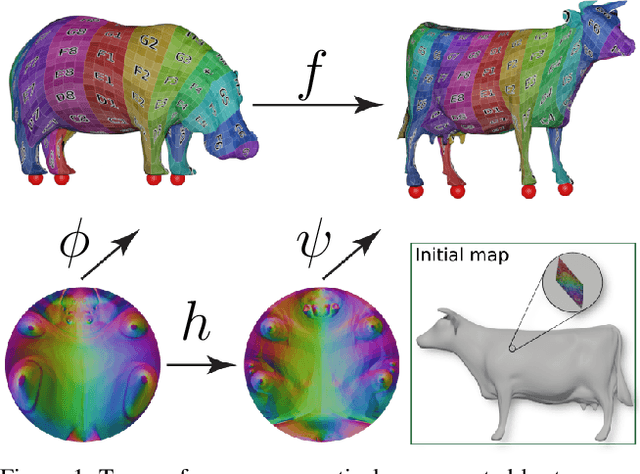

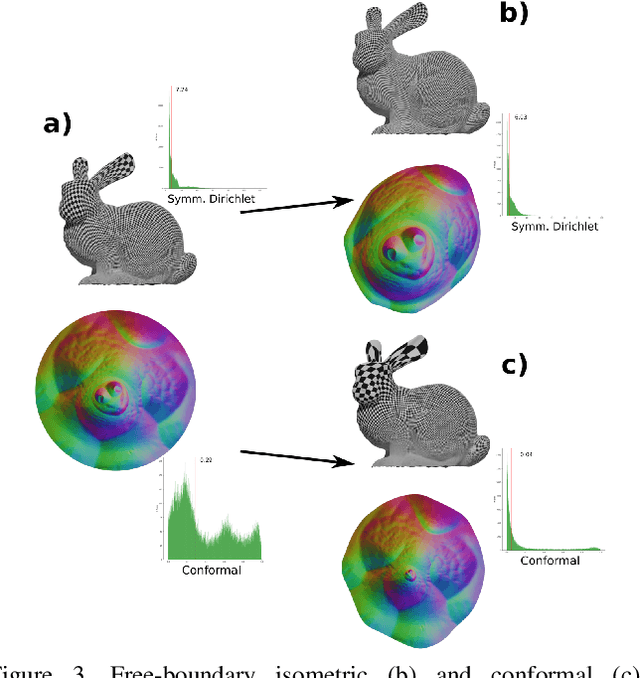

Maps are arguably one of the most fundamental concepts used to define and operate on manifold surfaces in differentiable geometry. Accordingly, in geometry processing, maps are ubiquitous and are used in many core applications, such as paramterization, shape analysis, remeshing, and deformation. Unfortunately, most computational representations of surface maps do not lend themselves to manipulation and optimization, usually entailing hard, discrete problems. While algorithms exist to solve these problems, they are problem-specific, and a general framework for surface maps is still in need. In this paper, we advocate considering neural networks as encoding surface maps. Since neural networks can be composed on one another and are differentiable, we show it is easy to use them to define surfaces via atlases, compose them for surface-to-surface mappings, and optimize differentiable objectives relating to them, such as any notion of distortion, in a trivial manner. In our experiments, we represent surfaces by generating a neural map that approximates a UV parameterization of a 3D model. Then, we compose this map with other neural maps which we optimize with respect to distortion measures. We show that our formulation enables trivial optimization of rather elusive mapping tasks, such as maps between a collection of surfaces.
Dense 3D Visual Mapping via Semantic Simplification
Feb 20, 2019

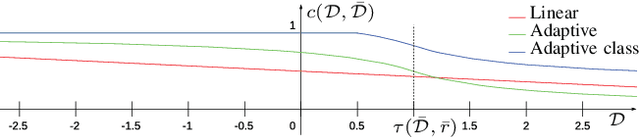
Dense 3D visual mapping estimates as many as possible pixel depths, for each image. This results in very dense point clouds that often contain redundant and noisy information, especially for surfaces that are roughly planar, for instance, the ground or the walls in the scene. In this paper we leverage on semantic image segmentation to discriminate which regions of the scene require simplification and which should be kept at high level of details. We propose four different point cloud simplification methods which decimate the perceived point cloud by relying on class-specific local and global statistics still maintaining more points in the proximity of class boundaries to preserve the infra-class edges and discontinuities. 3D dense model is obtained by fusing the point clouds in a 3D Delaunay Triangulation to deal with variable point cloud density. In the experimental evaluation we have shown that, by leveraging on semantics, it is possible to simplify the model and diminish the noise affecting the point clouds.
Predicting the Next Best View for 3D Mesh Refinement
May 16, 2018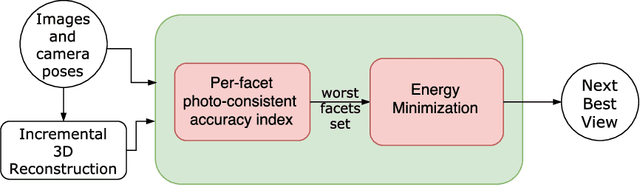
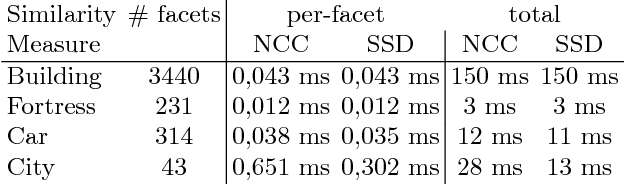

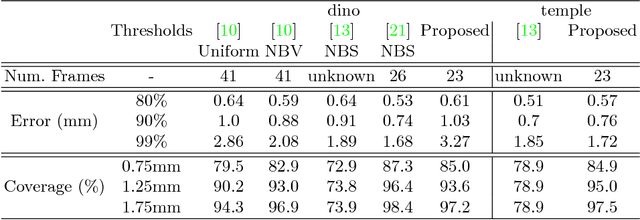
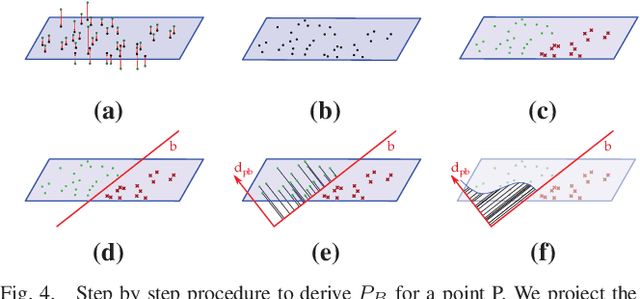
3D reconstruction is a core task in many applications such as robot navigation or sites inspections. Finding the best poses to capture part of the scene is one of the most challenging topic that goes under the name of Next Best View. Recently, many volumetric methods have been proposed; they choose the Next Best View by reasoning over a 3D voxelized space and by finding which pose minimizes the uncertainty decoded into the voxels. Such methods are effective, but they do not scale well since the underlaying representation requires a huge amount of memory. In this paper we propose a novel mesh-based approach which focuses on the worst reconstructed region of the environment mesh. We define a photo-consistent index to evaluate the 3D mesh accuracy, and an energy function over the worst regions of the mesh which takes into account the mutual parallax with respect to the previous cameras, the angle of incidence of the viewing ray to the surface and the visibility of the region. We test our approach over a well known dataset and achieve state-of-the-art results.