 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical token pruning for foundation models in few-shot conversational virtual assistant systems
Aug 21, 2024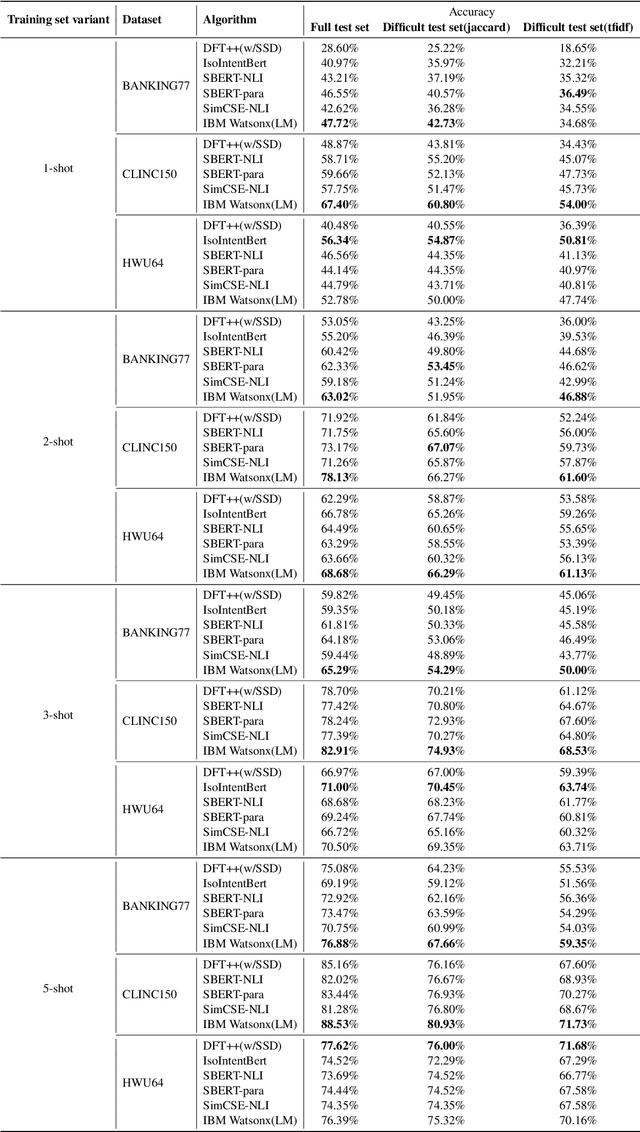
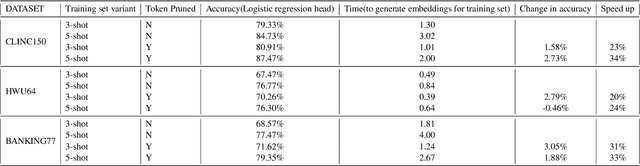
In an enterprise Virtual Assistant (VA) system, intent classification is the crucial component that determines how a user input is handled based on what the user wants. The VA system is expected to be a cost-efficient SaaS service with low training and inference time while achieving high accuracy even with a small number of training samples. We pretrain a transformer-based sentence embedding model with a contrastive learning objective and leverage the embedding of the model as features when training intent classification models. Our approach achieves the state-of-the-art results for few-shot scenarios and performs better than other commercial solutions on popular intent classification benchmarks. However, generating features via a transformer-based model increases the inference time, especially for longer user inputs, due to the quadratic runtime of the transformer's attention mechanism. On top of model distillation, we introduce a practical multi-task adaptation approach that configures dynamic token pruning without the need for task-specific training for intent classification. We demonstrate that this approach improves the inference speed of popular sentence transformer models without affecting model performance.
An Approach to Build Zero-Shot Slot-Filling System for Industry-Grade Conversational Assistants
Jun 13, 2024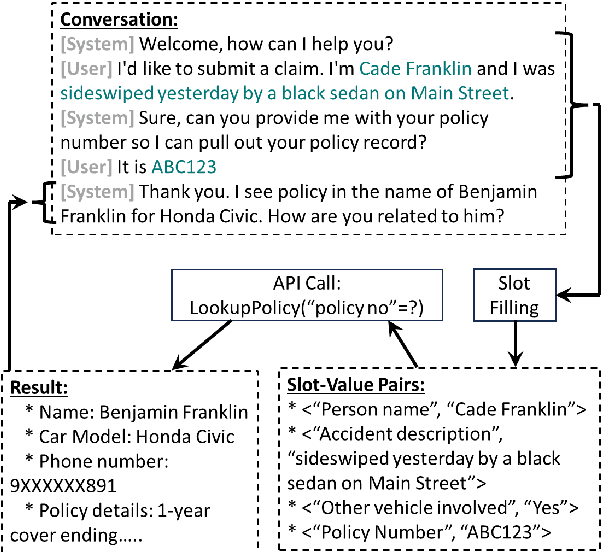
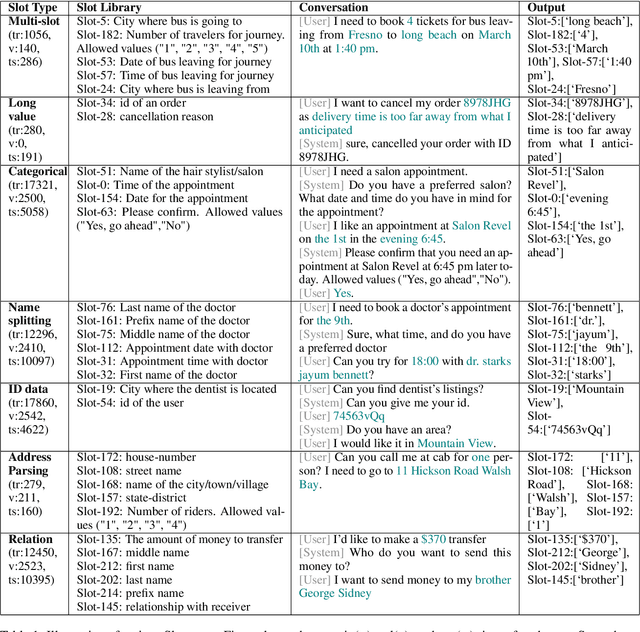
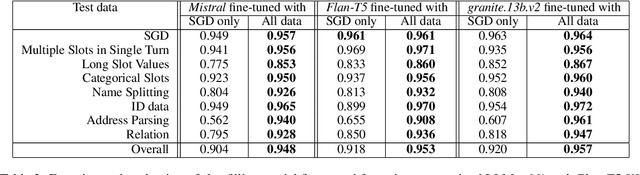

We present an approach to build Large Language Model (LLM) based slot-filling system to perform Dialogue State Tracking in conversational assistants serving across a wide variety of industry-grade applications. Key requirements of this system include: 1) usage of smaller-sized models to meet low latency requirements and to enable convenient and cost-effective cloud and customer premise deployments, and 2) zero-shot capabilities to serve across a wide variety of domains, slot types and conversational scenarios. We adopt a fine-tuning approach where a pre-trained LLM is fine-tuned into a slot-filling model using task specific data. The fine-tuning data is prepared carefully to cover a wide variety of slot-filling task scenarios that the model is expected to face across various domains. We give details of the data preparation and model building process. We also give a detailed analysis of the results of our experimental evaluations. Results show that our prescribed approach for slot-filling model building has resulted in 6.9% relative improvement of F1 metric over the best baseline on a realistic benchmark, while at the same time reducing the latency by 57%. More over, the data we prepared has helped improve F1 on an average by 4.2% relative across various slot-types.
Distinguish Sense from Nonsense: Out-of-Scope Detection for Virtual Assistants
Jan 16, 2023Out of Scope (OOS) detection in Conversational AI solutions enables a chatbot to handle a conversation gracefully when it is unable to make sense of the end-user query. Accurately tagging a query as out-of-domain is particularly hard in scenarios when the chatbot is not equipped to handle a topic which has semantic overlap with an existing topic it is trained on. We propose a simple yet effective OOS detection method that outperforms standard OOS detection methods in a real-world deployment of virtual assistants. We discuss the various design and deployment considerations for a cloud platform solution to train virtual assistants and deploy them at scale. Additionally, we propose a collection of datasets that replicates real-world scenarios and show comprehensive results in various settings using both offline and online evaluation metrics.
Benchmarking Intent Detection for Task-Oriented Dialog Systems
Dec 07, 2020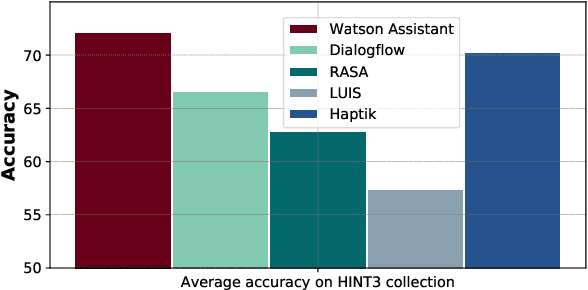
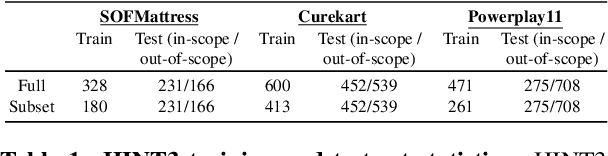
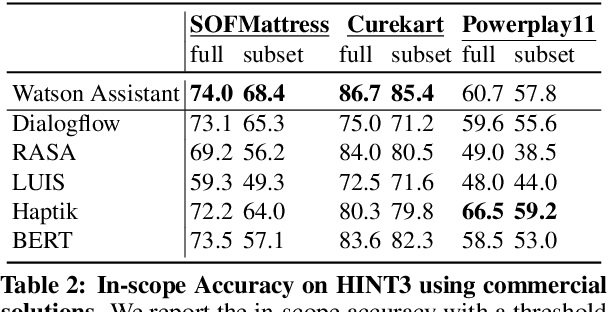
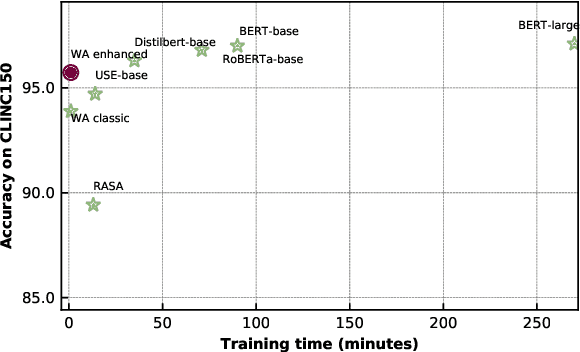
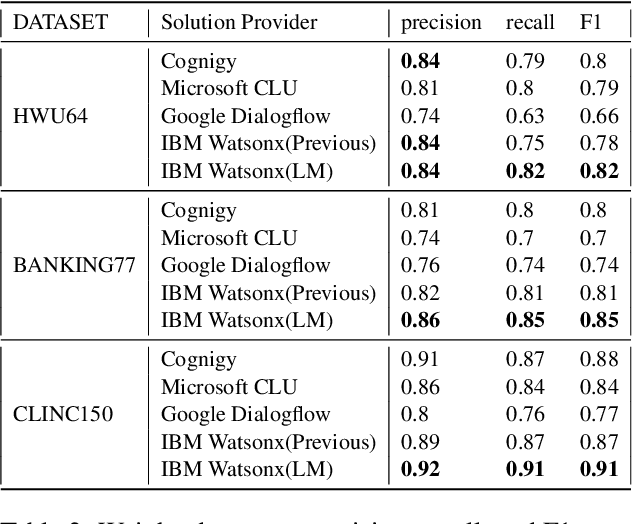
Intent detection is a key component of modern goal-oriented dialog systems that accomplish a user task by predicting the intent of users' text input. There are three primary challenges in designing robust and accurate intent detection models. First, typical intent detection models require a large amount of labeled data to achieve high accuracy. Unfortunately, in practical scenarios it is more common to find small, unbalanced, and noisy datasets. Secondly, even with large training data, the intent detection models can see a different distribution of test data when being deployed in the real world, leading to poor accuracy. Finally, a practical intent detection model must be computationally efficient in both training and single query inference so that it can be used continuously and re-trained frequently. We benchmark intent detection methods on a variety of datasets. Our results show that Watson Assistant's intent detection model outperforms other commercial solutions and is comparable to large pretrained language models while requiring only a fraction of computational resources and training data. Watson Assistant demonstrates a higher degree of robustness when the training and test distributions differ.
Multilingual BERT Post-Pretraining Alignment
Oct 23, 2020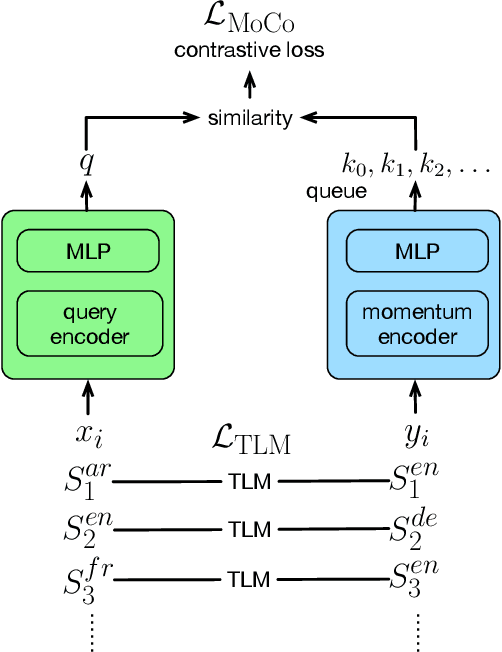
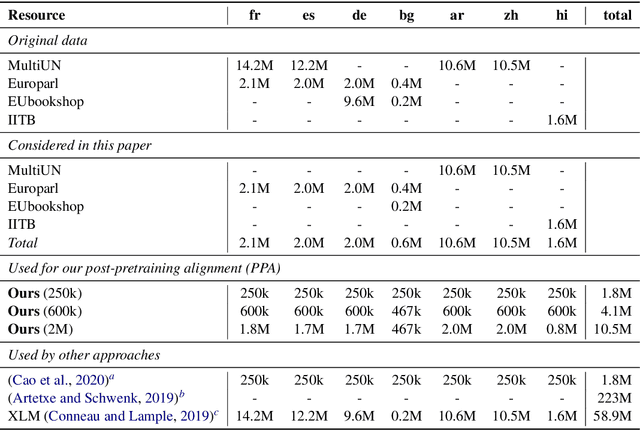
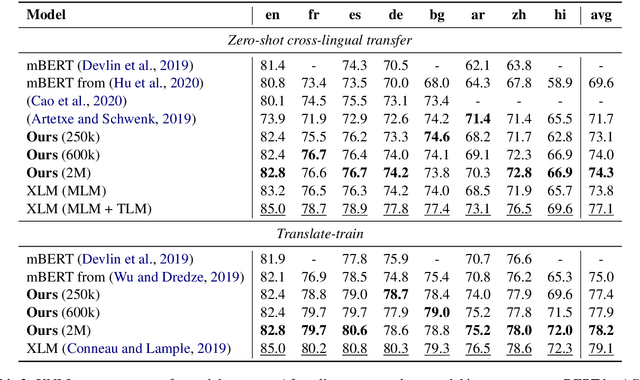
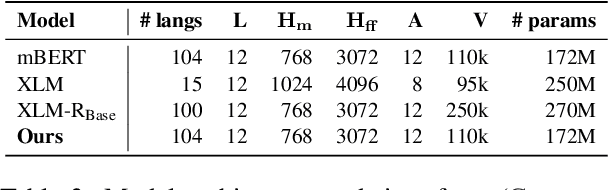
We propose a simple method to align multilingual contextual embeddings as a post-pretraining step for improved zero-shot cross-lingual transferability of the pretrained models. Using parallel data, our method aligns embeddings on the word level through the recently proposed Translation Language Modeling objective as well as on the sentence level via contrastive learning and random input shuffling. We also perform code-switching with English when finetuning on downstream tasks. On XNLI, our best model (initialized from mBERT) improves over mBERT by 4.7% in the zero-shot setting and achieves comparable result to XLM for translate-train while using less than 18% of the same parallel data and 31% less model parameters. On MLQA, our model outperforms XLM-R_Base that has 57% more parameters than ours.