 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLM-Generated Obfuscated XSS Payloads for Machine Learning-Based Detection
Apr 21, 2026Cross-site scripting (XSS) remains a persistent web security vulnerability, especially because obfuscation can change the surface form of a malicious payload while preserving its behavior. These transformations make it difficult for traditional and machine learning-based detection systems to reliably identify attacks. Existing approaches for generating obfuscated payloads often emphasize syntactic diversity, but they do not always ensure that the generated samples remain behaviorally valid. This paper presents a structured pipeline for generating and evaluating obfuscated XSS payloads using large language models (LLMs). The pipeline combines deterministic transformation techniques with LLM-based generation and uses a browser- based runtime evaluation procedure to compare payload behavior in a controlled execution environment. This allows generated samples to be assessed through observable runtime behavior rather than syntactic similarity alone. In the evaluation, an untuned baseline language model achieves a runtime behavior match rate of 0.15, while fine-tuning on behavior-preserving source-target obfuscation pairs improves the match rate to 0.22. Although this represents a measurable improvement, the results show that current LLMs still struggle to generate obfuscations that preserve observed runtime behavior. A downstream classifier evaluation further shows that adding generated payloads does not improve detection performance in this setting, although behavior- filtered generated samples can be incorporated without materially degrading performance. Overall, the study demonstrates both the promise and the limits of applying generative models to adversarial security data generation and emphasizes the importance of runtime behavior checks in improving the quality of generated data for downstream detection systems.
Rule-Based Approaches to Atomic Sentence Extraction
Jan 01, 2026Natural language often combines multiple ideas into complex sentences. Atomic sentence extraction, the task of decomposing complex sentences into simpler sentences that each express a single idea, improves performance in information retrieval, question answering, and automated reasoning systems. Previous work has formalized the "split-and-rephrase" task and established evaluation metrics, and machine learning approaches using large language models have improved extraction accuracy. However, these methods lack interpretability and provide limited insight into which linguistic structures cause extraction failures. Although some studies have explored dependency-based extraction of subject-verb-object triples and clauses, no principled analysis has examined which specific clause structures and dependencies lead to extraction difficulties. This study addresses this gap by analyzing how complex sentence structures, including relative clauses, adverbial clauses, coordination patterns, and passive constructions, affect the performance of rule-based atomic sentence extraction. Using the WikiSplit dataset, we implemented dependency-based extraction rules in spaCy, generated 100 gold=standard atomic sentence sets, and evaluated performance using ROUGE and BERTScore. The system achieved ROUGE-1 F1 = 0.6714, ROUGE-2 F1 = 0.478, ROUGE-L F1 = 0.650, and BERTScore F1 = 0.5898, indicating moderate-to-high lexical, structural, and semantic alignment. Challenging structures included relative clauses, appositions, coordinated predicates, adverbial clauses, and passive constructions. Overall, rule-based extraction is reasonably accurate but sensitive to syntactic complexity.
Improving LLM-Assisted Secure Code Generation through Retrieval-Augmented-Generation and Multi-Tool Feedback
Jan 01, 2026Large Language Models (LLMs) can generate code but often introduce security vulnerabilities, logical inconsistencies, and compilation errors. Prior work demonstrates that LLMs benefit substantially from structured feedback, static analysis, retrieval augmentation, and execution-based refinement. We propose a retrieval-augmented, multi-tool repair workflow in which a single code-generating LLM iteratively refines its outputs using compiler diagnostics, CodeQL security scanning, and KLEE symbolic execution. A lightweight embedding model is used for semantic retrieval of previously successful repairs, providing security-focused examples that guide generation. Evaluated on a combined dataset of 3,242 programs generated by DeepSeek-Coder-1.3B and CodeLlama-7B, the system demonstrates significant improvements in robustness. For DeepSeek, security vulnerabilities were reduced by 96%. For the larger CodeLlama model, the critical security defect rate was decreased from 58.55% to 22.19%, highlighting the efficacy of tool-assisted self-repair even on "stubborn" models.
Leveraging LLM to Strengthen ML-Based Cross-Site Scripting Detection
Apr 28, 2025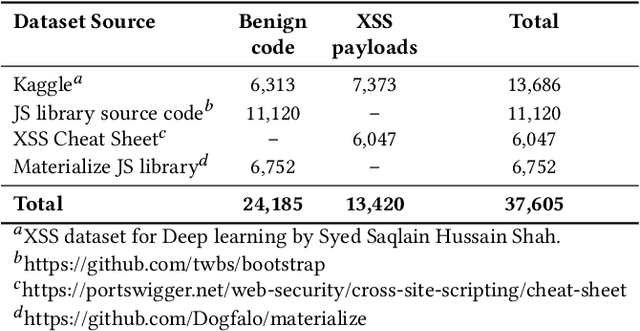

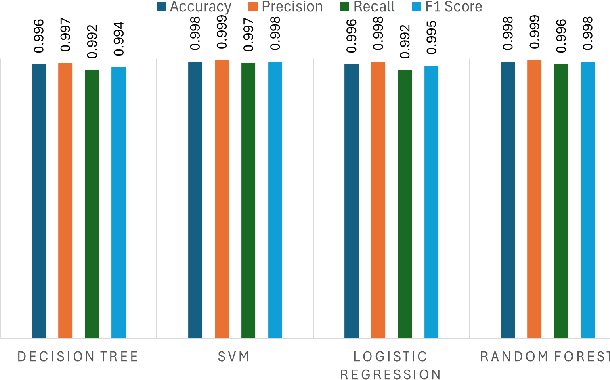

According to the Open Web Application Security Project (OWASP), Cross-Site Scripting (XSS) is a critical security vulnerability. Despite decades of research, XSS remains among the top 10 security vulnerabilities. Researchers have proposed various techniques to protect systems from XSS attacks, with machine learning (ML) being one of the most widely used methods. An ML model is trained on a dataset to identify potential XSS threats, making its effectiveness highly dependent on the size and diversity of the training data. A variation of XSS is obfuscated XSS, where attackers apply obfuscation techniques to alter the code's structure, making it challenging for security systems to detect its malicious intent. Our study's random forest model was trained on traditional (non-obfuscated) XSS data achieved 99.8% accuracy. However, when tested against obfuscated XSS samples, accuracy dropped to 81.9%, underscoring the importance of training ML models with obfuscated data to improve their effectiveness in detecting XSS attacks. A significant challenge is to generate highly complex obfuscated code despite the availability of several public tools. These tools can only produce obfuscation up to certain levels of complexity. In our proposed system, we fine-tune a Large Language Model (LLM) to generate complex obfuscated XSS payloads automatically. By transforming original XSS samples into diverse obfuscated variants, we create challenging training data for ML model evaluation. Our approach achieved a 99.5% accuracy rate with the obfuscated dataset. We also found that the obfuscated samples generated by the LLMs were 28.1% more complex than those created by other tools, significantly improving the model's ability to handle advanced XSS attacks and making it more effective for real-world application security.
GEM: A Generalizable Ego-Vision Multimodal World Model for Fine-Grained Ego-Motion, Object Dynamics, and Scene Composition Control
Dec 15, 2024



We present GEM, a Generalizable Ego-vision Multimodal world model that predicts future frames using a reference frame, sparse features, human poses, and ego-trajectories. Hence, our model has precise control over object dynamics, ego-agent motion and human poses. GEM generates paired RGB and depth outputs for richer spatial understanding. We introduce autoregressive noise schedules to enable stable long-horizon generations. Our dataset is comprised of 4000+ hours of multimodal data across domains like autonomous driving, egocentric human activities, and drone flights. Pseudo-labels are used to get depth maps, ego-trajectories, and human poses. We use a comprehensive evaluation framework, including a new Control of Object Manipulation (COM) metric, to assess controllability. Experiments show GEM excels at generating diverse, controllable scenarios and temporal consistency over long generations. Code, models, and datasets are fully open-sourced.
Language-Guided Instance-Aware Domain-Adaptive Panoptic Segmentation
Apr 04, 2024
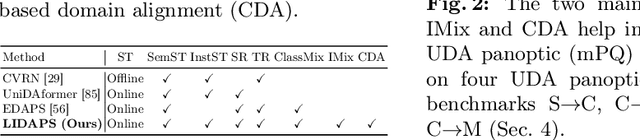
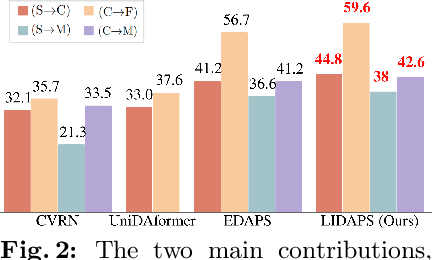
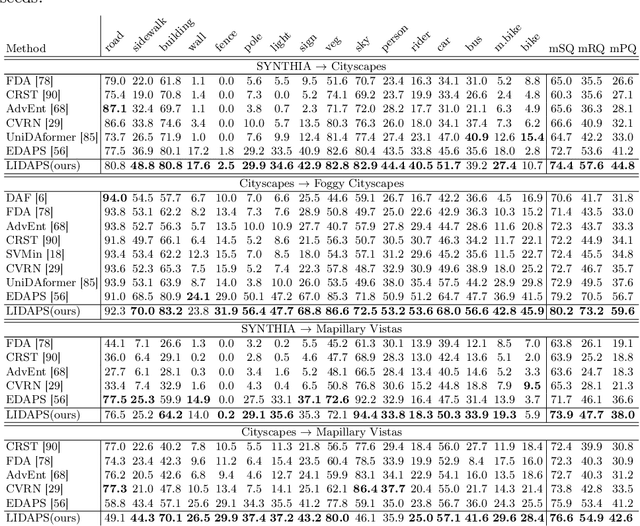
The increasing relevance of panoptic segmentation is tied to the advancements in autonomous driving and AR/VR applications. However, the deployment of such models has been limited due to the expensive nature of dense data annotation, giving rise to unsupervised domain adaptation (UDA). A key challenge in panoptic UDA is reducing the domain gap between a labeled source and an unlabeled target domain while harmonizing the subtasks of semantic and instance segmentation to limit catastrophic interference. While considerable progress has been achieved, existing approaches mainly focus on the adaptation of semantic segmentation. In this work, we focus on incorporating instance-level adaptation via a novel instance-aware cross-domain mixing strategy IMix. IMix significantly enhances the panoptic quality by improving instance segmentation performance. Specifically, we propose inserting high-confidence predicted instances from the target domain onto source images, retaining the exhaustiveness of the resulting pseudo-labels while reducing the injected confirmation bias. Nevertheless, such an enhancement comes at the cost of degraded semantic performance, attributed to catastrophic forgetting. To mitigate this issue, we regularize our semantic branch by employing CLIP-based domain alignment (CDA), exploiting the domain-robustness of natural language prompts. Finally, we present an end-to-end model incorporating these two mechanisms called LIDAPS, achieving state-of-the-art results on all popular panoptic UDA benchmarks.
Three Ways to Improve Verbo-visual Fusion for Dense 3D Visual Grounding
Sep 08, 20233D visual grounding is the task of localizing the object in a 3D scene which is referred by a description in natural language. With a wide range of applications ranging from autonomous indoor robotics to AR/VR, the task has recently risen in popularity. A common formulation to tackle 3D visual grounding is grounding-by-detection, where localization is done via bounding boxes. However, for real-life applications that require physical interactions, a bounding box insufficiently describes the geometry of an object. We therefore tackle the problem of dense 3D visual grounding, i.e. referral-based 3D instance segmentation. We propose a dense 3D grounding network ConcreteNet, featuring three novel stand-alone modules which aim to improve grounding performance for challenging repetitive instances, i.e. instances with distractors of the same semantic class. First, we introduce a bottom-up attentive fusion module that aims to disambiguate inter-instance relational cues, next we construct a contrastive training scheme to induce separation in the latent space, and finally we resolve view-dependent utterances via a learned global camera token. ConcreteNet ranks 1st on the challenging ScanRefer online benchmark by a considerable +9.43% accuracy at 50% IoU and has won the ICCV 3rd Workshop on Language for 3D Scenes "3D Object Localization" challenge.
CS-Mixer: A Cross-Scale Vision MLP Model with Spatial-Channel Mixing
Aug 25, 2023

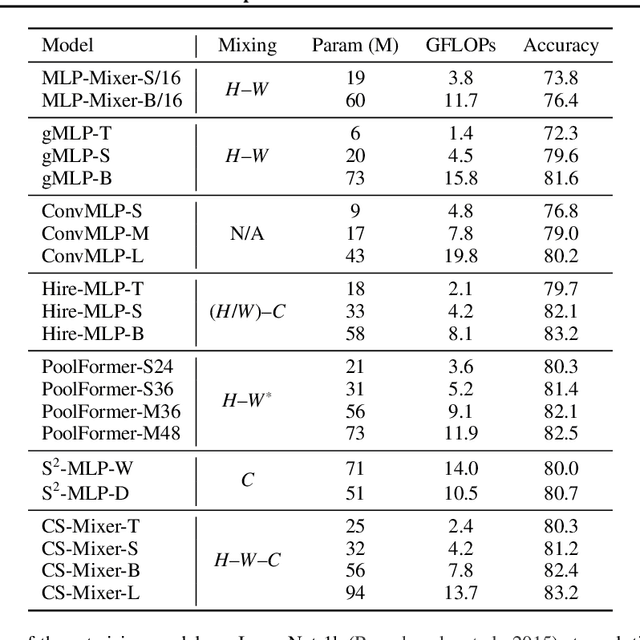
Despite their simpler information fusion designs compared with Vision Transformers and Convolutional Neural Networks, Vision MLP architectures have demonstrated strong performance and high data efficiency in recent research. However, existing works such as CycleMLP and Vision Permutator typically model spatial information in equal-size spatial regions and do not consider cross-scale spatial interactions. Further, their token mixers only model 1- or 2-axis correlations, avoiding 3-axis spatial-channel mixing due to its computational demands. We therefore propose CS-Mixer, a hierarchical Vision MLP that learns dynamic low-rank transformations for spatial-channel mixing through cross-scale local and global aggregation. The proposed methodology achieves competitive results on popular image recognition benchmarks without incurring substantially more compute. Our largest model, CS-Mixer-L, reaches 83.2% top-1 accuracy on ImageNet-1k with 13.7 GFLOPs and 94 M parameters.
EDAPS: Enhanced Domain-Adaptive Panoptic Segmentation
Apr 27, 2023



With autonomous industries on the rise, domain adaptation of the visual perception stack is an important research direction due to the cost savings promise. Much prior art was dedicated to domain-adaptive semantic segmentation in the synthetic-to-real context. Despite being a crucial output of the perception stack, panoptic segmentation has been largely overlooked by the domain adaptation community. Therefore, we revisit well-performing domain adaptation strategies from other fields, adapt them to panoptic segmentation, and show that they can effectively enhance panoptic domain adaptation. Further, we study the panoptic network design and propose a novel architecture (EDAPS) designed explicitly for domain-adaptive panoptic segmentation. It uses a shared, domain-robust transformer encoder to facilitate the joint adaptation of semantic and instance features, but task-specific decoders tailored for the specific requirements of both domain-adaptive semantic and instance segmentation. As a result, the performance gap seen in challenging panoptic benchmarks is substantially narrowed. EDAPS significantly improves the state-of-the-art performance for panoptic segmentation UDA by a large margin of 25% on SYNTHIA-to-Cityscapes and even 72% on the more challenging SYNTHIA-to-Mapillary Vistas. The implementation is available at https://github.com/susaha/edaps.
Exploiting Instance-based Mixed Sampling via Auxiliary Source Domain Supervision for Domain-adaptive Action Detection
Oct 06, 2022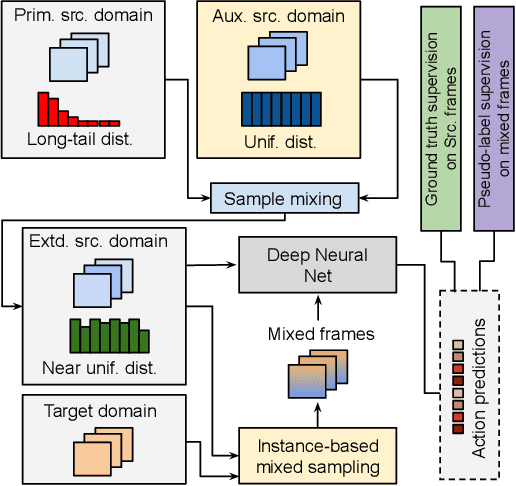
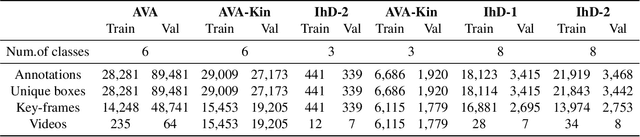
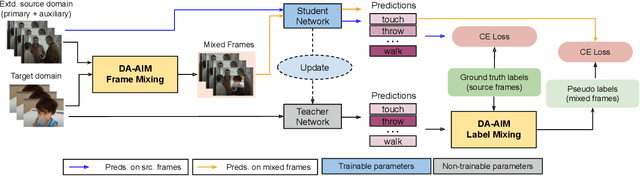
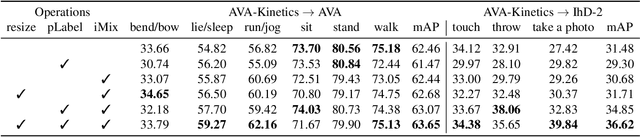
We propose a novel domain adaptive action detection approach and a new adaptation protocol that leverages the recent advancements in image-level unsupervised domain adaptation (UDA) techniques and handle vagaries of instance-level video data. Self-training combined with cross-domain mixed sampling has shown remarkable performance gain in semantic segmentation in UDA (unsupervised domain adaptation) context. Motivated by this fact, we propose an approach for human action detection in videos that transfers knowledge from the source domain (annotated dataset) to the target domain (unannotated dataset) using mixed sampling and pseudo-label-based selftraining. The existing UDA techniques follow a ClassMix algorithm for semantic segmentation. However, simply adopting ClassMix for action detection does not work, mainly because these are two entirely different problems, i.e., pixel-label classification vs. instance-label detection. To tackle this, we propose a novel action instance mixed sampling technique that combines information across domains based on action instances instead of action classes. Moreover, we propose a new UDA training protocol that addresses the long-tail sample distribution and domain shift problem by using supervision from an auxiliary source domain (ASD). For the ASD, we propose a new action detection dataset with dense frame-level annotations. We name our proposed framework as domain-adaptive action instance mixing (DA-AIM). We demonstrate that DA-AIM consistently outperforms prior works on challenging domain adaptation benchmarks. The source code is available at https://github.com/wwwfan628/DA-AIM.