 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical token pruning for foundation models in few-shot conversational virtual assistant systems
Aug 21, 2024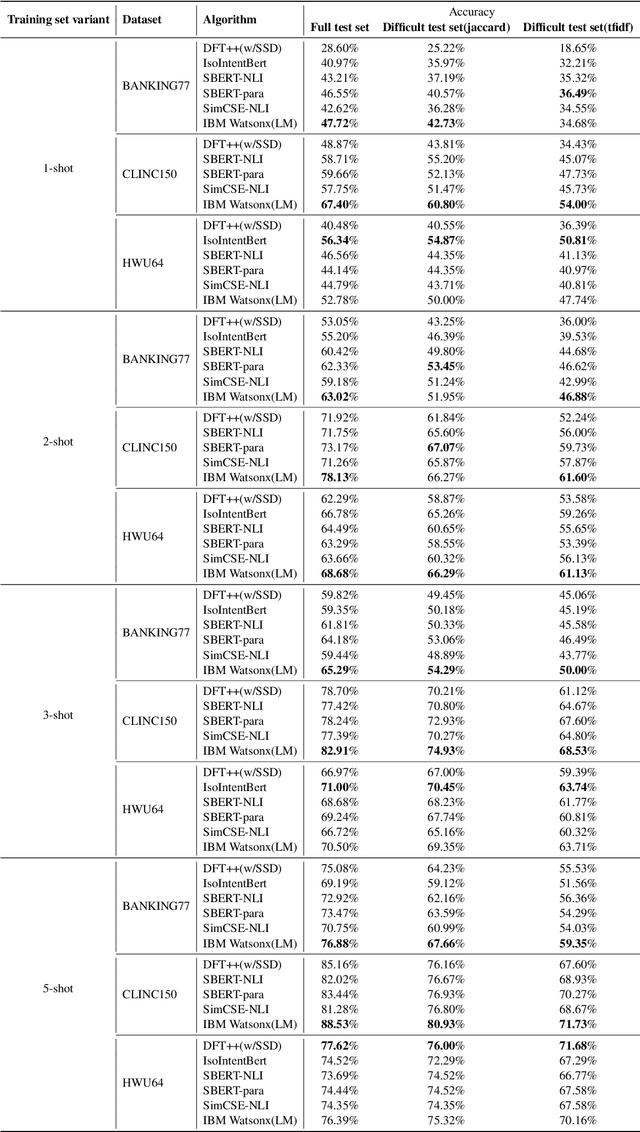
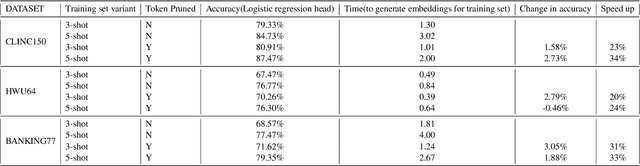
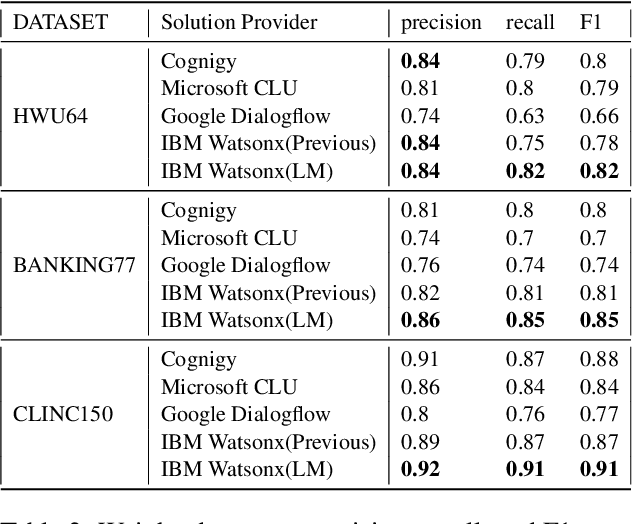
In an enterprise Virtual Assistant (VA) system, intent classification is the crucial component that determines how a user input is handled based on what the user wants. The VA system is expected to be a cost-efficient SaaS service with low training and inference time while achieving high accuracy even with a small number of training samples. We pretrain a transformer-based sentence embedding model with a contrastive learning objective and leverage the embedding of the model as features when training intent classification models. Our approach achieves the state-of-the-art results for few-shot scenarios and performs better than other commercial solutions on popular intent classification benchmarks. However, generating features via a transformer-based model increases the inference time, especially for longer user inputs, due to the quadratic runtime of the transformer's attention mechanism. On top of model distillation, we introduce a practical multi-task adaptation approach that configures dynamic token pruning without the need for task-specific training for intent classification. We demonstrate that this approach improves the inference speed of popular sentence transformer models without affecting model performance.
Unsupervised Compound Domain Adaptation for Face Anti-Spoofing
May 18, 2021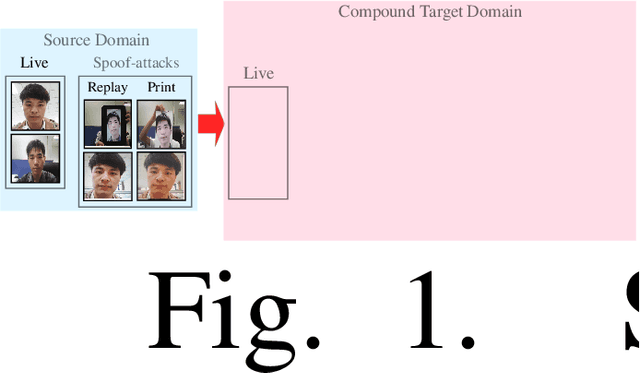
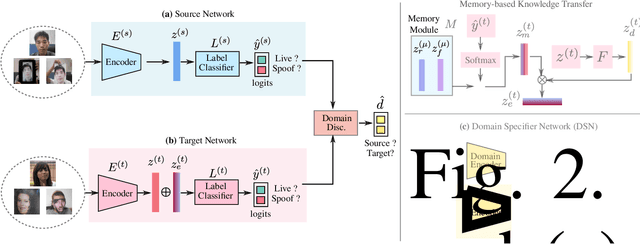
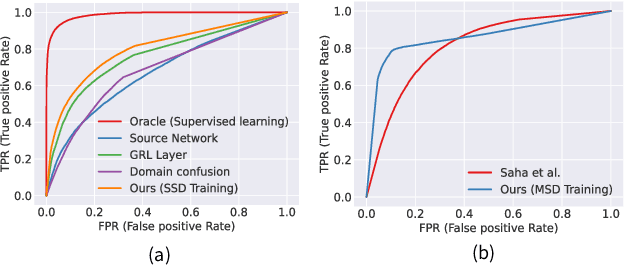
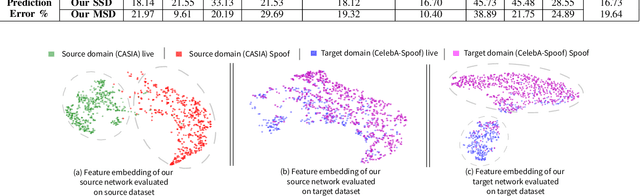
We address the problem of face anti-spoofing which aims to make the face verification systems robust in the real world settings. The context of detecting live vs. spoofed face images may differ significantly in the target domain, when compared to that of labeled source domain where the model is trained. Such difference may be caused due to new and unknown spoof types, illumination conditions, scene backgrounds, among many others. These varieties of differences make the target a compound domain, thus calling for the problem of the unsupervised compound domain adaptation. We demonstrate the effectiveness of the compound domain assumption for the task of face anti-spoofing, for the first time in this work. To this end, we propose a memory augmentation method for adapting the source model to the target domain in a domain aware manner. The adaptation process is further improved by using the curriculum learning and the domain agnostic source network training approaches. The proposed method successfully adapts to the compound target domain consisting multiple new spoof types. Our experiments on multiple benchmark datasets demonstrate the superiority of the proposed method over the state-of-the-art.
Modeling Preconditions in Text with a Crowd-sourced Dataset
Oct 14, 2020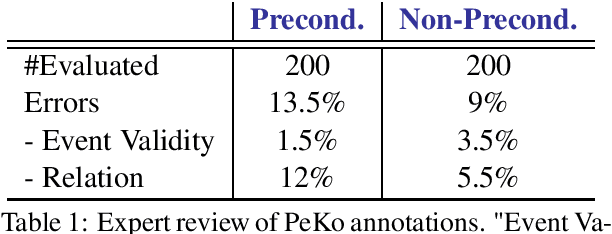

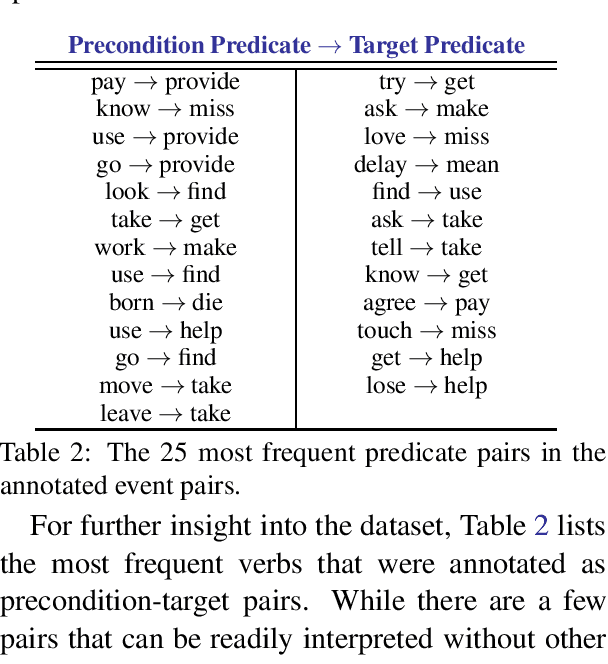
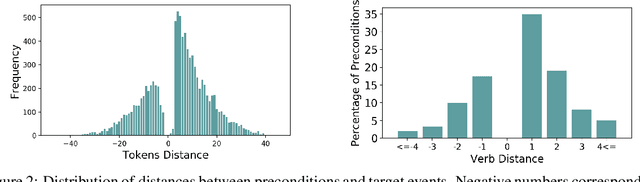
Preconditions provide a form of logical connection between events that explains why some events occur together and information that is complementary to the more widely studied relations such as causation, temporal ordering, entailment, and discourse relations. Modeling preconditions in text has been hampered in part due to the lack of large scale labeled data grounded in text. This paper introduces PeKo, a crowd-sourced annotation of preconditions between event pairs in newswire, an order of magnitude larger than prior text annotations. To complement this new corpus, we also introduce two challenge tasks aimed at modeling preconditions: (i) Precondition Identification -- a standard classification task defined over pairs of event mentions, and (ii) Precondition Generation -- a generative task aimed at testing a more general ability to reason about a given event. Evaluation on both tasks shows that modeling preconditions is challenging even for today's large language models (LM). This suggests that precondition knowledge is not easily accessible in LM-derived representations alone. Our generation results show that fine-tuning an LM on PeKo yields better conditional relations than when trained on raw text or temporally-ordered corpora.