 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Knowledge Graph Embedding Models
Jan 08, 2022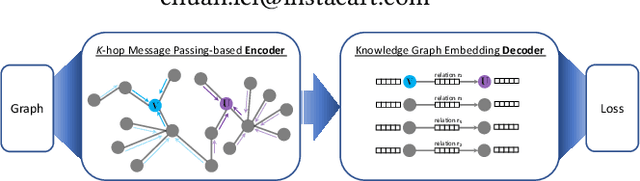
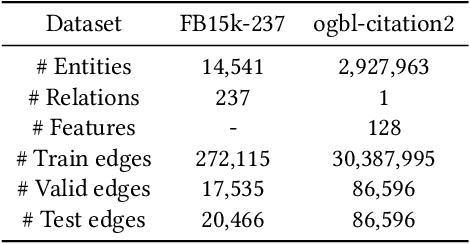
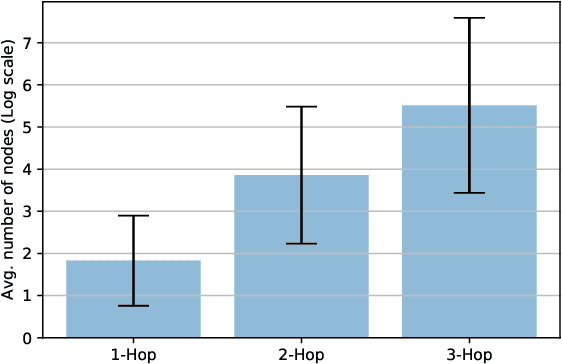
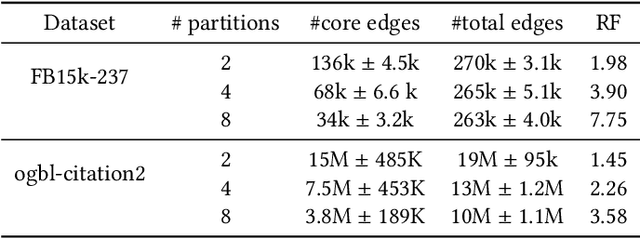
Developing scalable solutions for training Graph Neural Networks (GNNs) for link prediction tasks is challenging due to the high data dependencies which entail high computational cost and huge memory footprint. We propose a new method for scaling training of knowledge graph embedding models for link prediction to address these challenges. Towards this end, we propose the following algorithmic strategies: self-sufficient partitions, constraint-based negative sampling, and edge mini-batch training. Both, partitioning strategy and constraint-based negative sampling, avoid cross partition data transfer during training. In our experimental evaluation, we show that our scaling solution for GNN-based knowledge graph embedding models achieves a 16x speed up on benchmark datasets while maintaining a comparable model performance as non-distributed methods on standard metrics.
Knowledge Graph Embedding using Graph Convolutional Networks with Relation-Aware Attention
Feb 14, 2021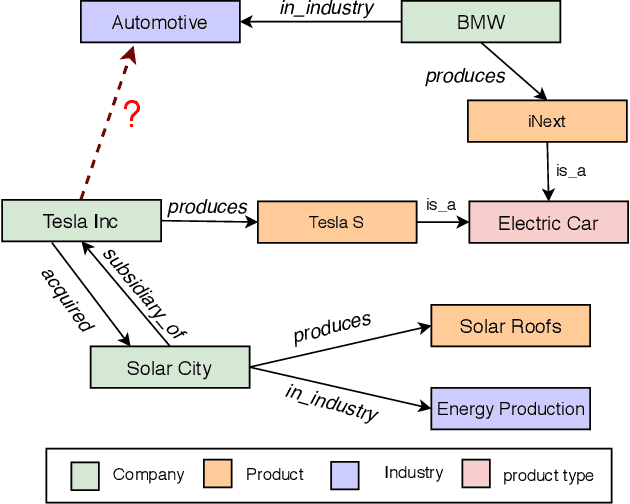
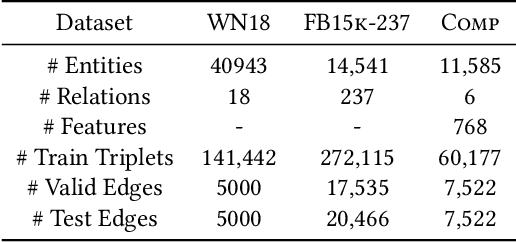
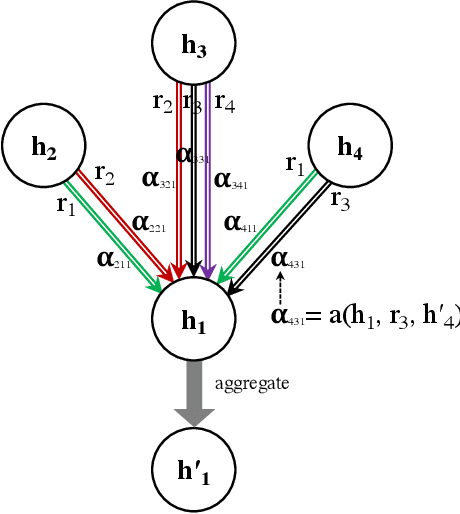
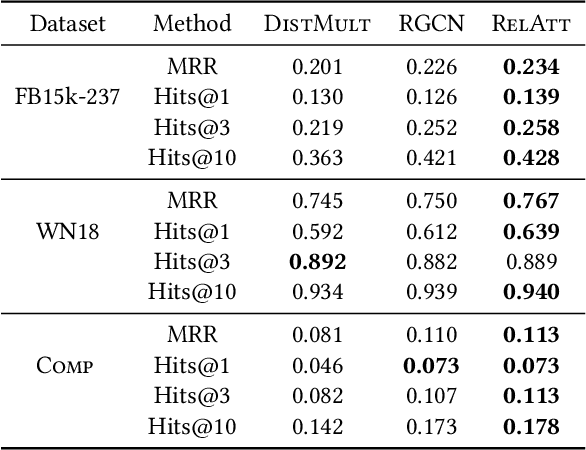
Knowledge graph embedding methods learn embeddings of entities and relations in a low dimensional space which can be used for various downstream machine learning tasks such as link prediction and entity matching. Various graph convolutional network methods have been proposed which use different types of information to learn the features of entities and relations. However, these methods assign the same weight (importance) to the neighbors when aggregating the information, ignoring the role of different relations with the neighboring entities. To this end, we propose a relation-aware graph attention model that leverages relation information to compute different weights to the neighboring nodes for learning embeddings of entities and relations. We evaluate our proposed approach on link prediction and entity matching tasks. Our experimental results on link prediction on three datasets (one proprietary and two public) and results on unsupervised entity matching on one proprietary dataset demonstrate the effectiveness of the relation-aware attention.
Relation-aware Graph Attention Model With Adaptive Self-adversarial Training
Feb 14, 2021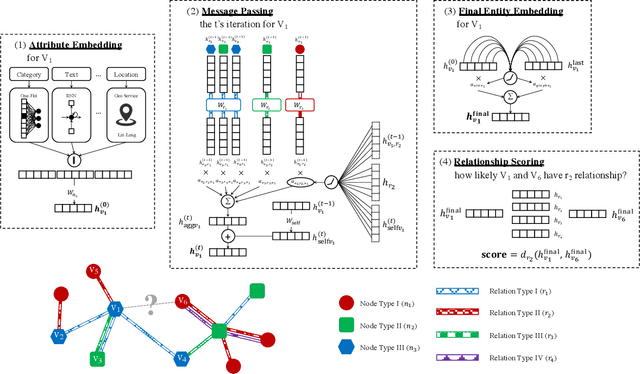


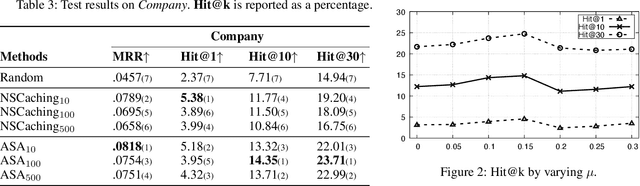
This paper describes an end-to-end solution for the relationship prediction task in heterogeneous, multi-relational graphs. We particularly address two building blocks in the pipeline, namely heterogeneous graph representation learning and negative sampling. Existing message passing-based graph neural networks use edges either for graph traversal and/or selection of message encoding functions. Ignoring the edge semantics could have severe repercussions on the quality of embeddings, especially when dealing with two nodes having multiple relations. Furthermore, the expressivity of the learned representation depends on the quality of negative samples used during training. Although existing hard negative sampling techniques can identify challenging negative relationships for optimization, new techniques are required to control false negatives during training as false negatives could corrupt the learning process. To address these issues, first, we propose RelGNN -- a message passing-based heterogeneous graph attention model. In particular, RelGNN generates the states of different relations and leverages them along with the node states to weigh the messages. RelGNN also adopts a self-attention mechanism to balance the importance of attribute features and topological features for generating the final entity embeddings. Second, we introduce a parameter-free negative sampling technique -- adaptive self-adversarial (ASA) negative sampling. ASA reduces the false-negative rate by leveraging positive relationships to effectively guide the identification of true negative samples. Our experimental evaluation demonstrates that RelGNN optimized by ASA for relationship prediction improves state-of-the-art performance across established benchmarks as well as on a real industrial dataset.
Forecasting in multivariate irregularly sampled time series with missing values
Apr 06, 2020

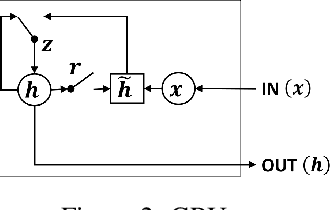
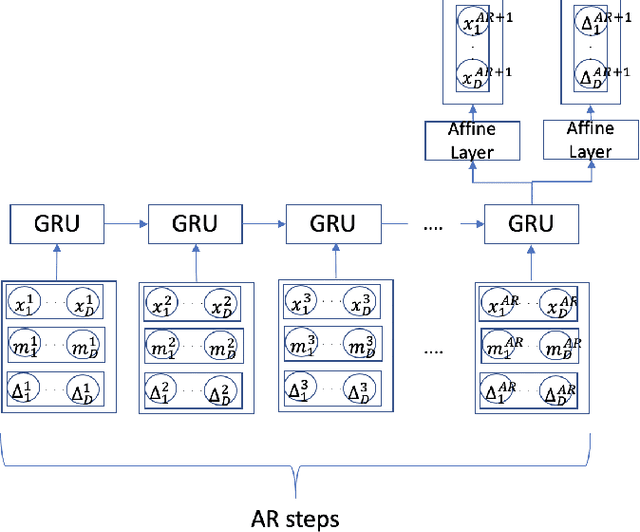
Sparse and irregularly sampled multivariate time series are common in clinical, climate, financial and many other domains. Most recent approaches focus on classification, regression or forecasting tasks on such data. In forecasting, it is necessary to not only forecast the right value but also to forecast when that value will occur in the irregular time series. In this work, we present an approach to forecast not only the values but also the time at which they are expected to occur.
A Neural Architecture for Person Ontology population
Jan 22, 2020
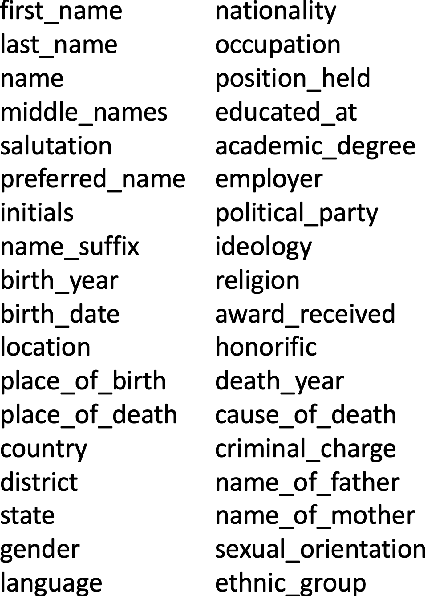

A person ontology comprising concepts, attributes and relationships of people has a number of applications in data protection, didentification, population of knowledge graphs for business intelligence and fraud prevention. While artificial neural networks have led to improvements in Entity Recognition, Entity Classification, and Relation Extraction, creating an ontology largely remains a manual process, because it requires a fixed set of semantic relations between concepts. In this work, we present a system for automatically populating a person ontology graph from unstructured data using neural models for Entity Classification and Relation Extraction. We introduce a new dataset for these tasks and discuss our results.
Fine Grained Classification of Personal Data Entities
Nov 23, 2018
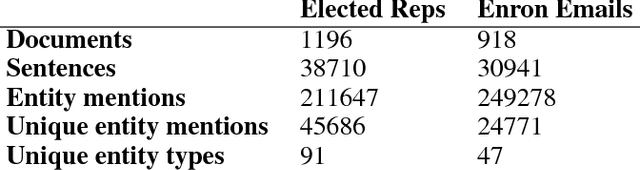
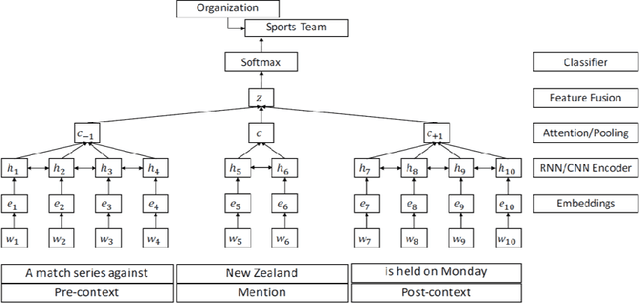
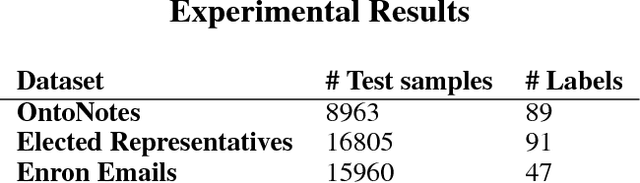
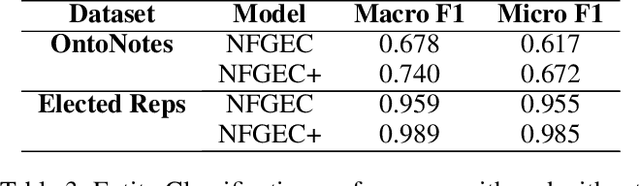
Entity Type Classification can be defined as the task of assigning category labels to entity mentions in documents. While neural networks have recently improved the classification of general entity mentions, pattern matching and other systems continue to be used for classifying personal data entities (e.g. classifying an organization as a media company or a government institution for GDPR, and HIPAA compliance). We propose a neural model to expand the class of personal data entities that can be classified at a fine grained level, using the output of existing pattern matching systems as additional contextual features. We introduce new resources, a personal data entities hierarchy with 134 types, and two datasets from the Wikipedia pages of elected representatives and Enron emails. We hope these resource will aid research in the area of personal data discovery, and to that effect, we provide baseline results on these datasets, and compare our method with state of the art models on OntoNotes dataset.
Deep Learning with Apache SystemML
Feb 08, 2018Enterprises operate large data lakes using Hadoop and Spark frameworks that (1) run a plethora of tools to automate powerful data preparation/transformation pipelines, (2) run on shared, large clusters to (3) perform many different analytics tasks ranging from model preparation, building, evaluation, and tuning for both machine learning and deep learning. Developing machine/deep learning models on data in such shared environments is challenging. Apache SystemML provides a unified framework for implementing machine learning and deep learning algorithms in a variety of shared deployment scenarios. SystemML's novel compilation approach automatically generates runtime execution plans for machine/deep learning algorithms that are composed of single-node and distributed runtime operations depending on data and cluster characteristics such as data size, data sparsity, cluster size, and memory configurations, while still exploiting the capabilities of the underlying big data frameworks.
Declarative Machine Learning - A Classification of Basic Properties and Types
May 19, 2016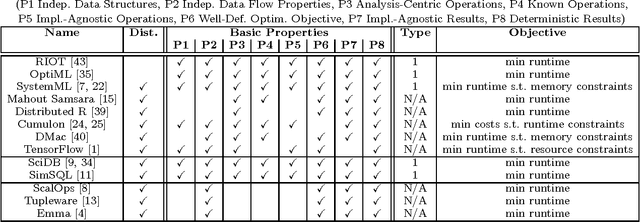

Declarative machine learning (ML) aims at the high-level specification of ML tasks or algorithms, and automatic generation of optimized execution plans from these specifications. The fundamental goal is to simplify the usage and/or development of ML algorithms, which is especially important in the context of large-scale computations. However, ML systems at different abstraction levels have emerged over time and accordingly there has been a controversy about the meaning of this general definition of declarative ML. Specification alternatives range from ML algorithms expressed in domain-specific languages (DSLs) with optimization for performance, to ML task (learning problem) specifications with optimization for performance and accuracy. We argue that these different types of declarative ML complement each other as they address different users (data scientists and end users). This paper makes an attempt to create a taxonomy for declarative ML, including a definition of essential basic properties and types of declarative ML. Along the way, we provide insights into implications of these properties. We also use this taxonomy to classify existing systems. Finally, we draw conclusions on defining appropriate benchmarks and specification languages for declarative ML.