 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Imitation Learning for Event-based Quadrotor Flight in Cluttered Environments
Mar 08, 2026Event cameras offer high temporal resolution and low latency, making them ideal sensors for high-speed robotic applications where conventional cameras suffer from image degradations such as motion blur. In addition, their low power consumption can enhance endurance, which is critical for resource-constrained platforms. Motivated by these properties, we present a novel approach that enables a quadrotor to fly through cluttered environments at high speed by perceiving the environment with a single event camera. Our proposed method employs an end-to-end neural network trained to map event data directly to control commands, eliminating the reliance on standard cameras. To enable efficient training in simulation, where rendering synthetic event data is computationally expensive, we propose Approximate Imitation Learning, a novel imitation learning framework. Our approach leverages a large-scale offline dataset to learn a task-specific representation space. Subsequently, the policy is trained through online interactions that rely solely on lightweight, simulated state information, eliminating the need to render events during training. This enables the efficient training of event-based control policies for fast quadrotor flight, highlighting the potential of our framework for other modalities where data simulation is costly or impractical. Our approach outperforms standard imitation learning baselines in simulation and demonstrates robust performance in real-world flight tests, achieving speeds up to 9.8 ms-1 in cluttered environments.
Event-Aided Sharp Radiance Field Reconstruction for Fast-Flying Drones
Feb 26, 2026Fast-flying aerial robots promise rapid inspection under limited battery constraints, with direct applications in infrastructure inspection, terrain exploration, and search and rescue. However, high speeds lead to severe motion blur in images and induce significant drift and noise in pose estimates, making dense 3D reconstruction with Neural Radiance Fields (NeRFs) particularly challenging due to their high sensitivity to such degradations. In this work, we present a unified framework that leverages asynchronous event streams alongside motion-blurred frames to reconstruct high-fidelity radiance fields from agile drone flights. By embedding event-image fusion into NeRF optimization and jointly refining event-based visual-inertial odometry priors using both event and frame modalities, our method recovers sharp radiance fields and accurate camera trajectories without ground-truth supervision. We validate our approach on both synthetic data and real-world sequences captured by a fast-flying drone. Despite highly dynamic drone flights, where RGB frames are severely degraded by motion blur and pose priors become unreliable, our method reconstructs high-fidelity radiance fields and preserves fine scene details, delivering a performance gain of over 50% on real-world data compared to state-of-the-art methods.
Motion-aware Event Suppression for Event Cameras
Feb 26, 2026In this work, we introduce the first framework for Motion-aware Event Suppression, which learns to filter events triggered by IMOs and ego-motion in real time. Our model jointly segments IMOs in the current event stream while predicting their future motion, enabling anticipatory suppression of dynamic events before they occur. Our lightweight architecture achieves 173 Hz inference on consumer-grade GPUs with less than 1 GB of memory usage, outperforming previous state-of-the-art methods on the challenging EVIMO benchmark by 67\% in segmentation accuracy while operating at a 53\% higher inference rate. Moreover, we demonstrate significant benefits for downstream applications: our method accelerates Vision Transformer inference by 83\% via token pruning and improves event-based visual odometry accuracy, reducing Absolute Trajectory Error (ATE) by 13\%.
Egocentric Event-Based Vision for Ping Pong Ball Trajectory Prediction
Jun 09, 2025
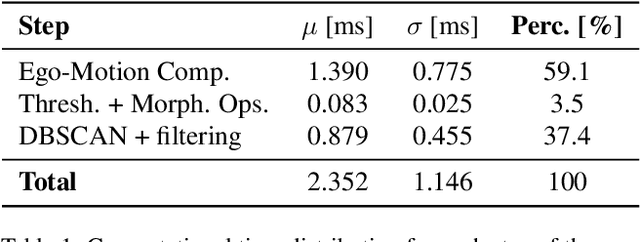


In this paper, we present a real-time egocentric trajectory prediction system for table tennis using event cameras. Unlike standard cameras, which suffer from high latency and motion blur at fast ball speeds, event cameras provide higher temporal resolution, allowing more frequent state updates, greater robustness to outliers, and accurate trajectory predictions using just a short time window after the opponent's impact. We collect a dataset of ping-pong game sequences, including 3D ground-truth trajectories of the ball, synchronized with sensor data from the Meta Project Aria glasses and event streams. Our system leverages foveated vision, using eye-gaze data from the glasses to process only events in the viewer's fovea. This biologically inspired approach improves ball detection performance and significantly reduces computational latency, as it efficiently allocates resources to the most perceptually relevant regions, achieving a reduction factor of 10.81 on the collected trajectories. Our detection pipeline has a worst-case total latency of 4.5 ms, including computation and perception - significantly lower than a frame-based 30 FPS system, which, in the worst case, takes 66 ms solely for perception. Finally, we fit a trajectory prediction model to the estimated states of the ball, enabling 3D trajectory forecasting in the future. To the best of our knowledge, this is the first approach to predict table tennis trajectories from an egocentric perspective using event cameras.
Perturbed State Space Feature Encoders for Optical Flow with Event Cameras
Apr 14, 2025With their motion-responsive nature, event-based cameras offer significant advantages over traditional cameras for optical flow estimation. While deep learning has improved upon traditional methods, current neural networks adopted for event-based optical flow still face temporal and spatial reasoning limitations. We propose Perturbed State Space Feature Encoders (P-SSE) for multi-frame optical flow with event cameras to address these challenges. P-SSE adaptively processes spatiotemporal features with a large receptive field akin to Transformer-based methods, while maintaining the linear computational complexity characteristic of SSMs. However, the key innovation that enables the state-of-the-art performance of our model lies in our perturbation technique applied to the state dynamics matrix governing the SSM system. This approach significantly improves the stability and performance of our model. We integrate P-SSE into a framework that leverages bi-directional flows and recurrent connections, expanding the temporal context of flow prediction. Evaluations on DSEC-Flow and MVSEC datasets showcase P-SSE's superiority, with 8.48% and 11.86% improvements in EPE performance, respectively.
* 10 pages, 4 figures, 4 tables. Equal contribution by Gokul Raju Govinda Raju and Nikola Zubi\'c
LiDAR Registration with Visual Foundation Models
Feb 26, 2025LiDAR registration is a fundamental task in robotic mapping and localization. A critical component of aligning two point clouds is identifying robust point correspondences using point descriptors. This step becomes particularly challenging in scenarios involving domain shifts, seasonal changes, and variations in point cloud structures. These factors substantially impact both handcrafted and learning-based approaches. In this paper, we address these problems by proposing to use DINOv2 features, obtained from surround-view images, as point descriptors. We demonstrate that coupling these descriptors with traditional registration algorithms, such as RANSAC or ICP, facilitates robust 6DoF alignment of LiDAR scans with 3D maps, even when the map was recorded more than a year before. Although conceptually straightforward, our method substantially outperforms more complex baseline techniques. In contrast to previous learning-based point descriptors, our method does not require domain-specific retraining and is agnostic to the point cloud structure, effectively handling both sparse LiDAR scans and dense 3D maps. We show that leveraging the additional camera data enables our method to outperform the best baseline by +24.8 and +17.3 registration recall on the NCLT and Oxford RobotCar datasets. We publicly release the registration benchmark and the code of our work on https://vfm-registration.cs.uni-freiburg.de.
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
Dec 15, 2024



We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego-trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, ego-trajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations. Code, models, and datasets are fully open-sourced.
Monocular Event-Based Vision for Obstacle Avoidance with a Quadrotor
Nov 05, 2024

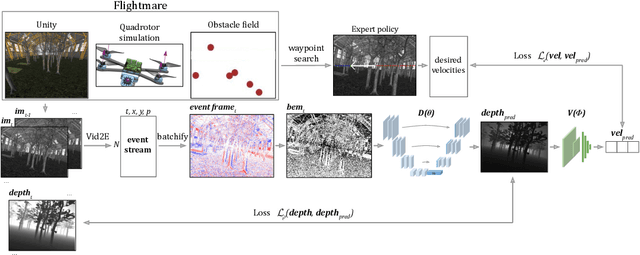
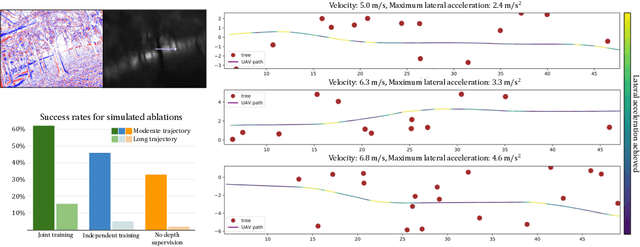
We present the first static-obstacle avoidance method for quadrotors using just an onboard, monocular event camera. Quadrotors are capable of fast and agile flight in cluttered environments when piloted manually, but vision-based autonomous flight in unknown environments is difficult in part due to the sensor limitations of traditional onboard cameras. Event cameras, however, promise nearly zero motion blur and high dynamic range, but produce a very large volume of events under significant ego-motion and further lack a continuous-time sensor model in simulation, making direct sim-to-real transfer not possible. By leveraging depth prediction as a pretext task in our learning framework, we can pre-train a reactive obstacle avoidance events-to-control policy with approximated, simulated events and then fine-tune the perception component with limited events-and-depth real-world data to achieve obstacle avoidance in indoor and outdoor settings. We demonstrate this across two quadrotor-event camera platforms in multiple settings and find, contrary to traditional vision-based works, that low speeds (1m/s) make the task harder and more prone to collisions, while high speeds (5m/s) result in better event-based depth estimation and avoidance. We also find that success rates in outdoor scenes can be significantly higher than in certain indoor scenes.
* 18 pages with supplementary
FaVoR: Features via Voxel Rendering for Camera Relocalization
Sep 11, 2024



Camera relocalization methods range from dense image alignment to direct camera pose regression from a query image. Among these, sparse feature matching stands out as an efficient, versatile, and generally lightweight approach with numerous applications. However, feature-based methods often struggle with significant viewpoint and appearance changes, leading to matching failures and inaccurate pose estimates. To overcome this limitation, we propose a novel approach that leverages a globally sparse yet locally dense 3D representation of 2D features. By tracking and triangulating landmarks over a sequence of frames, we construct a sparse voxel map optimized to render image patch descriptors observed during tracking. Given an initial pose estimate, we first synthesize descriptors from the voxels using volumetric rendering and then perform feature matching to estimate the camera pose. This methodology enables the generation of descriptors for unseen views, enhancing robustness to view changes. We extensively evaluate our method on the 7-Scenes and Cambridge Landmarks datasets. Our results show that our method significantly outperforms existing state-of-the-art feature representation techniques in indoor environments, achieving up to a 39% improvement in median translation error. Additionally, our approach yields comparable results to other methods for outdoor scenarios while maintaining lower memory and computational costs.
Mitigating Motion Blur in Neural Radiance Fields with Events and Frames
Mar 28, 2024
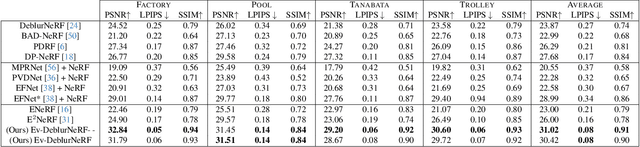
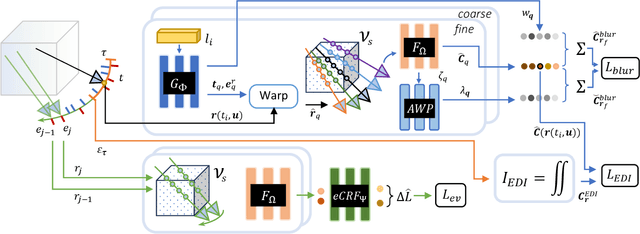

Neural Radiance Fields (NeRFs) have shown great potential in novel view synthesis. However, they struggle to render sharp images when the data used for training is affected by motion blur. On the other hand, event cameras excel in dynamic scenes as they measure brightness changes with microsecond resolution and are thus only marginally affected by blur. Recent methods attempt to enhance NeRF reconstructions under camera motion by fusing frames and events. However, they face challenges in recovering accurate color content or constrain the NeRF to a set of predefined camera poses, harming reconstruction quality in challenging conditions. This paper proposes a novel formulation addressing these issues by leveraging both model- and learning-based modules. We explicitly model the blur formation process, exploiting the event double integral as an additional model-based prior. Additionally, we model the event-pixel response using an end-to-end learnable response function, allowing our method to adapt to non-idealities in the real event-camera sensor. We show, on synthetic and real data, that the proposed approach outperforms existing deblur NeRFs that use only frames as well as those that combine frames and events by +6.13dB and +2.48dB, respectively.