 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Knowledge Graph Embedding Models
Jan 08, 2022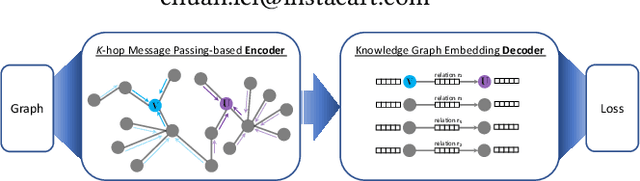
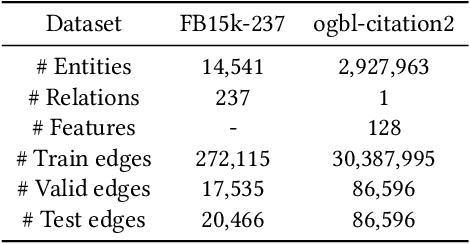
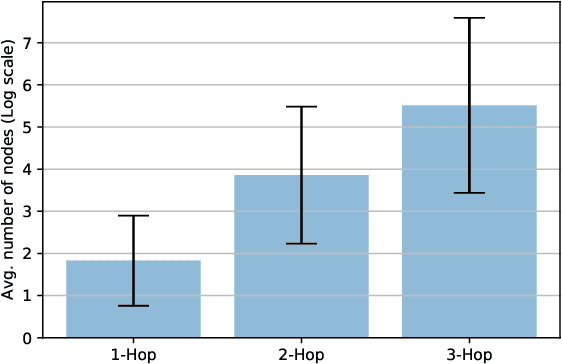
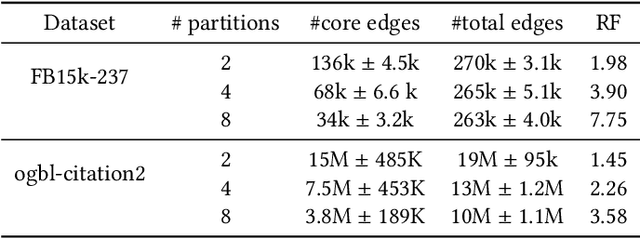
Developing scalable solutions for training Graph Neural Networks (GNNs) for link prediction tasks is challenging due to the high data dependencies which entail high computational cost and huge memory footprint. We propose a new method for scaling training of knowledge graph embedding models for link prediction to address these challenges. Towards this end, we propose the following algorithmic strategies: self-sufficient partitions, constraint-based negative sampling, and edge mini-batch training. Both, partitioning strategy and constraint-based negative sampling, avoid cross partition data transfer during training. In our experimental evaluation, we show that our scaling solution for GNN-based knowledge graph embedding models achieves a 16x speed up on benchmark datasets while maintaining a comparable model performance as non-distributed methods on standard metrics.
Knowledge Graph Embedding using Graph Convolutional Networks with Relation-Aware Attention
Feb 14, 2021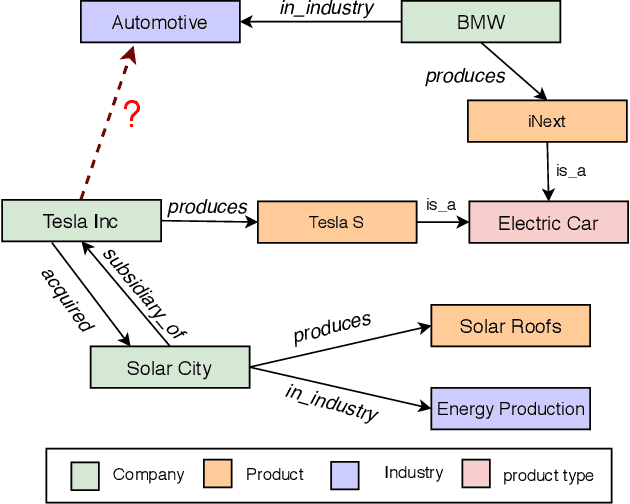
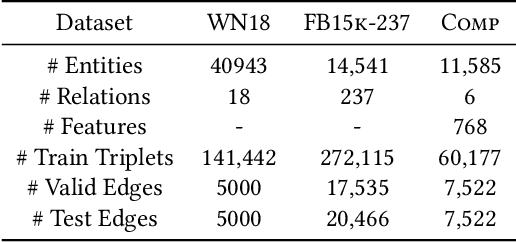
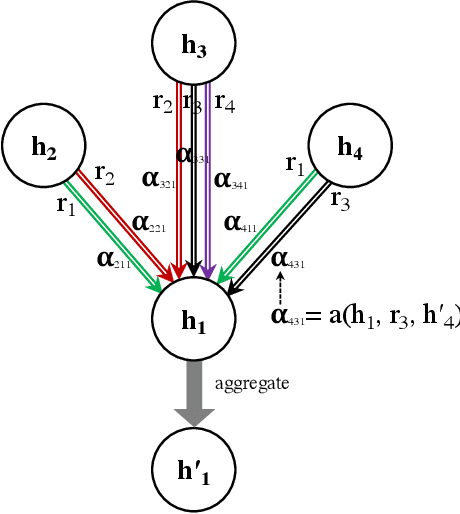
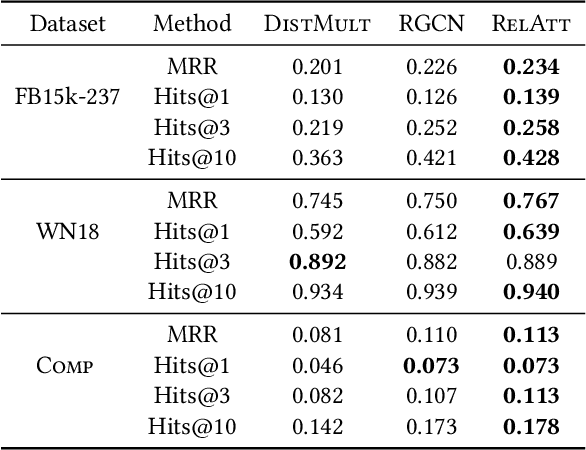
Knowledge graph embedding methods learn embeddings of entities and relations in a low dimensional space which can be used for various downstream machine learning tasks such as link prediction and entity matching. Various graph convolutional network methods have been proposed which use different types of information to learn the features of entities and relations. However, these methods assign the same weight (importance) to the neighbors when aggregating the information, ignoring the role of different relations with the neighboring entities. To this end, we propose a relation-aware graph attention model that leverages relation information to compute different weights to the neighboring nodes for learning embeddings of entities and relations. We evaluate our proposed approach on link prediction and entity matching tasks. Our experimental results on link prediction on three datasets (one proprietary and two public) and results on unsupervised entity matching on one proprietary dataset demonstrate the effectiveness of the relation-aware attention.
Relation-aware Graph Attention Model With Adaptive Self-adversarial Training
Feb 14, 2021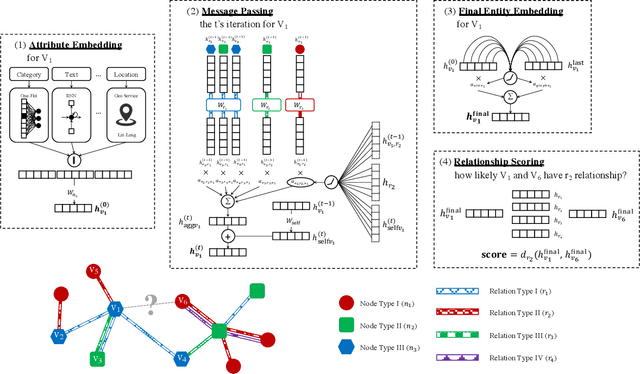


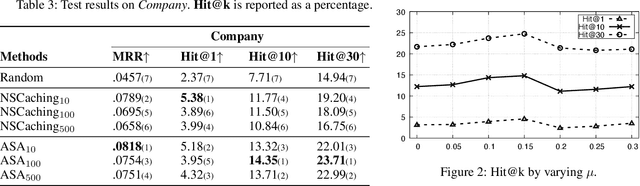
This paper describes an end-to-end solution for the relationship prediction task in heterogeneous, multi-relational graphs. We particularly address two building blocks in the pipeline, namely heterogeneous graph representation learning and negative sampling. Existing message passing-based graph neural networks use edges either for graph traversal and/or selection of message encoding functions. Ignoring the edge semantics could have severe repercussions on the quality of embeddings, especially when dealing with two nodes having multiple relations. Furthermore, the expressivity of the learned representation depends on the quality of negative samples used during training. Although existing hard negative sampling techniques can identify challenging negative relationships for optimization, new techniques are required to control false negatives during training as false negatives could corrupt the learning process. To address these issues, first, we propose RelGNN -- a message passing-based heterogeneous graph attention model. In particular, RelGNN generates the states of different relations and leverages them along with the node states to weigh the messages. RelGNN also adopts a self-attention mechanism to balance the importance of attribute features and topological features for generating the final entity embeddings. Second, we introduce a parameter-free negative sampling technique -- adaptive self-adversarial (ASA) negative sampling. ASA reduces the false-negative rate by leveraging positive relationships to effectively guide the identification of true negative samples. Our experimental evaluation demonstrates that RelGNN optimized by ASA for relationship prediction improves state-of-the-art performance across established benchmarks as well as on a real industrial dataset.
Ultrasound Image Classification using ACGAN with Small Training Dataset
Jan 31, 2021
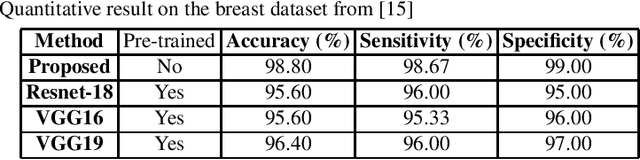
B-mode ultrasound imaging is a popular medical imaging technique. Like other image processing tasks, deep learning has been used for analysis of B-mode ultrasound images in the last few years. However, training deep learning models requires large labeled datasets, which is often unavailable for ultrasound images. The lack of large labeled data is a bottleneck for the use of deep learning in ultrasound image analysis. To overcome this challenge, in this work we exploit Auxiliary Classifier Generative Adversarial Network (ACGAN) that combines the benefits of data augmentation and transfer learning in the same framework. We conduct experiment on a dataset of breast ultrasound images that shows the effectiveness of the proposed approach.
Dynamic Embeddings for Interaction Prediction
Nov 10, 2020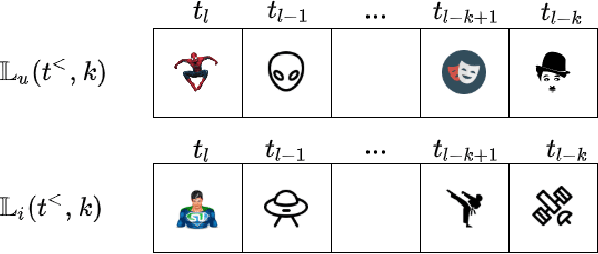
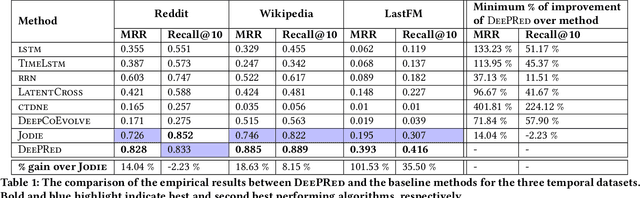

In recommender systems (RSs), predicting the next item that a user interacts with is critical for user retention. While the last decade has seen an explosion of RSs aimed at identifying relevant items that match user preferences, there is still a range of aspects that could be considered to further improve their performance. For example, often RSs are centered around the user, who is modeled using her recent sequence of activities. Recent studies, however, have shown the effectiveness of modeling the mutual interactions between users and items using separate user and item embeddings. Building on the success of these studies, we propose a novel method called DeePRed that addresses some of their limitations. In particular, we avoid recursive and costly interactions between consecutive short-term embeddings by using long-term (stationary) embeddings as a proxy. This enable us to train DeePRed using simple mini-batches without the overhead of specialized mini-batches proposed in previous studies. Moreover, DeePRed's effectiveness comes from the aforementioned design and a multi-way attention mechanism that inspects user-item compatibility. Experiments show that DeePRed outperforms the best state-of-the-art approach by at least 14% on next item prediction task, while gaining more than an order of magnitude speedup over the best performing baselines. Although this study is mainly concerned with temporal interaction networks, we also show the power and flexibility of DeePRed by adapting it to the case of static interaction networks, substituting the short- and long-term aspects with local and global ones.
Which way? Direction-Aware Attributed Graph Embedding
Jan 30, 2020
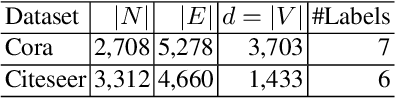
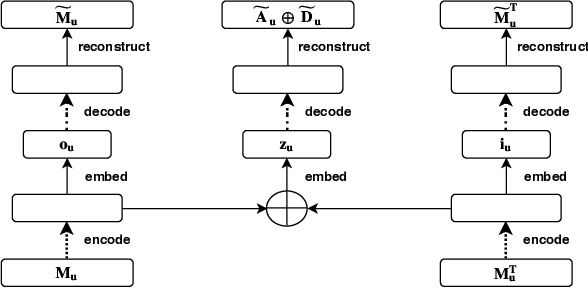
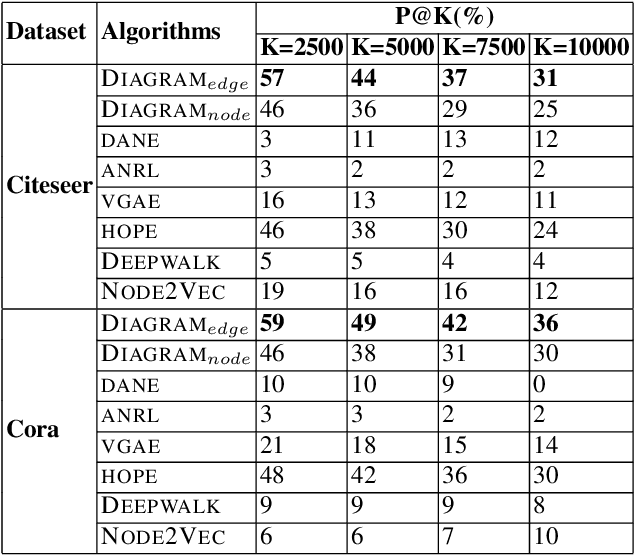
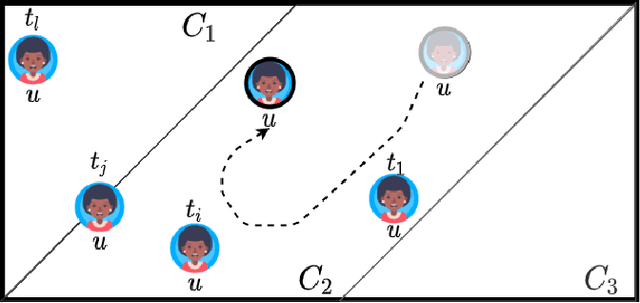
Graph embedding algorithms are used to efficiently represent (encode) a graph in a low-dimensional continuous vector space that preserves the most important properties of the graph. One aspect that is often overlooked is whether the graph is directed or not. Most studies ignore the directionality, so as to learn high-quality representations optimized for node classification. On the other hand, studies that capture directionality are usually effective on link prediction but do not perform well on other tasks. This preliminary study presents a novel text-enriched, direction-aware algorithm called DIAGRAM , based on a carefully designed multi-objective model to learn embeddings that preserve the direction of edges, textual features and graph context of nodes. As a result, our algorithm does not have to trade one property for another and jointly learns high-quality representations for multiple network analysis tasks. We empirically show that DIAGRAM significantly outperforms six state-of-the-art baselines, both direction-aware and oblivious ones,on link prediction and network reconstruction experiments using two popular datasets. It also achieves a comparable performance on node classification experiments against these baselines using the same datasets.