 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNESTFUL: A Benchmark for Evaluating LLMs on Nested Sequences of API Calls
Sep 04, 2024Autonomous agent applications powered by large language models (LLMs) have recently risen to prominence as effective tools for addressing complex real-world tasks. At their core, agentic workflows rely on LLMs to plan and execute the use of tools and external Application Programming Interfaces (APIs) in sequence to arrive at the answer to a user's request. Various benchmarks and leaderboards have emerged to evaluate an LLM's capabilities for tool and API use; however, most of these evaluations only track single or multiple isolated API calling capabilities. In this paper, we present NESTFUL, a benchmark to evaluate LLMs on nested sequences of API calls, i.e., sequences where the output of one API call is passed as input to a subsequent call. NESTFUL has a total of 300 human annotated samples divided into two types - executable and non-executable. The executable samples are curated manually by crawling Rapid-APIs whereas the non-executable samples are hand picked by human annotators from data synthetically generated using an LLM. We evaluate state-of-the-art LLMs with function calling abilities on NESTFUL. Our results show that most models do not perform well on nested APIs in NESTFUL as compared to their performance on the simpler problem settings available in existing benchmarks.
TabSketchFM: Sketch-based Tabular Representation Learning for Data Discovery over Data Lakes
Jun 28, 2024



Enterprises have a growing need to identify relevant tables in data lakes; e.g. tables that are unionable, joinable, or subsets of each other. Tabular neural models can be helpful for such data discovery tasks. In this paper, we present TabSketchFM, a neural tabular model for data discovery over data lakes. First, we propose a novel pre-training sketch-based approach to enhance the effectiveness of data discovery techniques in neural tabular models. Second, to further finetune the pretrained model for several downstream tasks, we develop LakeBench, a collection of 8 benchmarks to help with different data discovery tasks such as finding tasks that are unionable, joinable, or subsets of each other. We then show on these finetuning tasks that TabSketchFM achieves state-of-the art performance compared to existing neural models. Third, we use these finetuned models to search for tables that are unionable, joinable, or can be subsets of each other. Our results demonstrate improvements in F1 scores for search compared to state-of-the-art techniques (even up to 70% improvement in a joinable search benchmark). Finally, we show significant transfer across datasets and tasks establishing that our model can generalize across different tasks over different data lakes
Granite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
Feb 23, 2024There is a growing need for Large Language Models (LLMs) to effectively use tools and external Application Programming Interfaces (APIs) to plan and complete tasks. As such, there is tremendous interest in methods that can acquire sufficient quantities of train and test data that involve calls to tools / APIs. Two lines of research have emerged as the predominant strategies for addressing this challenge. The first has focused on synthetic data generation techniques, while the second has involved curating task-adjacent datasets which can be transformed into API / Tool-based tasks. In this paper, we focus on the task of identifying, curating, and transforming existing datasets and, in turn, introduce API-BLEND, a large corpora for training and systematic testing of tool-augmented LLMs. The datasets mimic real-world scenarios involving API-tasks such as API / tool detection, slot filling, and sequencing of the detected APIs. We demonstrate the utility of the API-BLEND dataset for both training and benchmarking purposes.
Formally Specifying the High-Level Behavior of LLM-Based Agents
Oct 12, 2023
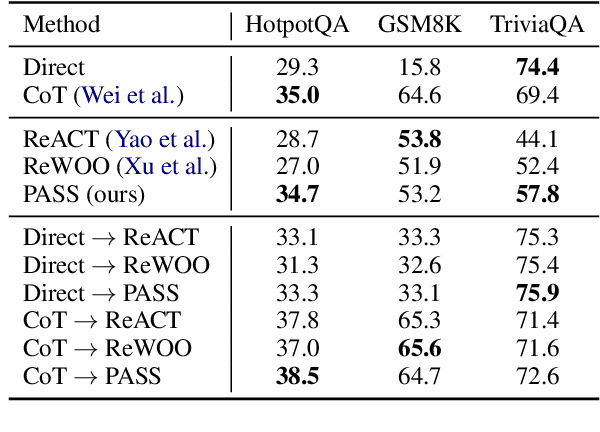
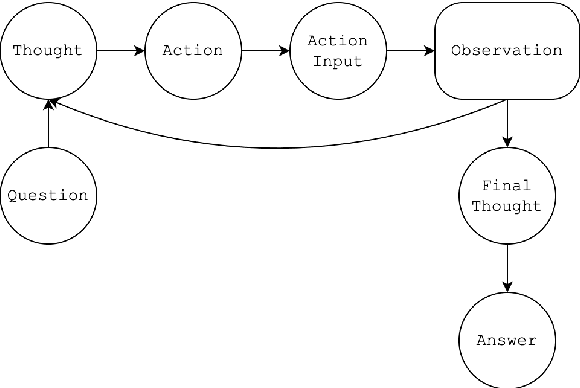
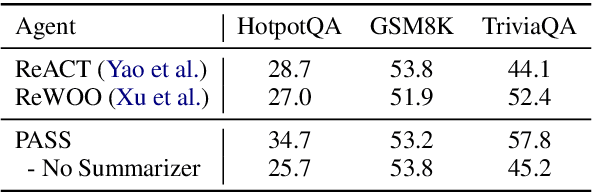
LLM-based agents have recently emerged as promising tools for solving challenging problems without the need for task-specific finetuned models that can be expensive to procure. Currently, the design and implementation of such agents is ad hoc, as the wide variety of tasks that LLM-based agents may be applied to naturally means there can be no one-size-fits-all approach to agent design. In this work we aim to alleviate the difficulty of designing and implementing new agents by proposing a minimalistic, high-level generation framework that simplifies the process of building agents. The framework we introduce allows the user to specify desired agent behaviors in Linear Temporal Logic (LTL). The declarative LTL specification is then used to construct a constrained decoder that guarantees the LLM will produce an output exhibiting the desired behavior. By designing our framework in this way, we obtain several benefits, including the ability to enforce complex agent behavior, the ability to formally validate prompt examples, and the ability to seamlessly incorporate content-focused logical constraints into generation. In particular, our declarative approach, in which the desired behavior is simply described without concern for how it should be implemented or enforced, enables rapid design, implementation and experimentation with different LLM-based agents. We demonstrate how the proposed framework can be used to implement recent LLM-based agents, and show how the guardrails our approach provides can lead to improvements in agent performance. In addition, we release our code for general use.
LakeBench: Benchmarks for Data Discovery over Data Lakes
Jul 09, 2023



Within enterprises, there is a growing need to intelligently navigate data lakes, specifically focusing on data discovery. Of particular importance to enterprises is the ability to find related tables in data repositories. These tables can be unionable, joinable, or subsets of each other. There is a dearth of benchmarks for these tasks in the public domain, with related work targeting private datasets. In LakeBench, we develop multiple benchmarks for these tasks by using the tables that are drawn from a diverse set of data sources such as government data from CKAN, Socrata, and the European Central Bank. We compare the performance of 4 publicly available tabular foundational models on these tasks. None of the existing models had been trained on the data discovery tasks that we developed for this benchmark; not surprisingly, their performance shows significant room for improvement. The results suggest that the establishment of such benchmarks may be useful to the community to build tabular models usable for data discovery in data lakes.
MISMATCH: Fine-grained Evaluation of Machine-generated Text with Mismatch Error Types
Jun 18, 2023



With the growing interest in large language models, the need for evaluating the quality of machine text compared to reference (typically human-generated) text has become focal attention. Most recent works focus either on task-specific evaluation metrics or study the properties of machine-generated text captured by the existing metrics. In this work, we propose a new evaluation scheme to model human judgments in 7 NLP tasks, based on the fine-grained mismatches between a pair of texts. Inspired by the recent efforts in several NLP tasks for fine-grained evaluation, we introduce a set of 13 mismatch error types such as spatial/geographic errors, entity errors, etc, to guide the model for better prediction of human judgments. We propose a neural framework for evaluating machine texts that uses these mismatch error types as auxiliary tasks and re-purposes the existing single-number evaluation metrics as additional scalar features, in addition to textual features extracted from the machine and reference texts. Our experiments reveal key insights about the existing metrics via the mismatch errors. We show that the mismatch errors between the sentence pairs on the held-out datasets from 7 NLP tasks align well with the human evaluation.
An Ensemble Approach for Automated Theorem Proving Based on Efficient Name Invariant Graph Neural Representations
May 15, 2023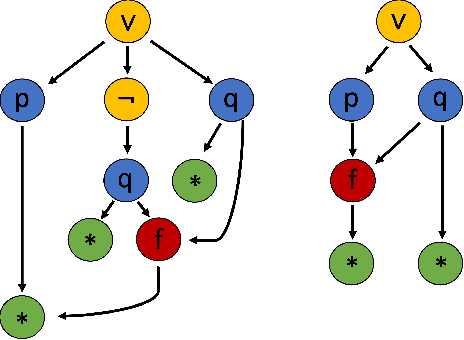
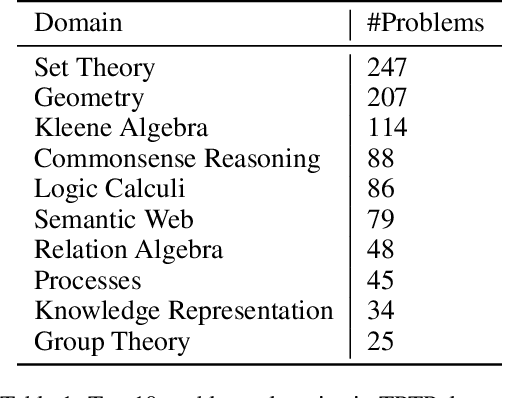
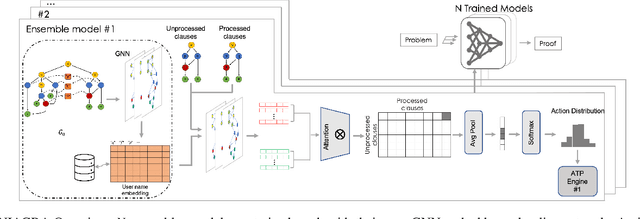

Using reinforcement learning for automated theorem proving has recently received much attention. Current approaches use representations of logical statements that often rely on the names used in these statements and, as a result, the models are generally not transferable from one domain to another. The size of these representations and whether to include the whole theory or part of it are other important decisions that affect the performance of these approaches as well as their runtime efficiency. In this paper, we present NIAGRA; an ensemble Name InvAriant Graph RepresentAtion. NIAGRA addresses this problem by using 1) improved Graph Neural Networks for learning name-invariant formula representations that is tailored for their unique characteristics and 2) an efficient ensemble approach for automated theorem proving. Our experimental evaluation shows state-of-the-art performance on multiple datasets from different domains with improvements up to 10% compared to the best learning-based approaches. Furthermore, transfer learning experiments show that our approach significantly outperforms other learning-based approaches by up to 28%.
Serenity: Library Based Python Code Analysis for Code Completion and Automated Machine Learning
Jan 05, 2023
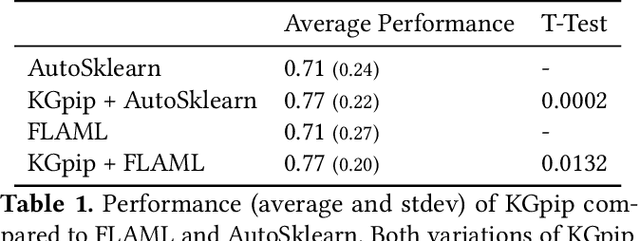

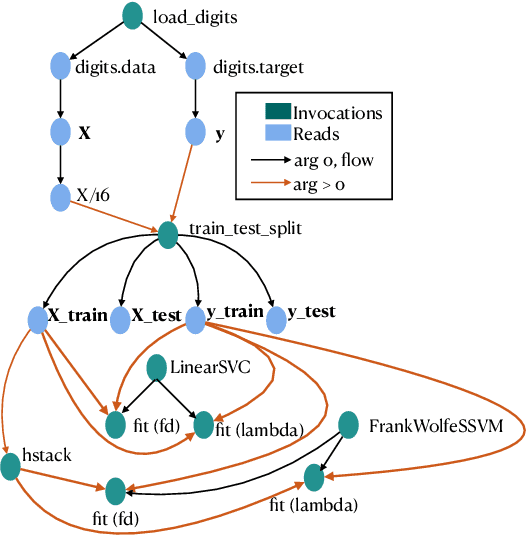
Dynamically typed languages such as Python have become very popular. Among other strengths, Python's dynamic nature and its straightforward linking to native code have made it the de-facto language for many research areas such as Artificial Intelligence. This flexibility, however, makes static analysis very hard. While creating a sound, or a soundy, analysis for Python remains an open problem, we present in this work Serenity, a framework for static analysis of Python that turns out to be sufficient for some tasks. The Serenity framework exploits two basic mechanisms: (a) reliance on dynamic dispatch at the core of language translation, and (b) extreme abstraction of libraries, to generate an abstraction of the code. We demonstrate the efficiency and usefulness of Serenity's analysis in two applications: code completion and automated machine learning. In these two applications, we demonstrate that such analysis has a strong signal, and can be leveraged to establish state-of-the-art performance, comparable to neural models and dynamic analysis respectively.