 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Symbolic Rules over Abstract Meaning Representations for Textual Reinforcement Learning
Jul 05, 2023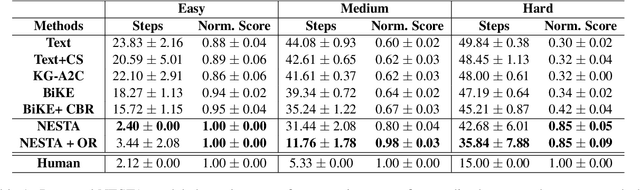
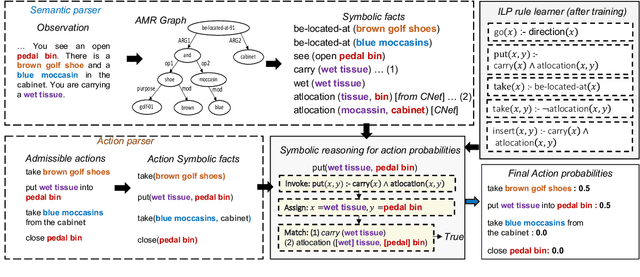
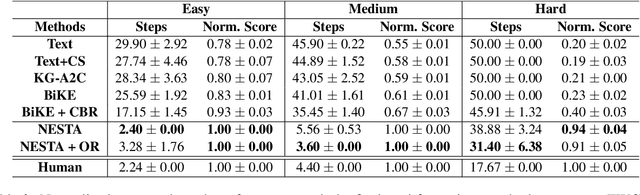
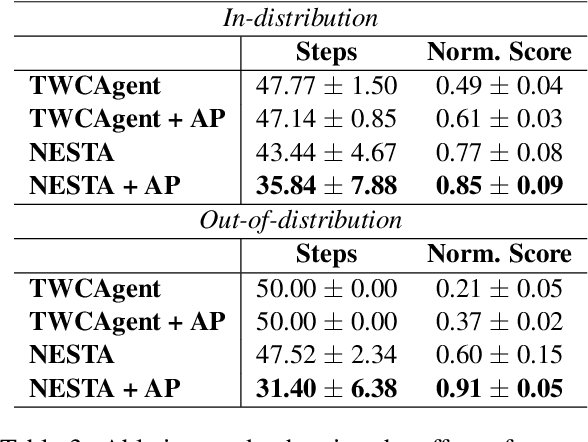
Text-based reinforcement learning agents have predominantly been neural network-based models with embeddings-based representation, learning uninterpretable policies that often do not generalize well to unseen games. On the other hand, neuro-symbolic methods, specifically those that leverage an intermediate formal representation, are gaining significant attention in language understanding tasks. This is because of their advantages ranging from inherent interpretability, the lesser requirement of training data, and being generalizable in scenarios with unseen data. Therefore, in this paper, we propose a modular, NEuro-Symbolic Textual Agent (NESTA) that combines a generic semantic parser with a rule induction system to learn abstract interpretable rules as policies. Our experiments on established text-based game benchmarks show that the proposed NESTA method outperforms deep reinforcement learning-based techniques by achieving better generalization to unseen test games and learning from fewer training interactions.
Are Human Explanations Always Helpful? Towards Objective Evaluation of Human Natural Language Explanations
May 04, 2023



Human-annotated labels and explanations are critical for training explainable NLP models. However, unlike human-annotated labels whose quality is easier to calibrate (e.g., with a majority vote), human-crafted free-form explanations can be quite subjective, as some recent works have discussed. Before blindly using them as ground truth to train ML models, a vital question needs to be asked: How do we evaluate a human-annotated explanation's quality? In this paper, we build on the view that the quality of a human-annotated explanation can be measured based on its helpfulness (or impairment) to the ML models' performance for the desired NLP tasks for which the annotations were collected. In comparison to the commonly used Simulatability score, we define a new metric that can take into consideration the helpfulness of an explanation for model performance at both fine-tuning and inference. With the help of a unified dataset format, we evaluated the proposed metric on five datasets (e.g., e-SNLI) against two model architectures (T5 and BART), and the results show that our proposed metric can objectively evaluate the quality of human-annotated explanations, while Simulatability falls short.
A Closer Look at the Calibration of Differentially Private Learners
Oct 15, 2022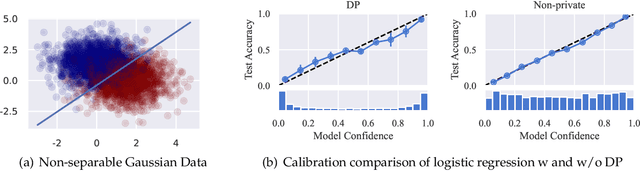
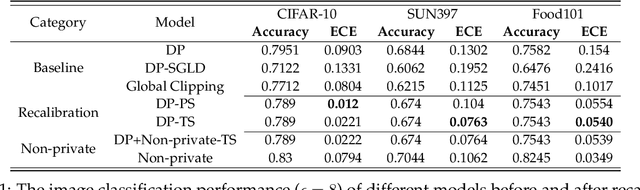
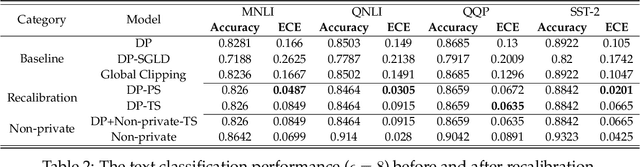
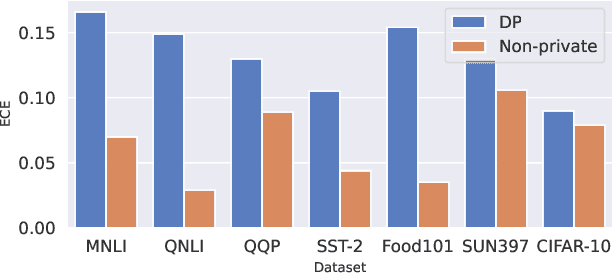
We systematically study the calibration of classifiers trained with differentially private stochastic gradient descent (DP-SGD) and observe miscalibration across a wide range of vision and language tasks. Our analysis identifies per-example gradient clipping in DP-SGD as a major cause of miscalibration, and we show that existing approaches for improving calibration with differential privacy only provide marginal improvements in calibration error while occasionally causing large degradations in accuracy. As a solution, we show that differentially private variants of post-processing calibration methods such as temperature scaling and Platt scaling are surprisingly effective and have negligible utility cost to the overall model. Across 7 tasks, temperature scaling and Platt scaling with DP-SGD result in an average 3.1-fold reduction in the in-domain expected calibration error and only incur at most a minor percent drop in accuracy.
Neuro-Symbolic Inductive Logic Programming with Logical Neural Networks
Dec 06, 2021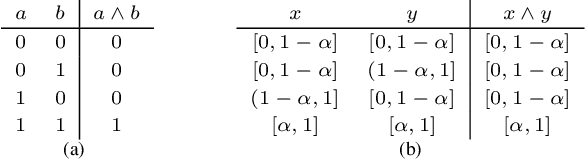

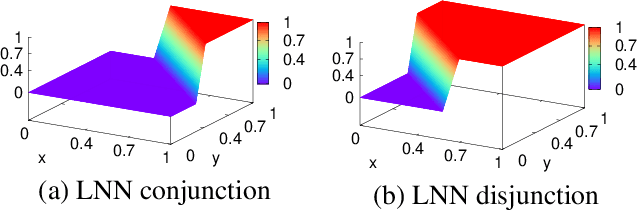
Recent work on neuro-symbolic inductive logic programming has led to promising approaches that can learn explanatory rules from noisy, real-world data. While some proposals approximate logical operators with differentiable operators from fuzzy or real-valued logic that are parameter-free thus diminishing their capacity to fit the data, other approaches are only loosely based on logic making it difficult to interpret the learned "rules". In this paper, we propose learning rules with the recently proposed logical neural networks (LNN). Compared to others, LNNs offer strong connection to classical Boolean logic thus allowing for precise interpretation of learned rules while harboring parameters that can be trained with gradient-based optimization to effectively fit the data. We extend LNNs to induce rules in first-order logic. Our experiments on standard benchmarking tasks confirm that LNN rules are highly interpretable and can achieve comparable or higher accuracy due to their flexible parameterization.
Combining Rules and Embeddings via Neuro-Symbolic AI for Knowledge Base Completion
Sep 16, 2021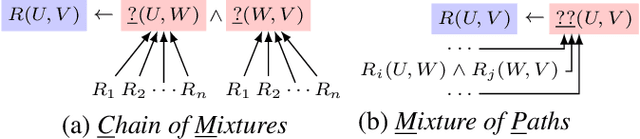
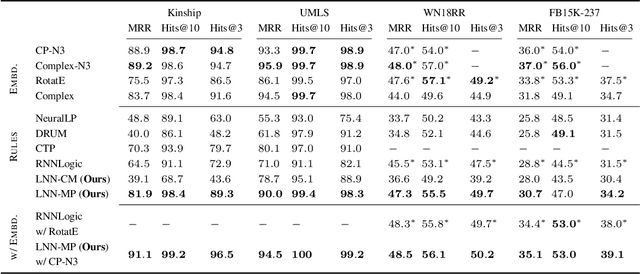
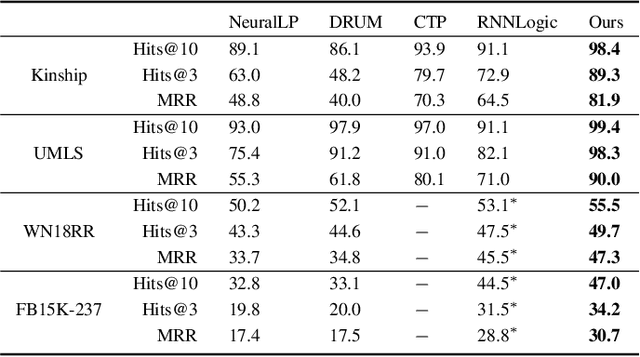
Recent interest in Knowledge Base Completion (KBC) has led to a plethora of approaches based on reinforcement learning, inductive logic programming and graph embeddings. In particular, rule-based KBC has led to interpretable rules while being comparable in performance with graph embeddings. Even within rule-based KBC, there exist different approaches that lead to rules of varying quality and previous work has not always been precise in highlighting these differences. Another issue that plagues most rule-based KBC is the non-uniformity of relation paths: some relation sequences occur in very few paths while others appear very frequently. In this paper, we show that not all rule-based KBC models are the same and propose two distinct approaches that learn in one case: 1) a mixture of relations and the other 2) a mixture of paths. When implemented on top of neuro-symbolic AI, which learns rules by extending Boolean logic to real-valued logic, the latter model leads to superior KBC accuracy outperforming state-of-the-art rule-based KBC by 2-10% in terms of mean reciprocal rank. Furthermore, to address the non-uniformity of relation paths, we combine rule-based KBC with graph embeddings thus improving our results even further and achieving the best of both worlds.
LNN-EL: A Neuro-Symbolic Approach to Short-text Entity Linking
Jun 17, 2021
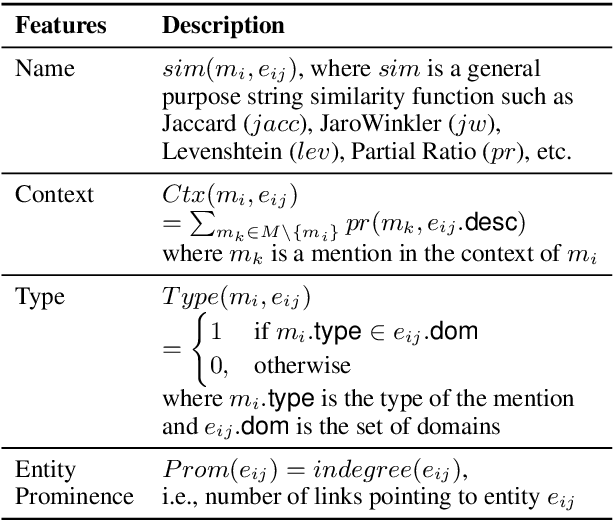
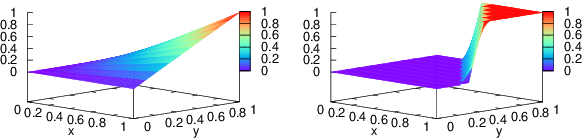
Entity linking (EL), the task of disambiguating mentions in text by linking them to entities in a knowledge graph, is crucial for text understanding, question answering or conversational systems. Entity linking on short text (e.g., single sentence or question) poses particular challenges due to limited context. While prior approaches use either heuristics or black-box neural methods, here we propose LNN-EL, a neuro-symbolic approach that combines the advantages of using interpretable rules based on first-order logic with the performance of neural learning. Even though constrained to using rules, LNN-EL performs competitively against SotA black-box neural approaches, with the added benefits of extensibility and transferability. In particular, we show that we can easily blend existing rule templates given by a human expert, with multiple types of features (priors, BERT encodings, box embeddings, etc), and even scores resulting from previous EL methods, thus improving on such methods. For instance, on the LC-QuAD-1.0 dataset, we show more than $4$\% increase in F1 score over previous SotA. Finally, we show that the inductive bias offered by using logic results in learned rules that transfer well across datasets, even without fine tuning, while maintaining high accuracy.
Deep Indexed Active Learning for Matching Heterogeneous Entity Representations
Apr 08, 2021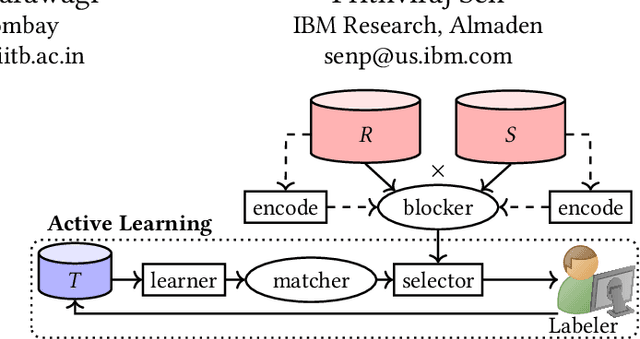
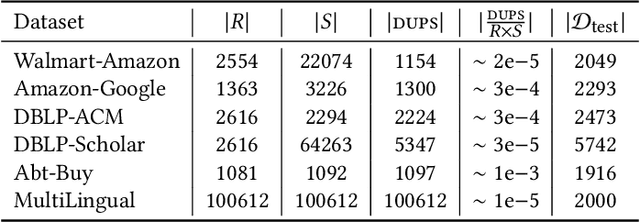
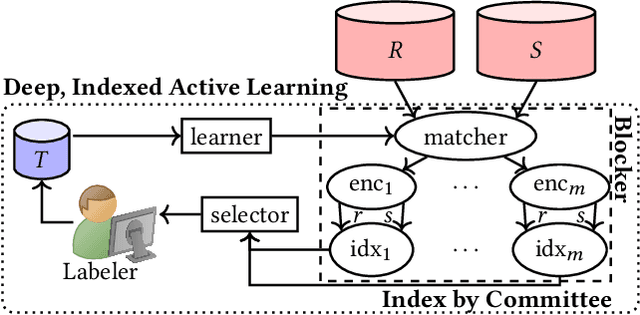
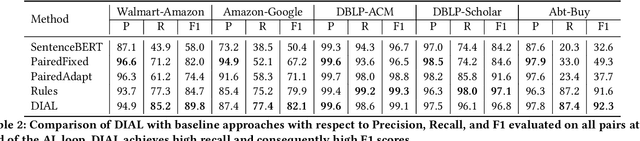
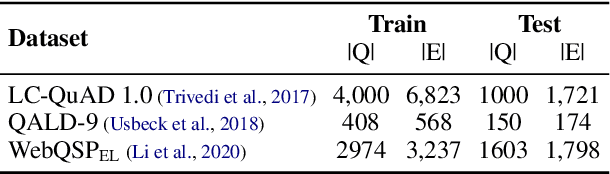
Given two large lists of records, the task in entity resolution (ER) is to find the pairs from the Cartesian product of the lists that correspond to the same real world entity. Typically, passive learning methods on tasks like ER require large amounts of labeled data to yield useful models. Active Learning is a promising approach for ER in low resource settings. However, the search space, to find informative samples for the user to label, grows quadratically for instance-pair tasks making active learning hard to scale. Previous works, in this setting, rely on hand-crafted predicates, pre-trained language model embeddings, or rule learning to prune away unlikely pairs from the Cartesian product. This blocking step can miss out on important regions in the product space leading to low recall. We propose DIAL, a scalable active learning approach that jointly learns embeddings to maximize recall for blocking and accuracy for matching blocked pairs. DIAL uses an Index-By-Committee framework, where each committee member learns representations based on powerful transformer models. We highlight surprising differences between the matcher and the blocker in the creation of the training data and the objective used to train their parameters. Experiments on five benchmark datasets and a multilingual record matching dataset show the effectiveness of our approach in terms of precision, recall and running time. Code is available at https://github.com/ArjitJ/DIAL
Logic Embeddings for Complex Query Answering
Feb 28, 2021Answering logical queries over incomplete knowledge bases is challenging because: 1) it calls for implicit link prediction, and 2) brute force answering of existential first-order logic queries is exponential in the number of existential variables. Recent work of query embeddings provides fast querying, but most approaches model set logic with closed regions, so lack negation. Query embeddings that do support negation use densities that suffer drawbacks: 1) only improvise logic, 2) use expensive distributions, and 3) poorly model answer uncertainty. In this paper, we propose Logic Embeddings, a new approach to embedding complex queries that uses Skolemisation to eliminate existential variables for efficient querying. It supports negation, but improves on density approaches: 1) integrates well-studied t-norm logic and directly evaluates satisfiability, 2) simplifies modeling with truth values, and 3) models uncertainty with truth bounds. Logic Embeddings are competitively fast and accurate in query answering over large, incomplete knowledge graphs, outperform on negation queries, and in particular, provide improved modeling of answer uncertainty as evidenced by a superior correlation between answer set size and embedding entropy.
A Survey of the State of Explainable AI for Natural Language Processing
Oct 01, 2020

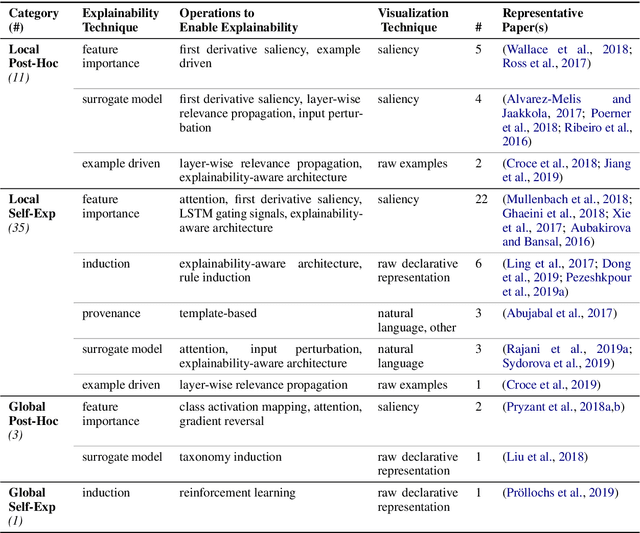

Recent years have seen important advances in the quality of state-of-the-art models, but this has come at the expense of models becoming less interpretable. This survey presents an overview of the current state of Explainable AI (XAI), considered within the domain of Natural Language Processing (NLP). We discuss the main categorization of explanations, as well as the various ways explanations can be arrived at and visualized. We detail the operations and explainability techniques currently available for generating explanations for NLP model predictions, to serve as a resource for model developers in the community. Finally, we point out the current gaps and encourage directions for future work in this important research area.
Forecasting in multivariate irregularly sampled time series with missing values
Apr 06, 2020

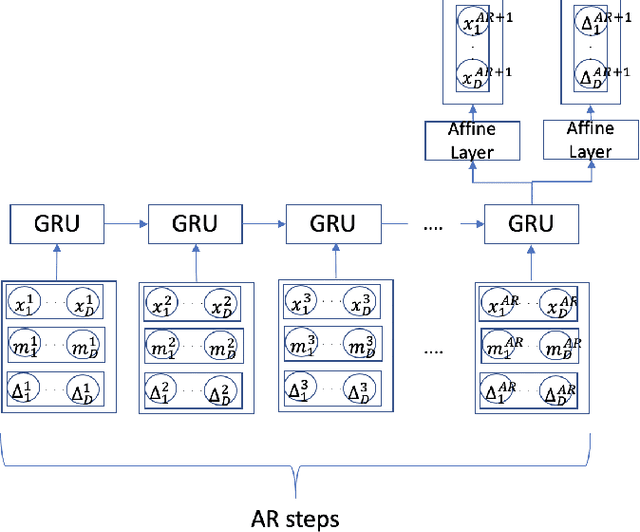
Sparse and irregularly sampled multivariate time series are common in clinical, climate, financial and many other domains. Most recent approaches focus on classification, regression or forecasting tasks on such data. In forecasting, it is necessary to not only forecast the right value but also to forecast when that value will occur in the irregular time series. In this work, we present an approach to forecast not only the values but also the time at which they are expected to occur.