 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimal-Intervention KV Retention: A Design-Space Study and a Diversity-Penalty Survivor
May 14, 2026KV-cache compression at small budgets is a crowded design space spanning cache representation, head-wise routing, compression cadence, decoding behavior, and within-budget scoring. We study seven mechanisms across these five families under matched mean cache on long-form mathematical reasoning (MATH-500~\cite{hendrycks2021math}) with two distilled-reasoning models (Qwen-7B and Llama-8B variants of DeepSeek-R1-Distill~\cite{deepseek2025r1}) at budgets $b \in \{64, 128\}$. All seven were rejected. We then propose $α$, a one-function modification to the TriAttention~\cite{mao2026triattention} retention scorer that replaces argmax-top-$k$ with greedy facility-location-inspired selection under a V-space redundancy penalty controlled by a single weight $λ$. A pre-registered protocol tunes $λ$ on a frozen development split and confirms on a disjoint held-out split; with $λ= 0.5$, $α$ clears Bonferroni on two of the four (model, budget) cells (Qwen $b{=}128$ and Llama $b{=}64$), no cell is significantly negative, and the pre-registered Branch~A triggers. The finding is asymmetric: a minimal scoring modification beat heavier structural redesigns in this regime, and the combined matched-memory, sympy-graded, held-out confirmation protocol is the evidence standard that made the asymmetry visible.
MoE-nD: Per-Layer Mixture-of-Experts Routing for Multi-Axis KV Cache Compression
Apr 20, 2026KV cache memory is the dominant bottleneck for long-context LLM inference. Existing compression methods each act on a single axis of the four-dimensional KV tensor -- token eviction (sequence), quantization (precision), low-rank projection (head dimension), or cross-layer sharing -- but apply the same recipe to every layer. We show that this homogeneity leaves accuracy on the table: different layers respond very differently to each compression operation, and the optimal per-layer mix of eviction and quantization is far from uniform. We propose MoE-nD, a mixture-of-experts framework that routes each layer to its own (eviction-ratio, K-bits, V-bits) tuple under a global memory budget. An offline-calibrated greedy solver chooses the routing that minimizes predicted quality loss; at inference time, per-layer heterogeneous eviction and quantization are applied jointly through a single attention patch. On a 4-task subset of LongBench-v1 (16k inputs, n=50 per task, adapted reasoning-model protocol; see section Experiments), MoE-nD's hetero variant matches our uncompressed 1.9~GB baseline at 14x compression (136~MB) while every other compressed baseline we tested (1d, 2d_uniform, 2d) at comparable or smaller memory stays under 8/100. The gains hold on AIME reasoning benchmarks (+6 to +27 pts over the strongest per-layer-quantization baseline across eight configurations). Two null results -- MATH-500 and LongBench's TREC -- share a principled cause (short inputs, solver picks keep=1.0 on most layers), cleanly characterizing when per-layer eviction routing has headroom to help.
LoRM: Learning the Language of Rotating Machinery for Self-Supervised Condition Monitoring
Apr 07, 2026We present LoRM (Language of Rotating Machinery), a self-supervised framework for multi-modal rotating-machinery signal understanding and real-time condition monitoring. LoRM is built on the idea that rotating-machinery signals can be viewed as a machine language: local signals can be tokenised into discrete symbolic units, and their future evolution can be predicted from observed multi-sensor context. Unlike conventional signal-processing methods that rely on hand-crafted transforms and features, LoRM reformulates multi-modal sensor data as a token-based sequence-prediction problem. For each data window, the observed context segment is retained in continuous form, while the future target segment of each sensing channel is quantised into a discrete token. Then, efficient knowledge transfer is achieved by partially fine-tuning a general-purpose pre-trained language model on industrial signals, avoiding the need to train a large model from scratch. Finally, condition monitoring is performed by tracking token-prediction errors as a health indicator, where increasing errors indicate degradation. In-situ tool condition monitoring (TCM) experiments demonstrate stable real-time tracking and strong cross-tool generalisation, showing that LoRM provides a practical bridge between language modelling and industrial signal analysis. The source code is publicly available at https://github.com/Q159753258/LormPHM.
Learning to Select Like Humans: Explainable Active Learning for Medical Imaging
Feb 10, 2026Medical image analysis requires substantial labeled data for model training, yet expert annotation is expensive and time-consuming. Active learning (AL) addresses this challenge by strategically selecting the most informative samples for the annotation purpose, but traditional methods solely rely on predictive uncertainty while ignoring whether models learn from clinically meaningful features a critical requirement for clinical deployment. We propose an explainability-guided active learning framework that integrates spatial attention alignment into a sample acquisition process. Our approach advocates for a dual-criterion selection strategy combining: (i) classification uncertainty to identify informative examples, and (ii) attention misalignment with radiologist-defined regions-of-interest (ROIs) to target samples where the model focuses on incorrect features. By measuring misalignment between Grad-CAM attention maps and expert annotations using \emph{Dice similarity}, our acquisition function judiciously identifies samples that enhance both predictive performance and spatial interpretability. We evaluate the framework using three expert-annotated medical imaging datasets, namely, BraTS (MRI brain tumors), VinDr-CXR (chest X-rays), and SIIM-COVID-19 (chest X-rays). Using only 570 strategically selected samples, our explainability-guided approach consistently outperforms random sampling across all the datasets, achieving 77.22\% accuracy on BraTS, 52.37\% on VinDr-CXR, and 52.66\% on SIIM-COVID. Grad-CAM visualizations confirm that the models trained by our dual-criterion selection focus on diagnostically relevant regions, demonstrating that incorporating explanation guidance into sample acquisition yields superior data efficiency while maintaining clinical interpretability.
AgentSM: Semantic Memory for Agentic Text-to-SQL
Jan 22, 2026Recent advances in LLM-based Text-to-SQL have achieved remarkable gains on public benchmarks such as BIRD and Spider. Yet, these systems struggle to scale in realistic enterprise settings with large, complex schemas, diverse SQL dialects, and expensive multi-step reasoning. Emerging agentic approaches show potential for adaptive reasoning but often suffer from inefficiency and instability-repeating interactions with databases, producing inconsistent outputs, and occasionally failing to generate valid answers. To address these challenges, we introduce Agent Semantic Memory (AgentSM), an agentic framework for Text-to-SQL that builds and leverages interpretable semantic memory. Instead of relying on raw scratchpads or vector retrieval, AgentSM captures prior execution traces-or synthesizes curated ones-as structured programs that directly guide future reasoning. This design enables systematic reuse of reasoning paths, which allows agents to scale to larger schemas, more complex questions, and longer trajectories efficiently and reliably. Compared to state-of-the-art systems, AgentSM achieves higher efficiency by reducing average token usage and trajectory length by 25% and 35%, respectively, on the Spider 2.0 benchmark. It also improves execution accuracy, reaching a state-of-the-art accuracy of 44.8% on the Spider 2.0 Lite benchmark.
SQLens: An End-to-End Framework for Error Detection and Correction in Text-to-SQL
Jun 04, 2025Text-to-SQL systems translate natural language (NL) questions into SQL queries, enabling non-technical users to interact with structured data. While large language models (LLMs) have shown promising results on the text-to-SQL task, they often produce semantically incorrect yet syntactically valid queries, with limited insight into their reliability. We propose SQLens, an end-to-end framework for fine-grained detection and correction of semantic errors in LLM-generated SQL. SQLens integrates error signals from both the underlying database and the LLM to identify potential semantic errors within SQL clauses. It further leverages these signals to guide query correction. Empirical results on two public benchmarks show that SQLens outperforms the best LLM-based self-evaluation method by 25.78% in F1 for error detection, and improves execution accuracy of out-of-the-box text-to-SQL systems by up to 20%.
TailorSQL: An NL2SQL System Tailored to Your Query Workload
May 29, 2025NL2SQL (natural language to SQL) translates natural language questions into SQL queries, thereby making structured data accessible to non-technical users, serving as the foundation for intelligent data applications. State-of-the-art NL2SQL techniques typically perform translation by retrieving database-specific information, such as the database schema, and invoking a pre-trained large language model (LLM) using the question and retrieved information to generate the SQL query. However, existing NL2SQL techniques miss a key opportunity which is present in real-world settings: NL2SQL is typically applied on existing databases which have already served many SQL queries in the past. The past query workload implicitly contains information which is helpful for accurate NL2SQL translation and is not apparent from the database schema alone, such as common join paths and the semantics of obscurely-named tables and columns. We introduce TailorSQL, a NL2SQL system that takes advantage of information in the past query workload to improve both the accuracy and latency of translating natural language questions into SQL. By specializing to a given workload, TailorSQL achieves up to 2$\times$ improvement in execution accuracy on standardized benchmarks.
ODIN: A NL2SQL Recommender to Handle Schema Ambiguity
May 25, 2025NL2SQL (natural language to SQL) systems translate natural language into SQL queries, allowing users with no technical background to interact with databases and create tools like reports or visualizations. While recent advancements in large language models (LLMs) have significantly improved NL2SQL accuracy, schema ambiguity remains a major challenge in enterprise environments with complex schemas, where multiple tables and columns with semantically similar names often co-exist. To address schema ambiguity, we introduce ODIN, a NL2SQL recommendation engine. Instead of producing a single SQL query given a natural language question, ODIN generates a set of potential SQL queries by accounting for different interpretations of ambiguous schema components. ODIN dynamically adjusts the number of suggestions based on the level of ambiguity, and ODIN learns from user feedback to personalize future SQL query recommendations. Our evaluation shows that ODIN improves the likelihood of generating the correct SQL query by 1.5-2$\times$ compared to baselines.
FeatNavigator: Automatic Feature Augmentation on Tabular Data
Jun 13, 2024Data-centric AI focuses on understanding and utilizing high-quality, relevant data in training machine learning (ML) models, thereby increasing the likelihood of producing accurate and useful results. Automatic feature augmentation, aiming to augment the initial base table with useful features from other tables, is critical in data preparation as it improves model performance, robustness, and generalizability. While recent works have investigated automatic feature augmentation, most of them have limited capabilities in utilizing all useful features as many of them are in candidate tables not directly joinable with the base table. Worse yet, with numerous join paths leading to these distant features, existing solutions fail to fully exploit them within a reasonable compute budget. We present FeatNavigator, an effective and efficient framework that explores and integrates high-quality features in relational tables for ML models. FeatNavigator evaluates a feature from two aspects: (1) the intrinsic value of a feature towards an ML task (i.e., feature importance) and (2) the efficacy of a join path connecting the feature to the base table (i.e., integration quality). FeatNavigator strategically selects a small set of available features and their corresponding join paths to train a feature importance estimation model and an integration quality prediction model. Furthermore, FeatNavigator's search algorithm exploits both estimated feature importance and integration quality to identify the optimized feature augmentation plan. Our experimental results show that FeatNavigator outperforms state-of-the-art solutions on five public datasets by up to 40.1% in ML model performance.
4DBInfer: A 4D Benchmarking Toolbox for Graph-Centric Predictive Modeling on Relational DBs
Apr 28, 2024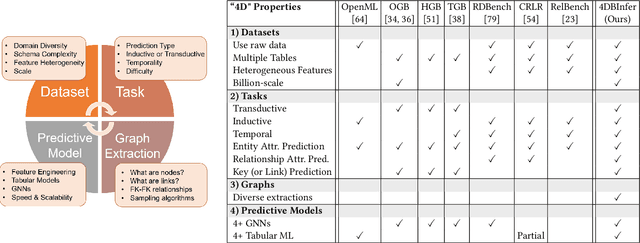
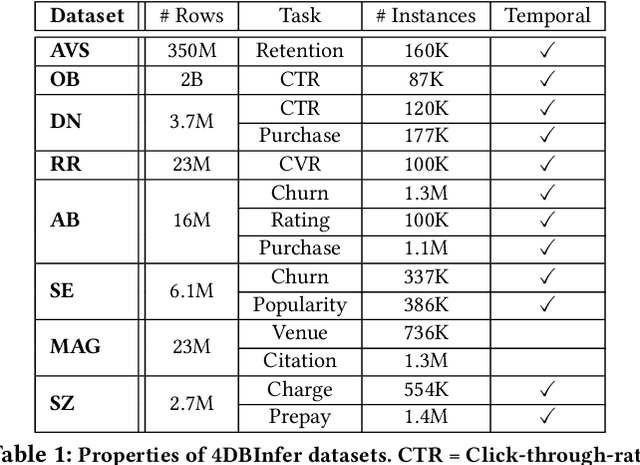
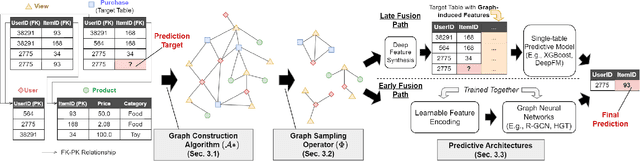
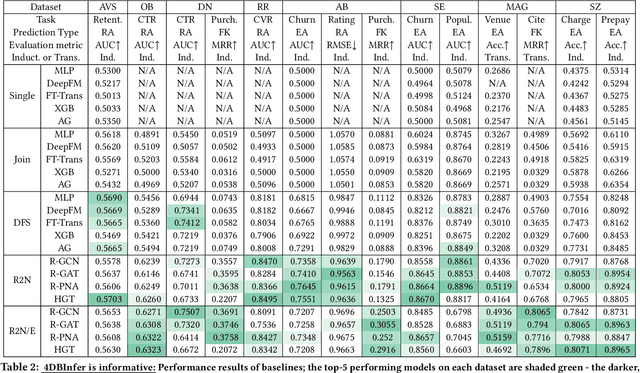
Although RDBs store vast amounts of rich, informative data spread across interconnected tables, the progress of predictive machine learning models as applied to such tasks arguably falls well behind advances in other domains such as computer vision or natural language processing. This deficit stems, at least in part, from the lack of established/public RDB benchmarks as needed for training and evaluation purposes. As a result, related model development thus far often defaults to tabular approaches trained on ubiquitous single-table benchmarks, or on the relational side, graph-based alternatives such as GNNs applied to a completely different set of graph datasets devoid of tabular characteristics. To more precisely target RDBs lying at the nexus of these two complementary regimes, we explore a broad class of baseline models predicated on: (i) converting multi-table datasets into graphs using various strategies equipped with efficient subsampling, while preserving tabular characteristics; and (ii) trainable models with well-matched inductive biases that output predictions based on these input subgraphs. Then, to address the dearth of suitable public benchmarks and reduce siloed comparisons, we assemble a diverse collection of (i) large-scale RDB datasets and (ii) coincident predictive tasks. From a delivery standpoint, we operationalize the above four dimensions (4D) of exploration within a unified, scalable open-source toolbox called 4DBInfer. We conclude by presenting evaluations using 4DBInfer, the results of which highlight the importance of considering each such dimension in the design of RDB predictive models, as well as the limitations of more naive approaches such as simply joining adjacent tables. Our source code is released at https://github.com/awslabs/multi-table-benchmark .