 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNESTFUL: A Benchmark for Evaluating LLMs on Nested Sequences of API Calls
Sep 04, 2024Autonomous agent applications powered by large language models (LLMs) have recently risen to prominence as effective tools for addressing complex real-world tasks. At their core, agentic workflows rely on LLMs to plan and execute the use of tools and external Application Programming Interfaces (APIs) in sequence to arrive at the answer to a user's request. Various benchmarks and leaderboards have emerged to evaluate an LLM's capabilities for tool and API use; however, most of these evaluations only track single or multiple isolated API calling capabilities. In this paper, we present NESTFUL, a benchmark to evaluate LLMs on nested sequences of API calls, i.e., sequences where the output of one API call is passed as input to a subsequent call. NESTFUL has a total of 300 human annotated samples divided into two types - executable and non-executable. The executable samples are curated manually by crawling Rapid-APIs whereas the non-executable samples are hand picked by human annotators from data synthetically generated using an LLM. We evaluate state-of-the-art LLMs with function calling abilities on NESTFUL. Our results show that most models do not perform well on nested APIs in NESTFUL as compared to their performance on the simpler problem settings available in existing benchmarks.
Granite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
Feb 23, 2024There is a growing need for Large Language Models (LLMs) to effectively use tools and external Application Programming Interfaces (APIs) to plan and complete tasks. As such, there is tremendous interest in methods that can acquire sufficient quantities of train and test data that involve calls to tools / APIs. Two lines of research have emerged as the predominant strategies for addressing this challenge. The first has focused on synthetic data generation techniques, while the second has involved curating task-adjacent datasets which can be transformed into API / Tool-based tasks. In this paper, we focus on the task of identifying, curating, and transforming existing datasets and, in turn, introduce API-BLEND, a large corpora for training and systematic testing of tool-augmented LLMs. The datasets mimic real-world scenarios involving API-tasks such as API / tool detection, slot filling, and sequencing of the detected APIs. We demonstrate the utility of the API-BLEND dataset for both training and benchmarking purposes.
Formally Specifying the High-Level Behavior of LLM-Based Agents
Oct 12, 2023
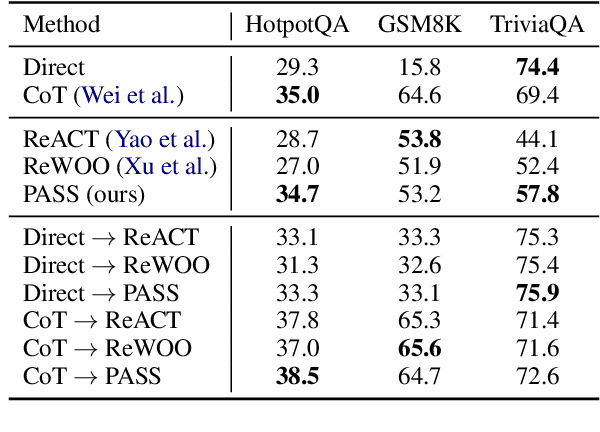
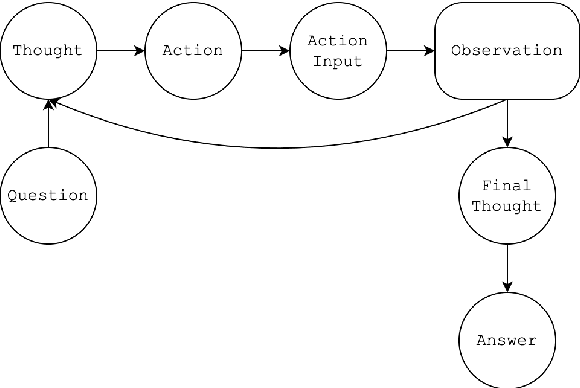
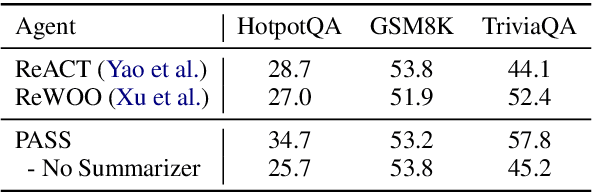
LLM-based agents have recently emerged as promising tools for solving challenging problems without the need for task-specific finetuned models that can be expensive to procure. Currently, the design and implementation of such agents is ad hoc, as the wide variety of tasks that LLM-based agents may be applied to naturally means there can be no one-size-fits-all approach to agent design. In this work we aim to alleviate the difficulty of designing and implementing new agents by proposing a minimalistic, high-level generation framework that simplifies the process of building agents. The framework we introduce allows the user to specify desired agent behaviors in Linear Temporal Logic (LTL). The declarative LTL specification is then used to construct a constrained decoder that guarantees the LLM will produce an output exhibiting the desired behavior. By designing our framework in this way, we obtain several benefits, including the ability to enforce complex agent behavior, the ability to formally validate prompt examples, and the ability to seamlessly incorporate content-focused logical constraints into generation. In particular, our declarative approach, in which the desired behavior is simply described without concern for how it should be implemented or enforced, enables rapid design, implementation and experimentation with different LLM-based agents. We demonstrate how the proposed framework can be used to implement recent LLM-based agents, and show how the guardrails our approach provides can lead to improvements in agent performance. In addition, we release our code for general use.
Slide, Constrain, Parse, Repeat: Synchronous SlidingWindows for Document AMR Parsing
May 26, 2023The sliding window approach provides an elegant way to handle contexts of sizes larger than the Transformer's input window, for tasks like language modeling. Here we extend this approach to the sequence-to-sequence task of document parsing. For this, we exploit recent progress in transition-based parsing to implement a parser with synchronous sliding windows over source and target. We develop an oracle and a parser for document-level AMR by expanding on Structured-BART such that it leverages source-target alignments and constrains decoding to guarantee synchronicity and consistency across overlapping windows. We evaluate our oracle and parser using the Abstract Meaning Representation (AMR) parsing 3.0 corpus. On the Multi-Sentence development set of AMR 3.0, we show that our transition oracle loses only 8\% of the gold cross-sentential links despite using a sliding window. In practice, this approach also results in a high-quality document-level parser with manageable memory requirements. Our proposed system performs on par with the state-of-the-art pipeline approach for document-level AMR parsing task on Multi-Sentence AMR 3.0 corpus while maintaining sentence-level parsing performance.
DocAMR: Multi-Sentence AMR Representation and Evaluation
Dec 15, 2021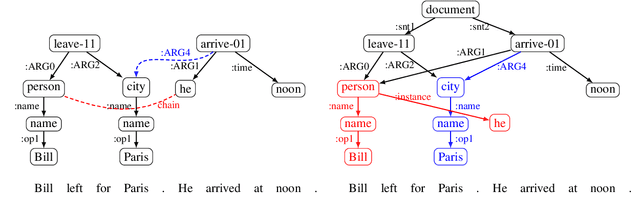
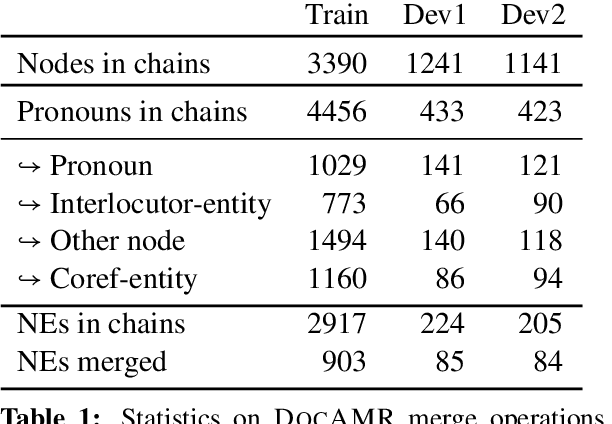
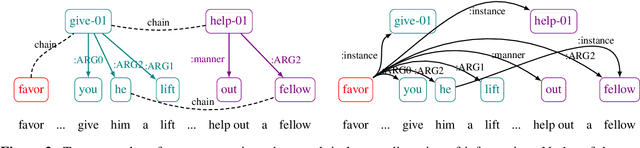
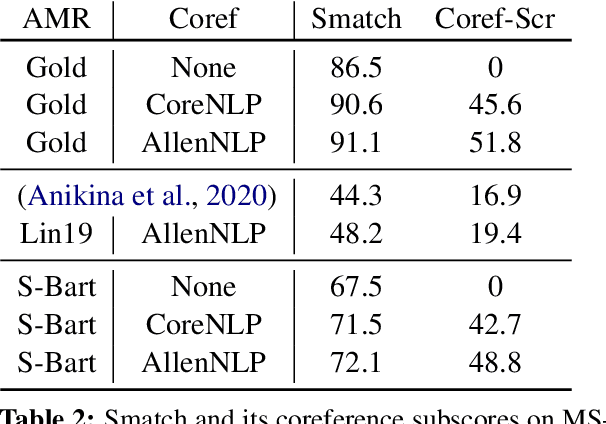
Despite extensive research on parsing of English sentences into Abstraction Meaning Representation (AMR) graphs, which are compared to gold graphs via the Smatch metric, full-document parsing into a unified graph representation lacks well-defined representation and evaluation. Taking advantage of a super-sentential level of coreference annotation from previous work, we introduce a simple algorithm for deriving a unified graph representation, avoiding the pitfalls of information loss from over-merging and lack of coherence from under-merging. Next, we describe improvements to the Smatch metric to make it tractable for comparing document-level graphs, and use it to re-evaluate the best published document-level AMR parser. We also present a pipeline approach combining the top performing AMR parser and coreference resolution systems, providing a strong baseline for future research.
Circles are like Ellipses, or Ellipses are like Circles? Measuring the Degree of Asymmetry of Static and Contextual Embeddings and the Implications to Representation Learning
Dec 03, 2020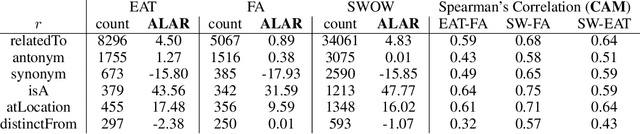
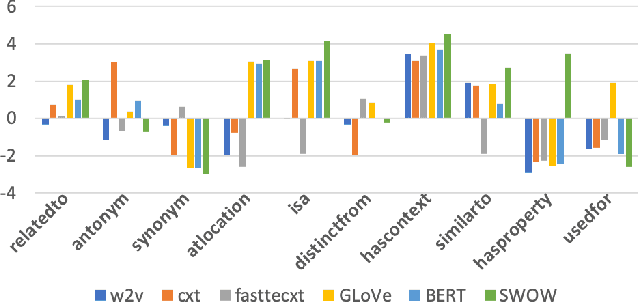
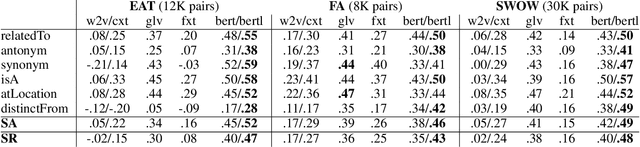
Human judgments of word similarity have been a popular method of evaluating the quality of word embedding. But it fails to measure the geometry properties such as asymmetry. For example, it is more natural to say "Ellipses are like Circles" than "Circles are like Ellipses". Such asymmetry has been observed from a psychoanalysis test called word evocation experiment, where one word is used to recall another. Although useful, such experimental data have been significantly understudied for measuring embedding quality. In this paper, we use three well-known evocation datasets to gain insights into asymmetry encoding of embedding. We study both static embedding as well as contextual embedding, such as BERT. Evaluating asymmetry for BERT is generally hard due to the dynamic nature of embedding. Thus, we probe BERT's conditional probabilities (as a language model) using a large number of Wikipedia contexts to derive a theoretically justifiable Bayesian asymmetry score. The result shows that contextual embedding shows randomness than static embedding on similarity judgments while performing well on asymmetry judgment, which aligns with its strong performance on "extrinsic evaluations" such as text classification. The asymmetry judgment and the Bayesian approach provides a new perspective to evaluate contextual embedding on intrinsic evaluation, and its comparison to similarity evaluation concludes our work with a discussion on the current state and the future of representation learning.
Text-based RL Agents with Commonsense Knowledge: New Challenges, Environments and Baselines
Oct 08, 2020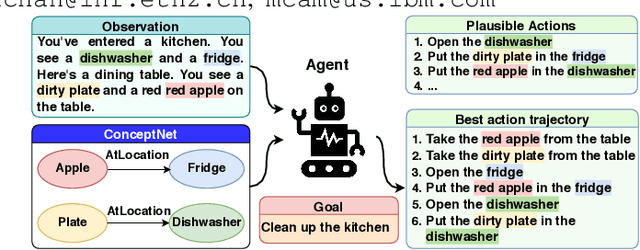


Text-based games have emerged as an important test-bed for Reinforcement Learning (RL) research, requiring RL agents to combine grounded language understanding with sequential decision making. In this paper, we examine the problem of infusing RL agents with commonsense knowledge. Such knowledge would allow agents to efficiently act in the world by pruning out implausible actions, and to perform look-ahead planning to determine how current actions might affect future world states. We design a new text-based gaming environment called TextWorld Commonsense (TWC) for training and evaluating RL agents with a specific kind of commonsense knowledge about objects, their attributes, and affordances. We also introduce several baseline RL agents which track the sequential context and dynamically retrieve the relevant commonsense knowledge from ConceptNet. We show that agents which incorporate commonsense knowledge in TWC perform better, while acting more efficiently. We conduct user-studies to estimate human performance on TWC and show that there is ample room for future improvement.
Beyond Backprop: Online Alternating Minimization with Auxiliary Variables
Oct 24, 2018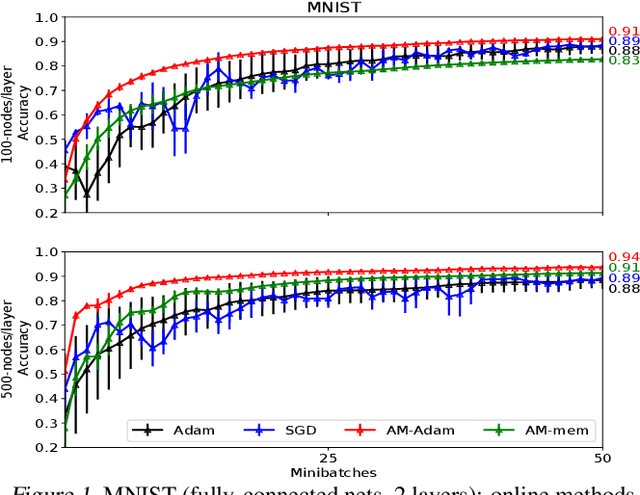
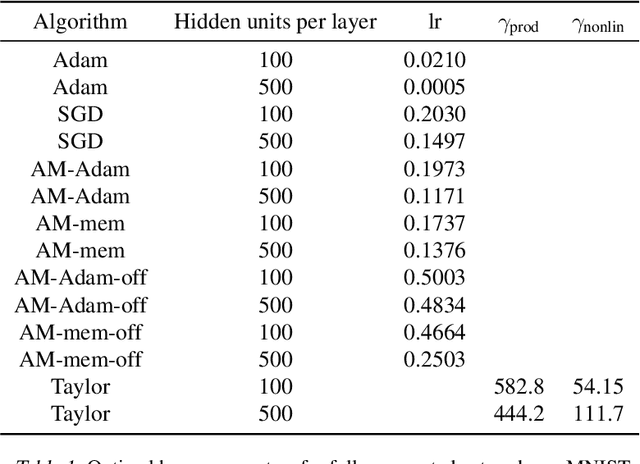
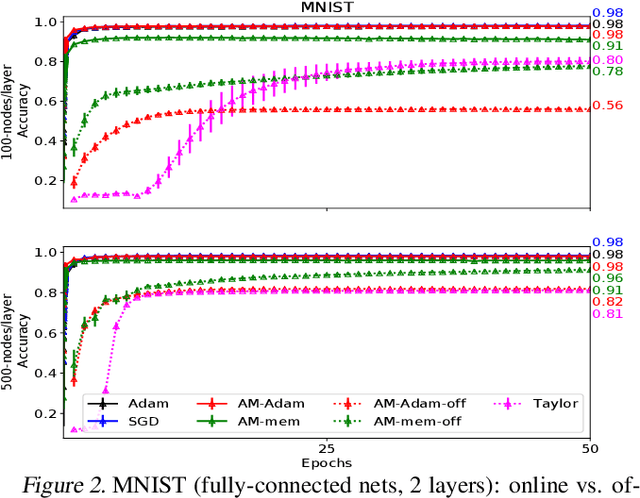
We propose a novel online alternating minimization (AltMin) algorithm for training deep neural networks, provide theoretical convergence guarantees and demonstrate its advantages on several classification tasks as compared both to standard backpropagation with stochastic gradient descent (backprop-SGD) and to offline alternating minimization. The key difference from backpropagation is an explicit optimization over hidden activations, which eliminates gradient chain computation in backprop, and breaks the weight training problem into independent, local optimization subproblems; this allows to avoid vanishing gradient issues, simplify handling non-differentiable nonlinearities, and perform parallel weight updates across the layers. Moreover, parallel local synaptic weight optimization with explicit activation propagation is a step closer to a more biologically plausible learning model than backpropagation, whose biological implausibility has been frequently criticized. Finally, the online nature of our approach allows to handle very large datasets, as well as continual, lifelong learning, which is our key contribution on top of recently proposed offline alternating minimization schemes (e.g., (Carreira-Perpinan andWang 2014), (Taylor et al. 2016)).