 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning MR-Sort Models from Non-Monotone Data
Jul 20, 2021
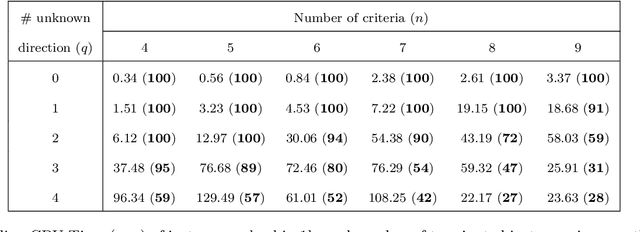
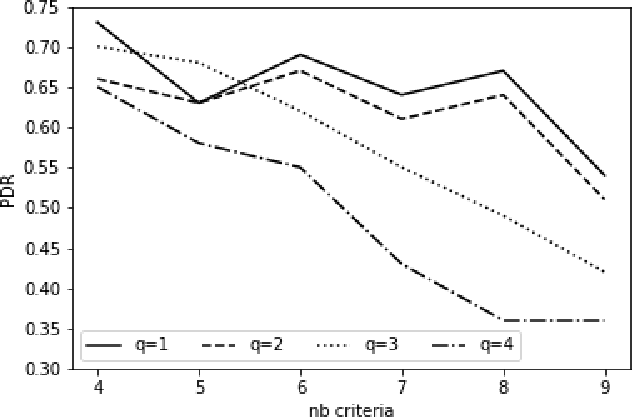

The Majority Rule Sorting (MR-Sort) method assigns alternatives evaluated on multiple criteria to one of the predefined ordered categories. The Inverse MR-Sort problem (Inv-MR-Sort) computes MR-Sort parameters that match a dataset. Existing learning algorithms for Inv-MR-Sort consider monotone preferences on criteria. We extend this problem to the case where the preferences on criteria are not necessarily monotone, but possibly single-peaked (or single-valley). We propose a mixed-integer programming based algorithm that learns the preferences on criteria together with the other MR-Sort parameters from the training data. We investigate the performance of the algorithm using numerical experiments and we illustrate its use on a real-world case study.
Business Entity Matching with Siamese Graph Convolutional Networks
May 08, 2021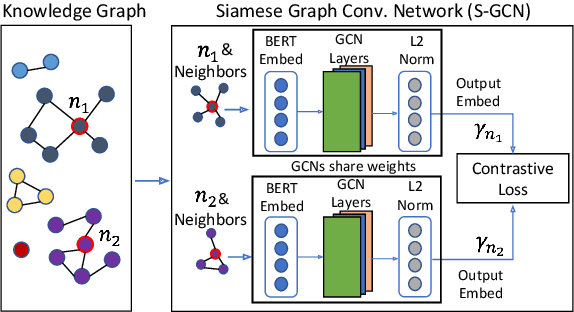

Data integration has been studied extensively for decades and approached from different angles. However, this domain still remains largely rule-driven and lacks universal automation. Recent developments in machine learning and in particular deep learning have opened the way to more general and efficient solutions to data-integration tasks. In this paper, we demonstrate an approach that allows modeling and integrating entities by leveraging their relations and contextual information. This is achieved by combining siamese and graph neural networks to effectively propagate information between connected entities and support high scalability. We evaluated our approach on the task of integrating data about business entities, demonstrating that it outperforms both traditional rule-based systems and other deep learning approaches.
Knowledge Graph Embedding using Graph Convolutional Networks with Relation-Aware Attention
Feb 14, 2021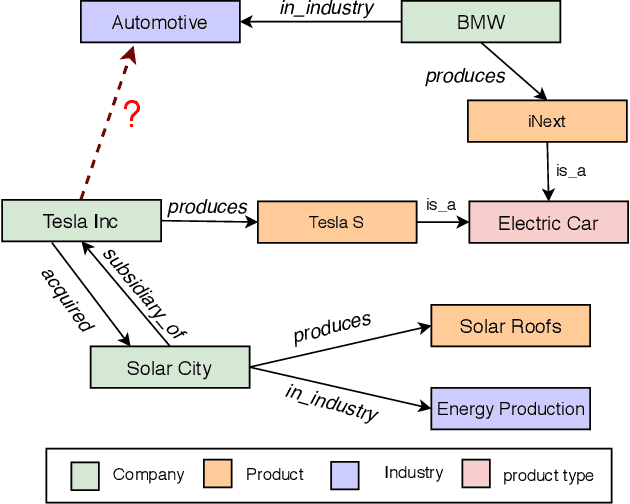
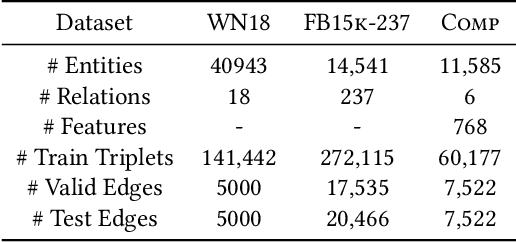
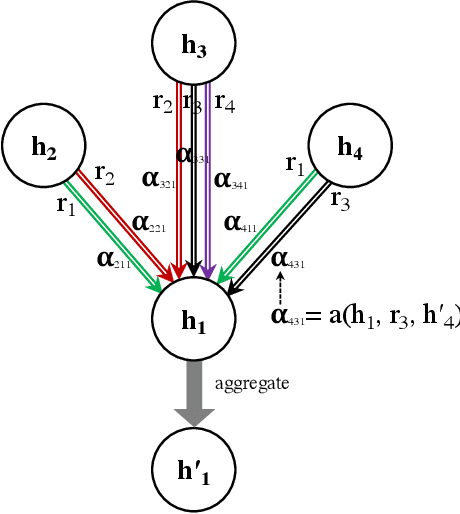
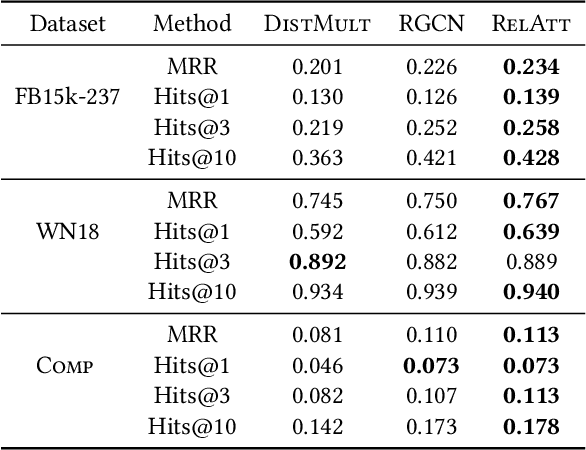
Knowledge graph embedding methods learn embeddings of entities and relations in a low dimensional space which can be used for various downstream machine learning tasks such as link prediction and entity matching. Various graph convolutional network methods have been proposed which use different types of information to learn the features of entities and relations. However, these methods assign the same weight (importance) to the neighbors when aggregating the information, ignoring the role of different relations with the neighboring entities. To this end, we propose a relation-aware graph attention model that leverages relation information to compute different weights to the neighboring nodes for learning embeddings of entities and relations. We evaluate our proposed approach on link prediction and entity matching tasks. Our experimental results on link prediction on three datasets (one proprietary and two public) and results on unsupervised entity matching on one proprietary dataset demonstrate the effectiveness of the relation-aware attention.
Siamese Graph Neural Networks for Data Integration
Jan 17, 2020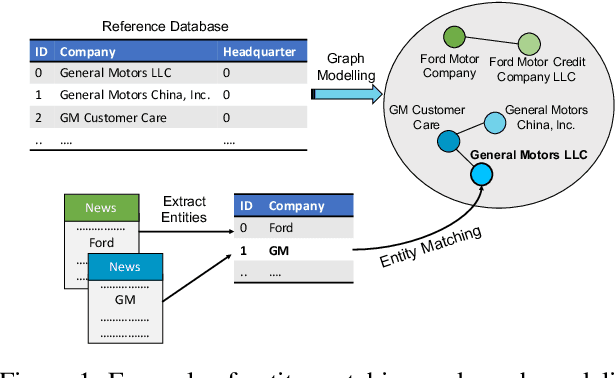

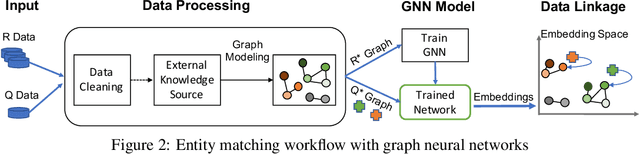
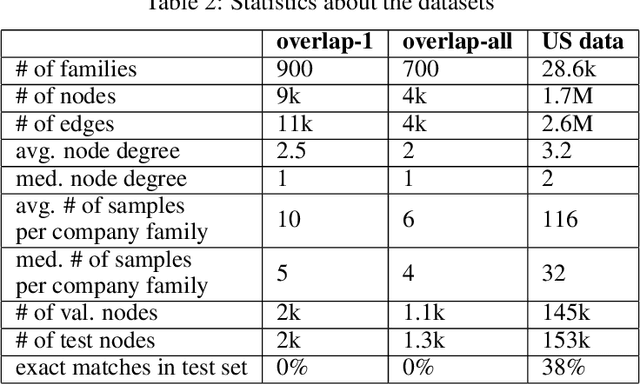
Data integration has been studied extensively for decades and approached from different angles. However, this domain still remains largely rule-driven and lacks universal automation. Recent development in machine learning and in particular deep learning has opened the way to more general and more efficient solutions to data integration problems. In this work, we propose a general approach to modeling and integrating entities from structured data, such as relational databases, as well as unstructured sources, such as free text from news articles. Our approach is designed to explicitly model and leverage relations between entities, thereby using all available information and preserving as much context as possible. This is achieved by combining siamese and graph neural networks to propagate information between connected entities and support high scalability. We evaluate our method on the task of integrating data about business entities, and we demonstrate that it outperforms standard rule-based systems, as well as other deep learning approaches that do not use graph-based representations.