 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multi-View Stereo via Super-Resolution
Jul 28, 2021
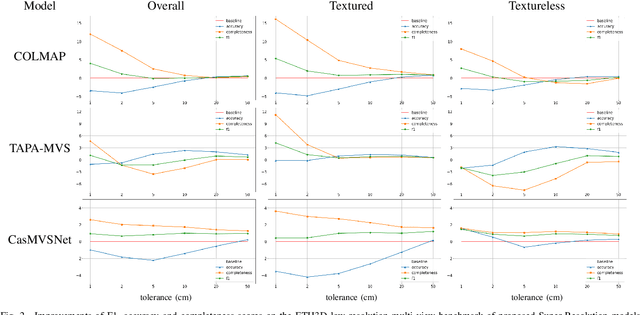
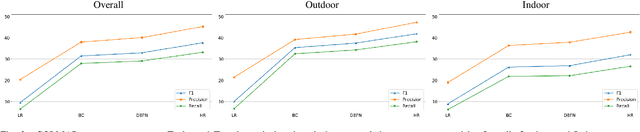

Today, Multi-View Stereo techniques are able to reconstruct robust and detailed 3D models, especially when starting from high-resolution images. However, there are cases in which the resolution of input images is relatively low, for instance, when dealing with old photos, or when hardware constrains the amount of data that can be acquired. In this paper, we investigate if, how, and how much increasing the resolution of such input images through Super-Resolution techniques reflects in quality improvements of the reconstructed 3D models, despite the artifacts that sometimes this may generate. We show that applying a Super-Resolution step before recovering the depth maps in most cases leads to a better 3D model both in the case of PatchMatch-based and deep-learning-based algorithms. The use of Super-Resolution improves especially the completeness of reconstructed models and turns out to be particularly effective in the case of textured scenes.
Facetwise Mesh Refinement for Multi-View Stereo
Dec 01, 2020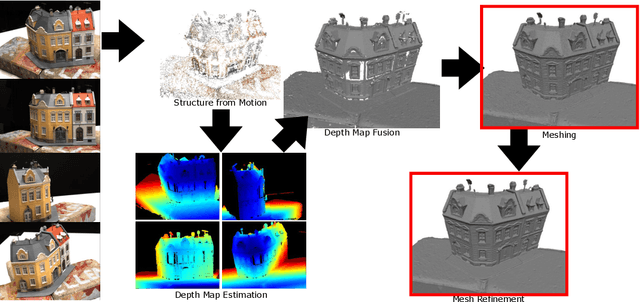

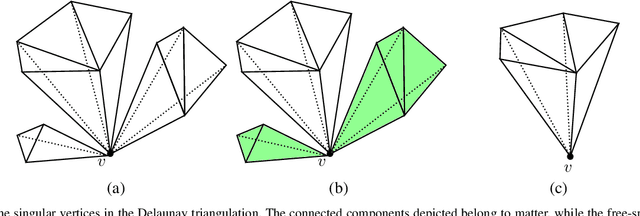
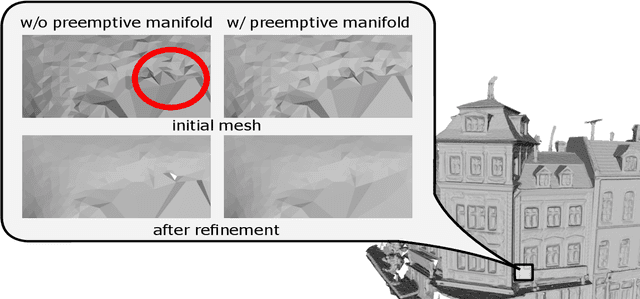
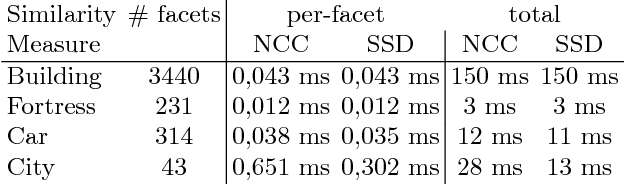
Mesh refinement is a fundamental step for accurate Multi-View Stereo. It modifies the geometry of an initial manifold mesh to minimize the photometric error induced in a set of camera pairs. This initial mesh is usually the output of volumetric 3D reconstruction based on min-cut over Delaunay Triangulations. Such methods produce a significant amount of non-manifold vertices, therefore they require a vertex split step to explicitly repair them. In this paper, we extend this method to preemptively fix the non-manifold vertices by reasoning directly on the Delaunay Triangulation and avoid most vertex splits. The main contribution of this paper addresses the problem of choosing the camera pairs adopted by the refinement process. We treat the problem as a mesh labeling process, where each label corresponds to a camera pair. Differently from the state-of-the-art methods, which use each camera pair to refine all the visible parts of the mesh, we choose, for each facet, the best pair that enforces both the overall visibility and coverage. The refinement step is applied for each facet using only the camera pair selected. This facetwise refinement helps the process to be applied in the most evenly way possible.
Matrix-LSTM: a Differentiable Recurrent Surface for Asynchronous Event-Based Data
Jan 10, 2020
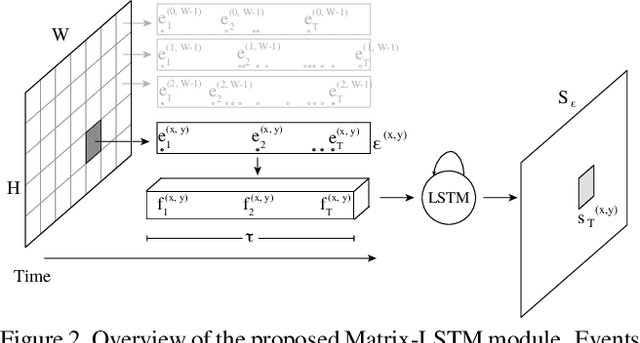

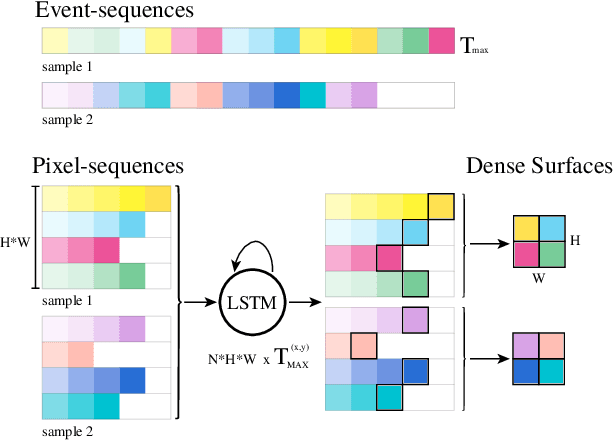
Dynamic Vision Sensors (DVSs) asynchronously stream events in correspondence of pixels subject to brightness changes. Differently from classic vision devices, they produce a sparse representation of the scene. Therefore, to apply standard computer vision algorithms, events need to be integrated into a frame or event-surface. This is usually attained through hand-crafted grids that reconstruct the frame using ad-hoc heuristics. In this paper, we propose Matrix-LSTM, a grid of Long Short-Term Memory (LSTM) cells to learn end-to-end a task-dependent event-surfaces. Compared to existing reconstruction approaches, our learned event-surface shows good flexibility and expressiveness improving the baselines on optical flow estimation on the MVSEC benchmark and the state-of-the-art of event-based object classification on the N-Cars dataset.
Mesh-based Camera Pairs Selection and Occlusion-Aware Masking for Mesh Refinement
May 21, 2019
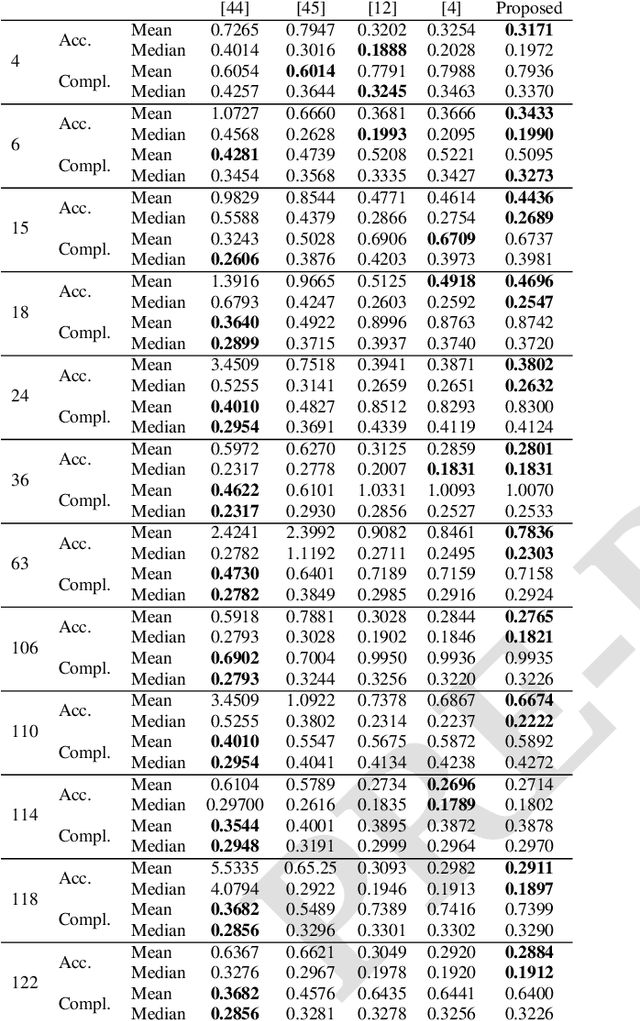
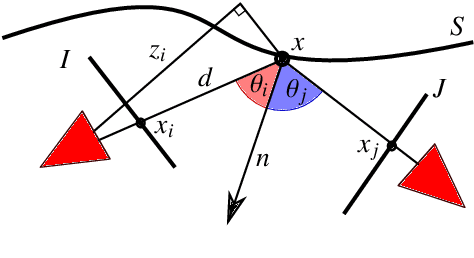

Many Multi-View-Stereo algorithms extract a 3D mesh model of a scene, after fusing depth maps into a volumetric representation of the space. Due to the limited scalability of such representations, the estimated model does not capture fine details of the scene. Therefore a mesh refinement algorithm is usually applied; it improves the mesh resolution and accuracy by minimizing the photometric error induced by the 3D model into pairs of cameras. The choice of these pairs significantly affects the quality of the refinement and usually relies on sparse 3D points belonging to the surface. Instead, in this paper, to increase the quality of pairs selection, we exploit the 3D model (before the refinement) to compute five metrics: scene coverage, mutual image overlap, image resolution, camera parallax, and a new symmetry term. To improve the refinement robustness, we also propose an explicit method to manage occlusions, which may negatively affect the computation of the photometric error. The proposed method takes into account the depth of the model while computing the similarity measure and its gradient. We quantitatively and qualitatively validated our approach on publicly available datasets against state of the art reconstruction methods.
TAPA-MVS: Textureless-Aware PAtchMatch Multi-View Stereo
Mar 26, 2019
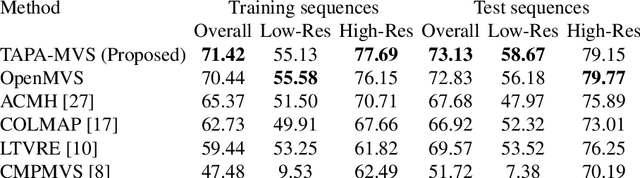

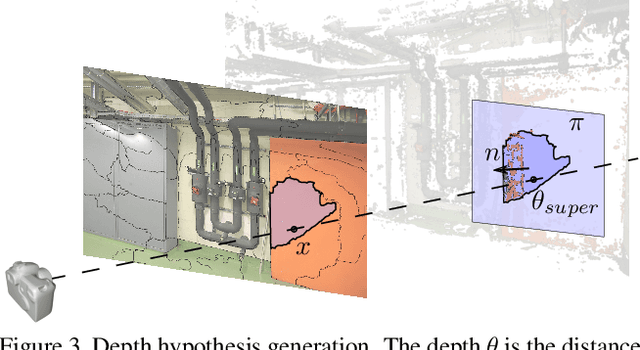
One of the most successful approaches in Multi-View Stereo estimates a depth map and a normal map for each view via PatchMatch-based optimization and fuses them into a consistent 3D points cloud. This approach relies on photo-consistency to evaluate the goodness of a depth estimate. It generally produces very accurate results; however, the reconstructed model often lacks completeness, especially in correspondence of broad untextured areas where the photo-consistency metrics are unreliable. Assuming the untextured areas piecewise planar, in this paper we generate novel PatchMatch hypotheses so to expand reliable depth estimates in neighboring untextured regions. At the same time, we modify the photo-consistency measure such to favor standard or novel PatchMatch depth hypotheses depending on the textureness of the considered area. We also propose a depth refinement step to filter wrong estimates and to fill the gaps on both the depth maps and normal maps while preserving the discontinuities. The effectiveness of our new methods has been tested against several state of the art algorithms in the publicly available ETH3D dataset containing a wide variety of high and low-resolution images.
Dense 3D Visual Mapping via Semantic Simplification
Feb 20, 2019

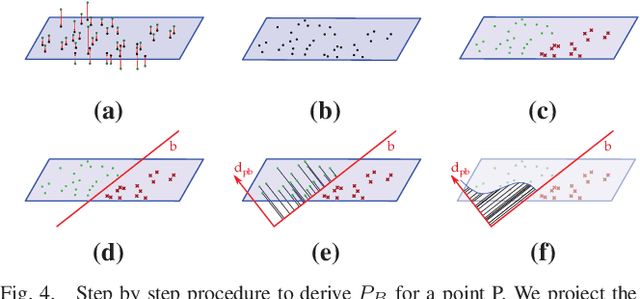
Dense 3D visual mapping estimates as many as possible pixel depths, for each image. This results in very dense point clouds that often contain redundant and noisy information, especially for surfaces that are roughly planar, for instance, the ground or the walls in the scene. In this paper we leverage on semantic image segmentation to discriminate which regions of the scene require simplification and which should be kept at high level of details. We propose four different point cloud simplification methods which decimate the perceived point cloud by relying on class-specific local and global statistics still maintaining more points in the proximity of class boundaries to preserve the infra-class edges and discontinuities. 3D dense model is obtained by fusing the point clouds in a 3D Delaunay Triangulation to deal with variable point cloud density. In the experimental evaluation we have shown that, by leveraging on semantics, it is possible to simplify the model and diminish the noise affecting the point clouds.
A Data-driven Prior on Facet Orientation for Semantic Mesh Labeling
Jul 26, 2018



Mesh labeling is the key problem of classifying the facets of a 3D mesh with a label among a set of possible ones. State-of-the-art methods model mesh labeling as a Markov Random Field over the facets. These algorithms map image segmentations to the mesh by minimizing an energy function that comprises a data term, a smoothness terms, and class-specific priors. The latter favor a labeling with respect to another depending on the orientation of the facet normals. In this paper we propose a novel energy term that acts as a prior, but does not require any prior knowledge about the scene nor scene-specific relationship among classes. It bootstraps from a coarse mapping of the 2D segmentations on the mesh, and it favors the facets to be labeled according to the statistics of the mesh normals in their neighborhood. We tested our approach against five different datasets and, even if we do not inject prior knowledge, our method adapts to the data and overcomes the state-of-the-art.
Attention Mechanisms for Object Recognition with Event-Based Cameras
Jul 25, 2018
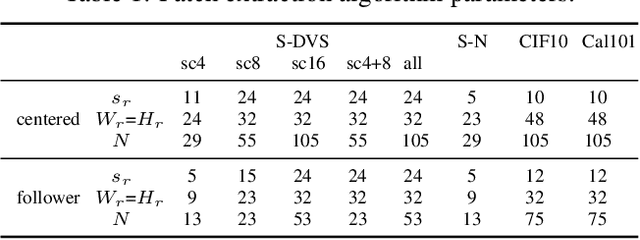

Event-based cameras are neuromorphic sensors capable of efficiently encoding visual information in the form of sparse sequences of events. Being biologically inspired, they are commonly used to exploit some of the computational and power consumption benefits of biological vision. In this paper we focus on a specific feature of vision: visual attention. We propose two attentive models for event based vision. An algorithm that tracks events activity within the field of view to locate regions of interest and a fully-differentiable attention procedure based on DRAW neural model. We highlight the strengths and weaknesses of the proposed methods on two datasets, the Shifted N-MNIST and Shifted MNIST-DVS collections, using the Phased LSTM recognition network as a baseline reference model obtaining improvements in terms of both translation and scale invariance.
Event-based Convolutional Networks for Object Detection in Neuromorphic Cameras
May 21, 2018
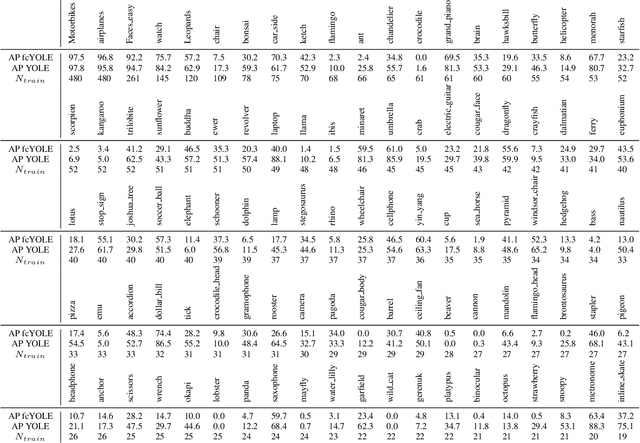

Event-based cameras are bioinspired sensors able to perceive changes in the scene at high frequency with a low power consumption. Becoming available only very recently, a limited amount of work addresses object detection on these devices. In this paper we propose two neural networks architectures for object detection: YOLE, which integrates the events into frames and uses a frame-based model to process them, eFCN, a event-based fully convolutional network that uses a novel and general formalization of the convolutional and max pooling layers to exploit the sparsity of the camera events. We evaluated the algorithm with different extension of publicly available dataset, and on a novel custom dataset.
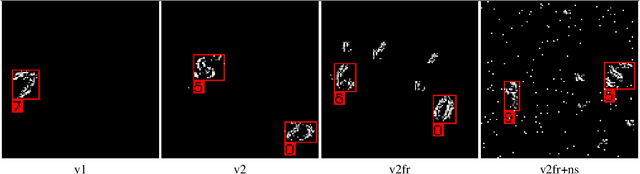
Predicting the Next Best View for 3D Mesh Refinement
May 16, 2018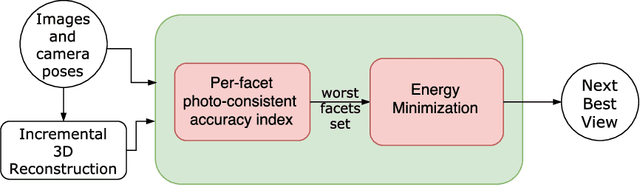

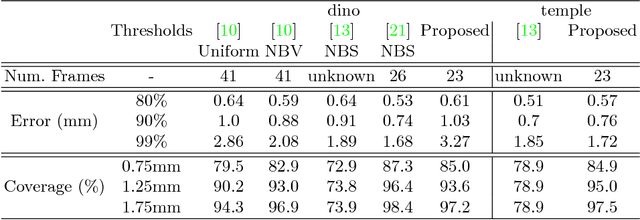
3D reconstruction is a core task in many applications such as robot navigation or sites inspections. Finding the best poses to capture part of the scene is one of the most challenging topic that goes under the name of Next Best View. Recently, many volumetric methods have been proposed; they choose the Next Best View by reasoning over a 3D voxelized space and by finding which pose minimizes the uncertainty decoded into the voxels. Such methods are effective, but they do not scale well since the underlaying representation requires a huge amount of memory. In this paper we propose a novel mesh-based approach which focuses on the worst reconstructed region of the environment mesh. We define a photo-consistent index to evaluate the 3D mesh accuracy, and an energy function over the worst regions of the mesh which takes into account the mutual parallax with respect to the previous cameras, the angle of incidence of the viewing ray to the surface and the visibility of the region. We test our approach over a well known dataset and achieve state-of-the-art results.