 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAD: Motion Appearance Decoupling for efficient Driving World Models
Jan 14, 2026Recent video diffusion models generate photorealistic, temporally coherent videos, yet they fall short as reliable world models for autonomous driving, where structured motion and physically consistent interactions are essential. Adapting these generalist video models to driving domains has shown promise but typically requires massive domain-specific data and costly fine-tuning. We propose an efficient adaptation framework that converts generalist video diffusion models into controllable driving world models with minimal supervision. The key idea is to decouple motion learning from appearance synthesis. First, the model is adapted to predict structured motion in a simplified form: videos of skeletonized agents and scene elements, focusing learning on physical and social plausibility. Then, the same backbone is reused to synthesize realistic RGB videos conditioned on these motion sequences, effectively "dressing" the motion with texture and lighting. This two-stage process mirrors a reasoning-rendering paradigm: first infer dynamics, then render appearance. Our experiments show this decoupled approach is exceptionally efficient: adapting SVD, we match prior SOTA models with less than 6% of their compute. Scaling to LTX, our MAD-LTX model outperforms all open-source competitors, and supports a comprehensive suite of text, ego, and object controls. Project page: https://vita-epfl.github.io/MAD-World-Model/
From Generation to Generalization: Emergent Few-Shot Learning in Video Diffusion Models
Jun 08, 2025Video Diffusion Models (VDMs) have emerged as powerful generative tools, capable of synthesizing high-quality spatiotemporal content. Yet, their potential goes far beyond mere video generation. We argue that the training dynamics of VDMs, driven by the need to model coherent sequences, naturally pushes them to internalize structured representations and an implicit understanding of the visual world. To probe the extent of this internal knowledge, we introduce a few-shot fine-tuning framework that repurposes VDMs for new tasks using only a handful of examples. Our method transforms each task into a visual transition, enabling the training of LoRA weights on short input-output sequences without altering the generative interface of a frozen VDM. Despite minimal supervision, the model exhibits strong generalization across diverse tasks, from low-level vision (for example, segmentation and pose estimation) to high-level reasoning (for example, on ARC-AGI). These results reframe VDMs as more than generative engines. They are adaptable visual learners with the potential to serve as the backbone for future foundation models in vision.
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
Dec 15, 2024



We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego-trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, ego-trajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations. Code, models, and datasets are fully open-sourced.
A Multi-Loss Strategy for Vehicle Trajectory Prediction: Combining Off-Road, Diversity, and Directional Consistency Losses
Nov 29, 2024Trajectory prediction is essential for the safety and efficiency of planning in autonomous vehicles. However, current models often fail to fully capture complex traffic rules and the complete range of potential vehicle movements. Addressing these limitations, this study introduces three novel loss functions: Offroad Loss, Direction Consistency Error, and Diversity Loss. These functions are designed to keep predicted paths within driving area boundaries, aligned with traffic directions, and cover a wider variety of plausible driving scenarios. As all prediction modes should adhere to road rules and conditions, this work overcomes the shortcomings of traditional "winner takes all" training methods by applying the loss functions to all prediction modes. These loss functions not only improve model training but can also serve as metrics for evaluating the realism and diversity of trajectory predictions. Extensive validation on the nuScenes and Argoverse 2 datasets with leading baseline models demonstrates that our approach not only maintains accuracy but significantly improves safety and robustness, reducing offroad errors on average by 47% on original and by 37% on attacked scenes. This work sets a new benchmark for trajectory prediction in autonomous driving, offering substantial improvements in navigating complex environments. Our code is available at https://github.com/vita-epfl/stay-on-track .
Sim-to-Real Causal Transfer: A Metric Learning Approach to Causally-Aware Interaction Representations
Dec 07, 2023Modeling spatial-temporal interactions among neighboring agents is at the heart of multi-agent problems such as motion forecasting and crowd navigation. Despite notable progress, it remains unclear to which extent modern representations can capture the causal relationships behind agent interactions. In this work, we take an in-depth look at the causal awareness of these representations, from computational formalism to real-world practice. First, we cast doubt on the notion of non-causal robustness studied in the recent CausalAgents benchmark. We show that recent representations are already partially resilient to perturbations of non-causal agents, and yet modeling indirect causal effects involving mediator agents remains challenging. To address this challenge, we introduce a metric learning approach that regularizes latent representations with causal annotations. Our controlled experiments show that this approach not only leads to higher degrees of causal awareness but also yields stronger out-of-distribution robustness. To further operationalize it in practice, we propose a sim-to-real causal transfer method via cross-domain multi-task learning. Experiments on pedestrian datasets show that our method can substantially boost generalization, even in the absence of real-world causal annotations. We hope our work provides a new perspective on the challenges and potential pathways towards causally-aware representations of multi-agent interactions. Our code is available at https://github.com/socialcausality.
Vehicle trajectory prediction works, but not everywhere
Dec 07, 2021

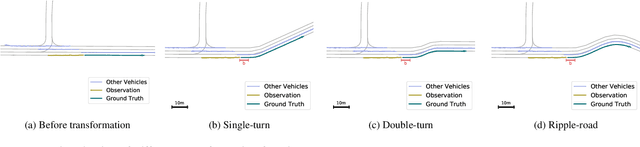

Vehicle trajectory prediction is nowadays a fundamental pillar of self-driving cars. Both the industry and research communities have acknowledged the need for such a pillar by running public benchmarks. While state-of-the-art methods are impressive, i.e., they have no off-road prediction, their generalization to cities outside of the benchmark is unknown. In this work, we show that those methods do not generalize to new scenes. We present a novel method that automatically generates realistic scenes that cause state-of-the-art models go off-road. We frame the problem through the lens of adversarial scene generation. We promote a simple yet effective generative model based on atomic scene generation functions along with physical constraints. Our experiments show that more than $60\%$ of the existing scenes from the current benchmarks can be modified in a way to make prediction methods fail (predicting off-road). We further show that (i) the generated scenes are realistic since they do exist in the real world, and (ii) can be used to make existing models robust by 30-40%. Code is available at https://s-attack.github.io/.