 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
An Approach to Build Zero-Shot Slot-Filling System for Industry-Grade Conversational Assistants
Jun 13, 2024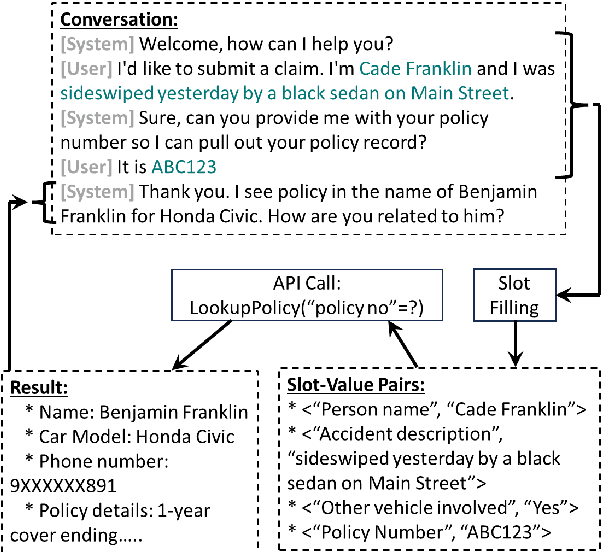
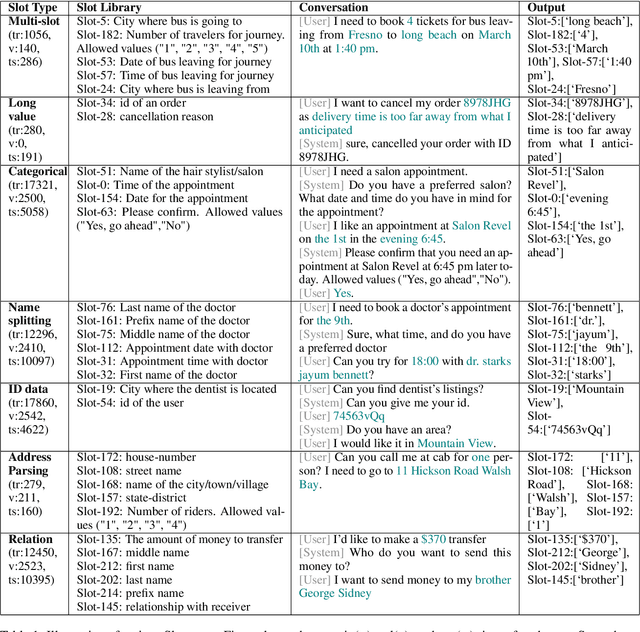
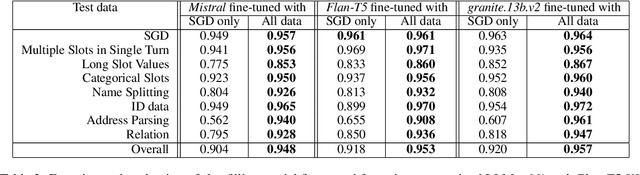

We present an approach to build Large Language Model (LLM) based slot-filling system to perform Dialogue State Tracking in conversational assistants serving across a wide variety of industry-grade applications. Key requirements of this system include: 1) usage of smaller-sized models to meet low latency requirements and to enable convenient and cost-effective cloud and customer premise deployments, and 2) zero-shot capabilities to serve across a wide variety of domains, slot types and conversational scenarios. We adopt a fine-tuning approach where a pre-trained LLM is fine-tuned into a slot-filling model using task specific data. The fine-tuning data is prepared carefully to cover a wide variety of slot-filling task scenarios that the model is expected to face across various domains. We give details of the data preparation and model building process. We also give a detailed analysis of the results of our experimental evaluations. Results show that our prescribed approach for slot-filling model building has resulted in 6.9% relative improvement of F1 metric over the best baseline on a realistic benchmark, while at the same time reducing the latency by 57%. More over, the data we prepared has helped improve F1 on an average by 4.2% relative across various slot-types.
PowerAI DDL
Aug 07, 2017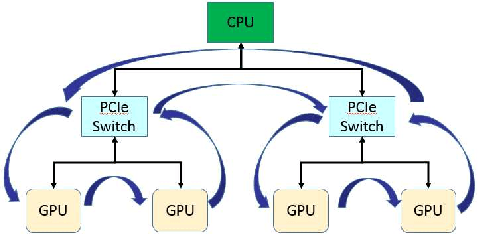
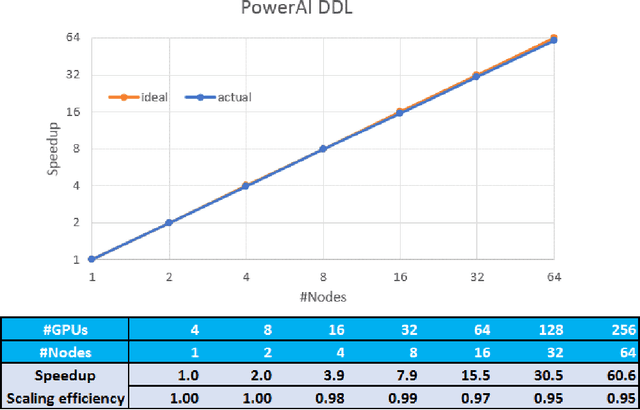
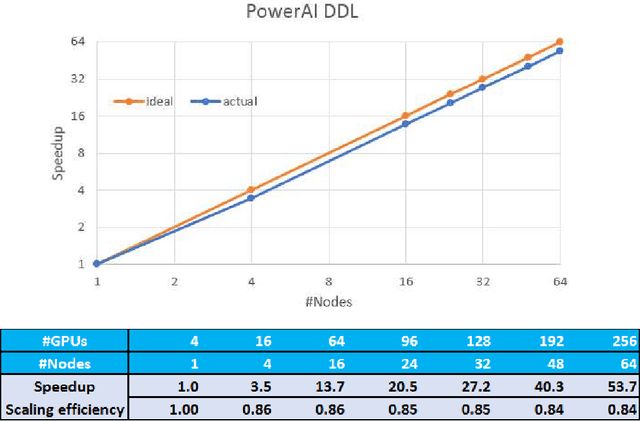
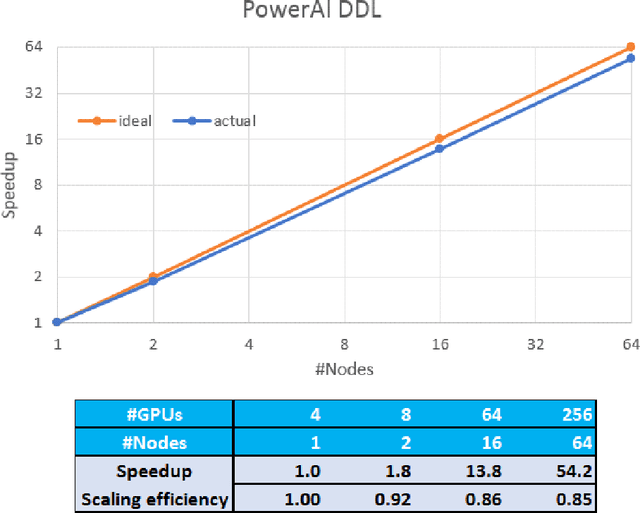
As deep neural networks become more complex and input datasets grow larger, it can take days or even weeks to train a deep neural network to the desired accuracy. Therefore, distributed Deep Learning at a massive scale is a critical capability, since it offers the potential to reduce the training time from weeks to hours. In this paper, we present a software-hardware co-optimized distributed Deep Learning system that can achieve near-linear scaling up to hundreds of GPUs. The core algorithm is a multi-ring communication pattern that provides a good tradeoff between latency and bandwidth and adapts to a variety of system configurations. The communication algorithm is implemented as a library for easy use. This library has been integrated into Tensorflow, Caffe, and Torch. We train Resnet-101 on Imagenet 22K with 64 IBM Power8 S822LC servers (256 GPUs) in about 7 hours to an accuracy of 33.8 % validation accuracy. Microsoft's ADAM and Google's DistBelief results did not reach 30 % validation accuracy for Imagenet 22K. Compared to Facebook AI Research's recent paper on 256 GPU training, we use a different communication algorithm, and our combined software and hardware system offers better communication overhead for Resnet-50. A PowerAI DDL enabled version of Torch completed 90 epochs of training on Resnet 50 for 1K classes in 50 minutes using 64 IBM Power8 S822LC servers (256 GPUs).