 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIRAL: Symbolic LLM Planning via Grounded and Reflective Search
Dec 29, 2025Large Language Models (LLMs) often falter at complex planning tasks that require exploration and self-correction, as their linear reasoning process struggles to recover from early mistakes. While search algorithms like Monte Carlo Tree Search (MCTS) can explore alternatives, they are often ineffective when guided by sparse rewards and fail to leverage the rich semantic capabilities of LLMs. We introduce SPIRAL (Symbolic LLM Planning via Grounded and Reflective Search), a novel framework that embeds a cognitive architecture of three specialized LLM agents into an MCTS loop. SPIRAL's key contribution is its integrated planning pipeline where a Planner proposes creative next steps, a Simulator grounds the search by predicting realistic outcomes, and a Critic provides dense reward signals through reflection. This synergy transforms MCTS from a brute-force search into a guided, self-correcting reasoning process. On the DailyLifeAPIs and HuggingFace datasets, SPIRAL consistently outperforms the default Chain-of-Thought planning method and other state-of-the-art agents. More importantly, it substantially surpasses other state-of-the-art agents; for example, SPIRAL achieves 83.6% overall accuracy on DailyLifeAPIs, an improvement of over 16 percentage points against the next-best search framework, while also demonstrating superior token efficiency. Our work demonstrates that structuring LLM reasoning as a guided, reflective, and grounded search process yields more robust and efficient autonomous planners. The source code, full appendices, and all experimental data are available for reproducibility at the official project repository.
Few-shot Policy (de)composition in Conversational Question Answering
Jan 20, 2025



The task of policy compliance detection (PCD) is to determine if a scenario is in compliance with respect to a set of written policies. In a conversational setting, the results of PCD can indicate if clarifying questions must be asked to determine compliance status. Existing approaches usually claim to have reasoning capabilities that are latent or require a large amount of annotated data. In this work, we propose logical decomposition for policy compliance (LDPC): a neuro-symbolic framework to detect policy compliance using large language models (LLMs) in a few-shot setting. By selecting only a few exemplars alongside recently developed prompting techniques, we demonstrate that our approach soundly reasons about policy compliance conversations by extracting sub-questions to be answered, assigning truth values from contextual information, and explicitly producing a set of logic statements from the given policies. The formulation of explicit logic graphs can in turn help answer PCDrelated questions with increased transparency and explainability. We apply this approach to the popular PCD and conversational machine reading benchmark, ShARC, and show competitive performance with no task-specific finetuning. We also leverage the inherently interpretable architecture of LDPC to understand where errors occur, revealing ambiguities in the ShARC dataset and highlighting the challenges involved with reasoning for conversational question answering.
A System and Benchmark for LLM-based Q&A on Heterogeneous Data
Sep 10, 2024In many industrial settings, users wish to ask questions whose answers may be found in structured data sources such as a spreadsheets, databases, APIs, or combinations thereof. Often, the user doesn't know how to identify or access the right data source. This problem is compounded even further if multiple (and potentially siloed) data sources must be assembled to derive the answer. Recently, various Text-to-SQL applications that leverage Large Language Models (LLMs) have addressed some of these problems by enabling users to ask questions in natural language. However, these applications remain impractical in realistic industrial settings because they fail to cope with the data source heterogeneity that typifies such environments. In this paper, we address heterogeneity by introducing the siwarex platform, which enables seamless natural language access to both databases and APIs. To demonstrate the effectiveness of siwarex, we extend the popular Spider dataset and benchmark by replacing some of its tables by data retrieval APIs. We find that siwarex does a good job of coping with data source heterogeneity. Our modified Spider benchmark will soon be available to the research community
Formally Specifying the High-Level Behavior of LLM-Based Agents
Oct 12, 2023
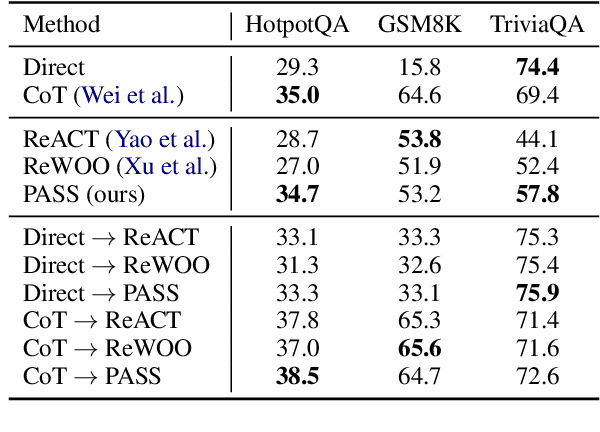
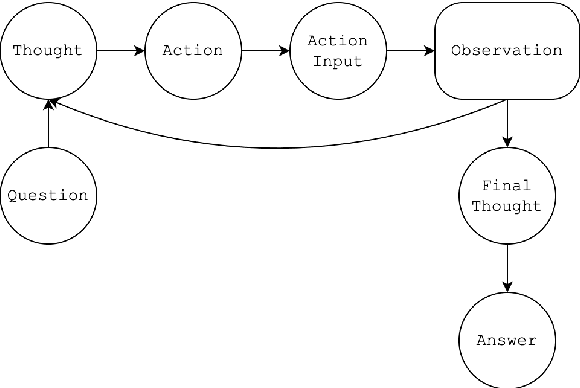
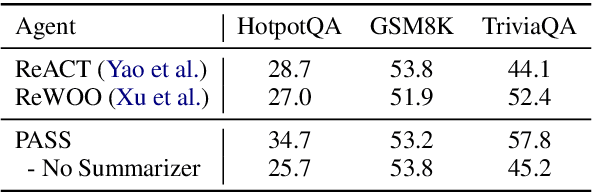
LLM-based agents have recently emerged as promising tools for solving challenging problems without the need for task-specific finetuned models that can be expensive to procure. Currently, the design and implementation of such agents is ad hoc, as the wide variety of tasks that LLM-based agents may be applied to naturally means there can be no one-size-fits-all approach to agent design. In this work we aim to alleviate the difficulty of designing and implementing new agents by proposing a minimalistic, high-level generation framework that simplifies the process of building agents. The framework we introduce allows the user to specify desired agent behaviors in Linear Temporal Logic (LTL). The declarative LTL specification is then used to construct a constrained decoder that guarantees the LLM will produce an output exhibiting the desired behavior. By designing our framework in this way, we obtain several benefits, including the ability to enforce complex agent behavior, the ability to formally validate prompt examples, and the ability to seamlessly incorporate content-focused logical constraints into generation. In particular, our declarative approach, in which the desired behavior is simply described without concern for how it should be implemented or enforced, enables rapid design, implementation and experimentation with different LLM-based agents. We demonstrate how the proposed framework can be used to implement recent LLM-based agents, and show how the guardrails our approach provides can lead to improvements in agent performance. In addition, we release our code for general use.
Learning Symbolic Rules over Abstract Meaning Representations for Textual Reinforcement Learning
Jul 05, 2023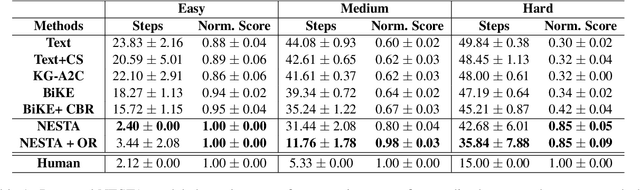
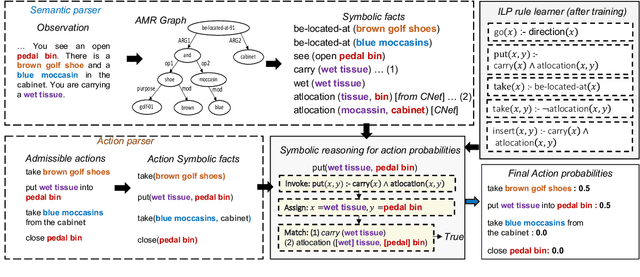
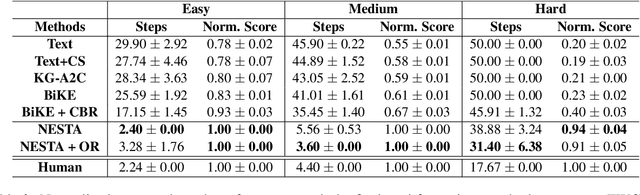
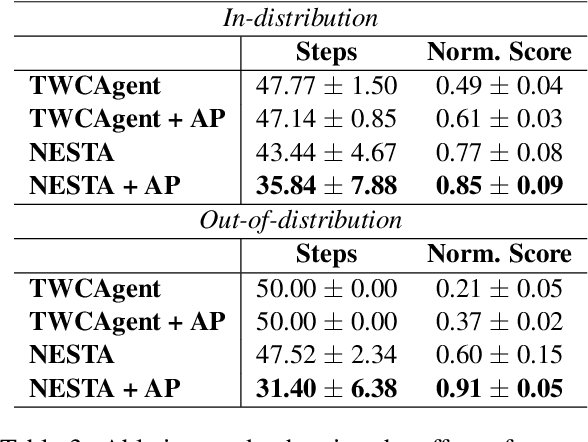
Text-based reinforcement learning agents have predominantly been neural network-based models with embeddings-based representation, learning uninterpretable policies that often do not generalize well to unseen games. On the other hand, neuro-symbolic methods, specifically those that leverage an intermediate formal representation, are gaining significant attention in language understanding tasks. This is because of their advantages ranging from inherent interpretability, the lesser requirement of training data, and being generalizable in scenarios with unseen data. Therefore, in this paper, we propose a modular, NEuro-Symbolic Textual Agent (NESTA) that combines a generic semantic parser with a rule induction system to learn abstract interpretable rules as policies. Our experiments on established text-based game benchmarks show that the proposed NESTA method outperforms deep reinforcement learning-based techniques by achieving better generalization to unseen test games and learning from fewer training interactions.
MISMATCH: Fine-grained Evaluation of Machine-generated Text with Mismatch Error Types
Jun 18, 2023



With the growing interest in large language models, the need for evaluating the quality of machine text compared to reference (typically human-generated) text has become focal attention. Most recent works focus either on task-specific evaluation metrics or study the properties of machine-generated text captured by the existing metrics. In this work, we propose a new evaluation scheme to model human judgments in 7 NLP tasks, based on the fine-grained mismatches between a pair of texts. Inspired by the recent efforts in several NLP tasks for fine-grained evaluation, we introduce a set of 13 mismatch error types such as spatial/geographic errors, entity errors, etc, to guide the model for better prediction of human judgments. We propose a neural framework for evaluating machine texts that uses these mismatch error types as auxiliary tasks and re-purposes the existing single-number evaluation metrics as additional scalar features, in addition to textual features extracted from the machine and reference texts. Our experiments reveal key insights about the existing metrics via the mismatch errors. We show that the mismatch errors between the sentence pairs on the held-out datasets from 7 NLP tasks align well with the human evaluation.
An Ensemble Approach for Automated Theorem Proving Based on Efficient Name Invariant Graph Neural Representations
May 15, 2023
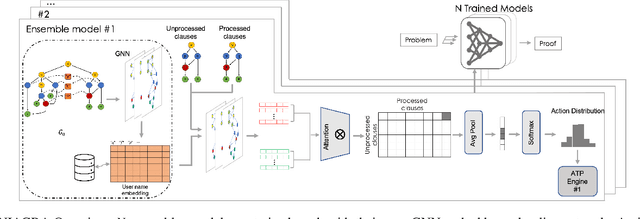

Using reinforcement learning for automated theorem proving has recently received much attention. Current approaches use representations of logical statements that often rely on the names used in these statements and, as a result, the models are generally not transferable from one domain to another. The size of these representations and whether to include the whole theory or part of it are other important decisions that affect the performance of these approaches as well as their runtime efficiency. In this paper, we present NIAGRA; an ensemble Name InvAriant Graph RepresentAtion. NIAGRA addresses this problem by using 1) improved Graph Neural Networks for learning name-invariant formula representations that is tailored for their unique characteristics and 2) an efficient ensemble approach for automated theorem proving. Our experimental evaluation shows state-of-the-art performance on multiple datasets from different domains with improvements up to 10% compared to the best learning-based approaches. Furthermore, transfer learning experiments show that our approach significantly outperforms other learning-based approaches by up to 28%.
Laziness Is a Virtue When It Comes to Compositionality in Neural Semantic Parsing
May 07, 2023
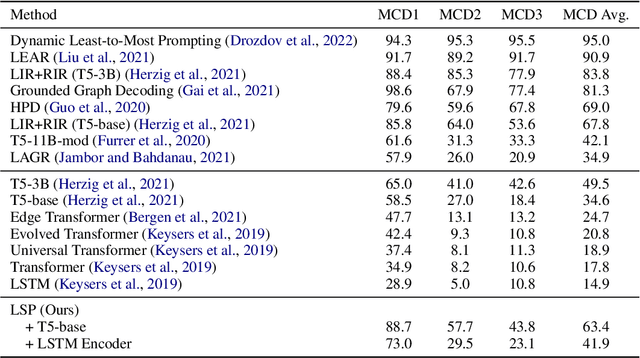


Nearly all general-purpose neural semantic parsers generate logical forms in a strictly top-down autoregressive fashion. Though such systems have achieved impressive results across a variety of datasets and domains, recent works have called into question whether they are ultimately limited in their ability to compositionally generalize. In this work, we approach semantic parsing from, quite literally, the opposite direction; that is, we introduce a neural semantic parsing generation method that constructs logical forms from the bottom up, beginning from the logical form's leaves. The system we introduce is lazy in that it incrementally builds up a set of potential semantic parses, but only expands and processes the most promising candidate parses at each generation step. Such a parsimonious expansion scheme allows the system to maintain an arbitrarily large set of parse hypotheses that are never realized and thus incur minimal computational overhead. We evaluate our approach on compositional generalization; specifically, on the challenging CFQ dataset and three Text-to-SQL datasets where we show that our novel, bottom-up semantic parsing technique outperforms general-purpose semantic parsers while also being competitive with comparable neural parsers that have been designed for each task.
Neuro-symbolic Models for Interpretable Time Series Classification using Temporal Logic Description
Sep 15, 2022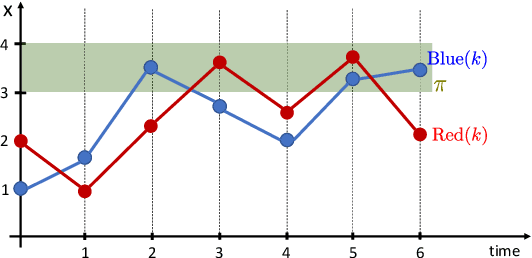
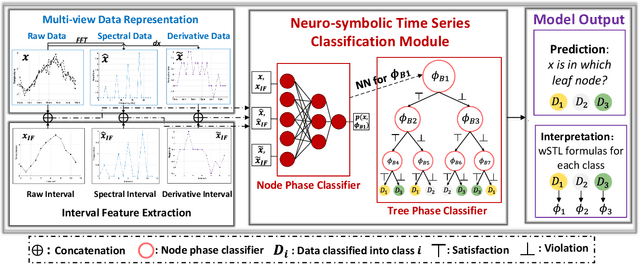
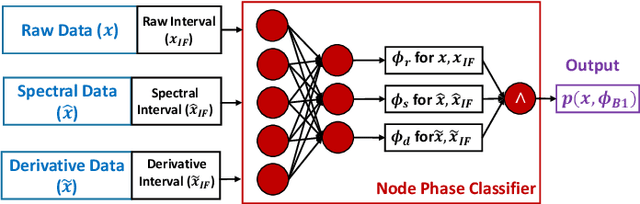
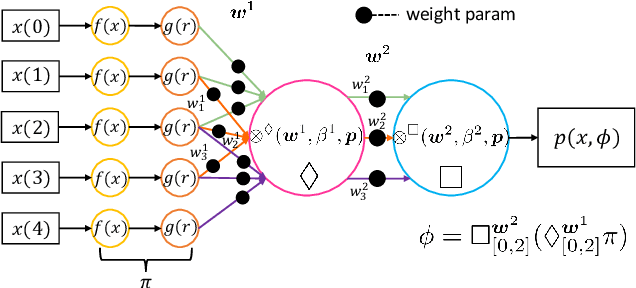
Most existing Time series classification (TSC) models lack interpretability and are difficult to inspect. Interpretable machine learning models can aid in discovering patterns in data as well as give easy-to-understand insights to domain specialists. In this study, we present Neuro-Symbolic Time Series Classification (NSTSC), a neuro-symbolic model that leverages signal temporal logic (STL) and neural network (NN) to accomplish TSC tasks using multi-view data representation and expresses the model as a human-readable, interpretable formula. In NSTSC, each neuron is linked to a symbolic expression, i.e., an STL (sub)formula. The output of NSTSC is thus interpretable as an STL formula akin to natural language, describing temporal and logical relations hidden in the data. We propose an NSTSC-based classifier that adopts a decision-tree approach to learn formula structures and accomplish a multiclass TSC task. The proposed smooth activation functions for wSTL allow the model to be learned in an end-to-end fashion. We test NSTSC on a real-world wound healing dataset from mice and benchmark datasets from the UCR time-series repository, demonstrating that NSTSC achieves comparable performance with the state-of-the-art models. Furthermore, NSTSC can generate interpretable formulas that match with domain knowledge.
Expressive Reasoning Graph Store: A Unified Framework for Managing RDF and Property Graph Databases
Sep 13, 2022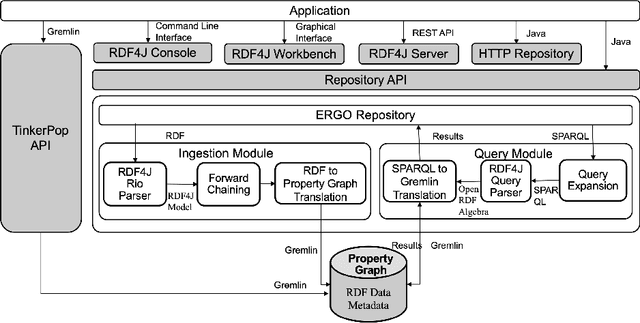
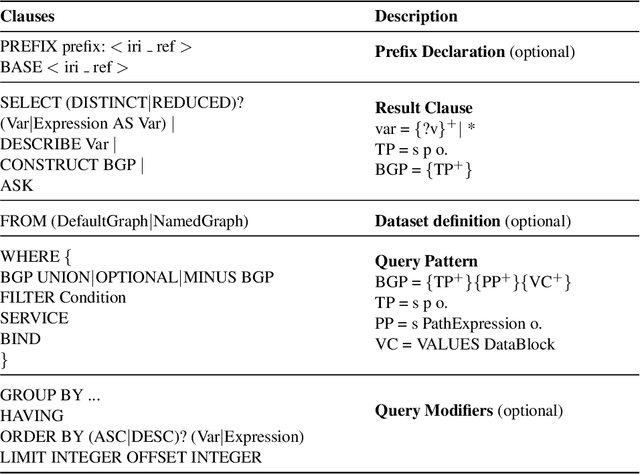
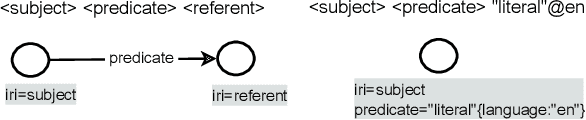

Resource Description Framework (RDF) and Property Graph (PG) are the two most commonly used data models for representing, storing, and querying graph data. We present Expressive Reasoning Graph Store (ERGS) -- a graph store built on top of JanusGraph (a Property Graph store) that also allows storing and querying of RDF datasets. First, we describe how RDF data can be translated into a Property Graph representation and then describe a query translation module that converts SPARQL queries into a series of Gremlin traversals. The converters and translators thus developed can allow any Apache Tinkerpop compliant graph database to store and query RDF datasets. We demonstrate the effectiveness of our proposed approach using JanusGraph as the base Property Graph store and compare its performance with standard RDF systems.