 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Personalized Relevance Algorithms for Directed Graphs
May 03, 2024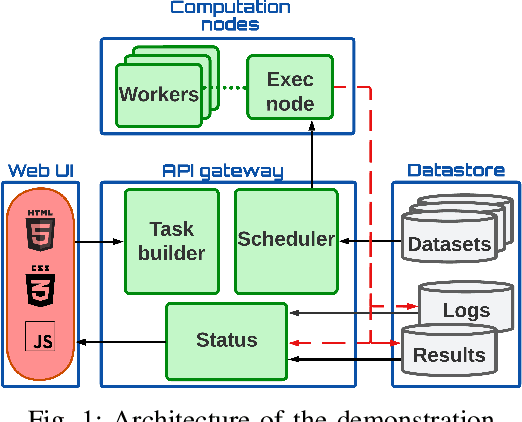



We present an interactive Web platform that, given a directed graph, allows identifying the most relevant nodes related to a given query node. Besides well-established algorithms such as PageRank and Personalized PageRank, the demo includes Cyclerank, a novel algorithm that addresses some of their limitations by leveraging cyclic paths to compute personalized relevance scores. Our demo design enables two use cases: (a) algorithm comparison, comparing the results obtained with different algorithms, and (b) dataset comparison, for exploring and gaining insights into a dataset and comparing it with others. We provide 50 pre-loaded datasets from Wikipedia, Twitter, and Amazon and seven algorithms. Users can upload new datasets, and new algorithms can be easily added. By showcasing efficient algorithms to compute relevance scores in directed graphs, our tool helps to uncover hidden relationships within the data, which makes of it a valuable addition to the repertoire of graph analysis algorithms.
Dynamic Embeddings for Interaction Prediction
Nov 10, 2020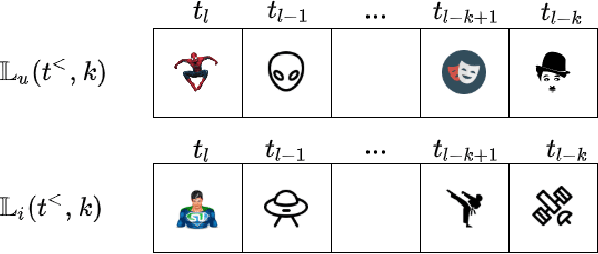
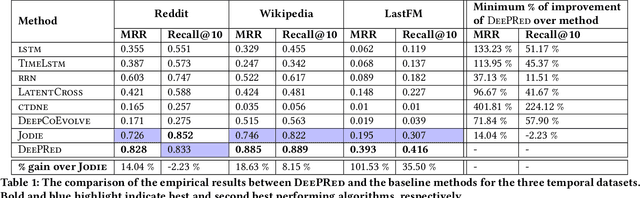
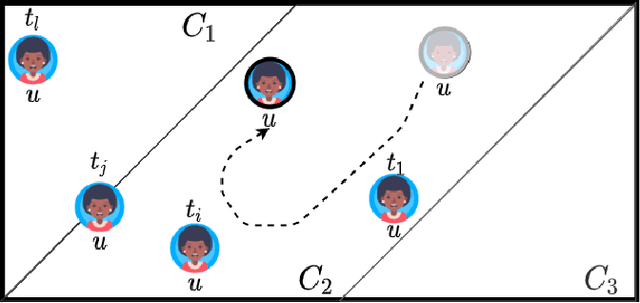

In recommender systems (RSs), predicting the next item that a user interacts with is critical for user retention. While the last decade has seen an explosion of RSs aimed at identifying relevant items that match user preferences, there is still a range of aspects that could be considered to further improve their performance. For example, often RSs are centered around the user, who is modeled using her recent sequence of activities. Recent studies, however, have shown the effectiveness of modeling the mutual interactions between users and items using separate user and item embeddings. Building on the success of these studies, we propose a novel method called DeePRed that addresses some of their limitations. In particular, we avoid recursive and costly interactions between consecutive short-term embeddings by using long-term (stationary) embeddings as a proxy. This enable us to train DeePRed using simple mini-batches without the overhead of specialized mini-batches proposed in previous studies. Moreover, DeePRed's effectiveness comes from the aforementioned design and a multi-way attention mechanism that inspects user-item compatibility. Experiments show that DeePRed outperforms the best state-of-the-art approach by at least 14% on next item prediction task, while gaining more than an order of magnitude speedup over the best performing baselines. Although this study is mainly concerned with temporal interaction networks, we also show the power and flexibility of DeePRed by adapting it to the case of static interaction networks, substituting the short- and long-term aspects with local and global ones.
A general method for estimating the prevalence of Influenza-Like-Symptoms with Wikipedia data
Oct 28, 2020
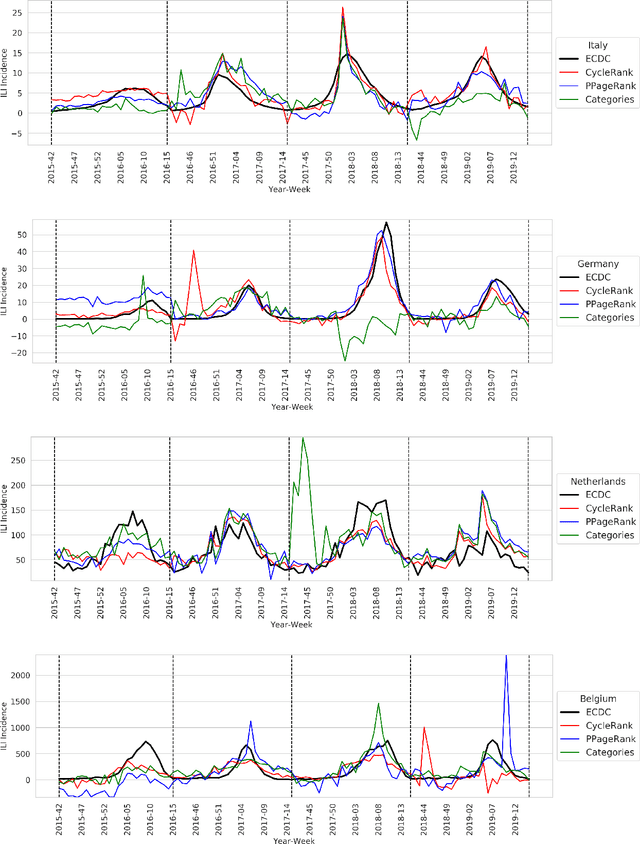

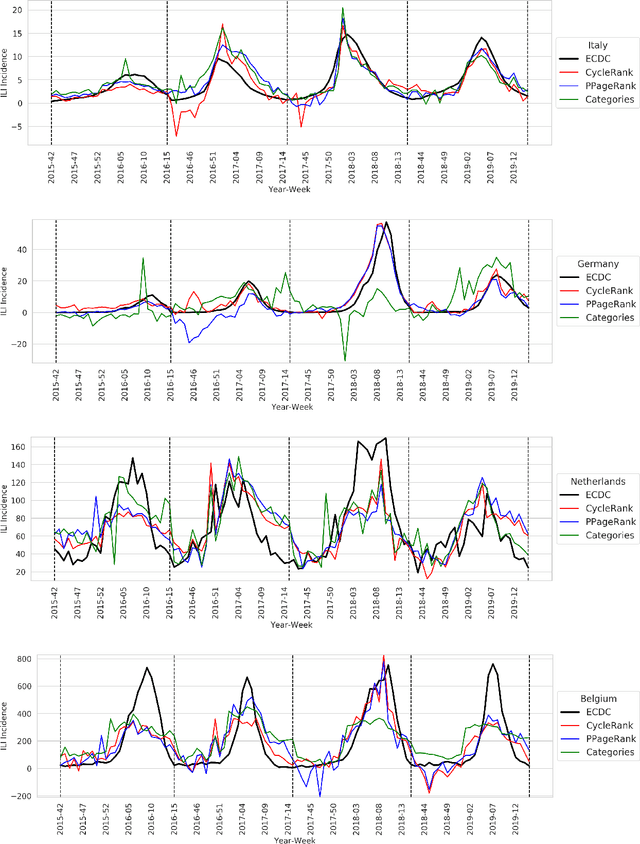
Influenza is an acute respiratory seasonal disease that affects millions of people worldwide and causes thousands of deaths in Europe alone. Being able to estimate in a fast and reliable way the impact of an illness on a given country is essential to plan and organize effective countermeasures, which is now possible by leveraging unconventional data sources like web searches and visits. In this study, we show the feasibility of exploiting information about Wikipedia's page views of a selected group of articles and machine learning models to obtain accurate estimates of influenza-like illnesses incidence in four European countries: Italy, Germany, Belgium, and the Netherlands. We propose a novel language-agnostic method, based on two algorithms, Personalized PageRank and CycleRank, to automatically select the most relevant Wikipedia pages to be monitored without the need for expert supervision. We then show how our model is able to reach state-of-the-art results by comparing it with previous solutions.
Which way? Direction-Aware Attributed Graph Embedding
Jan 30, 2020
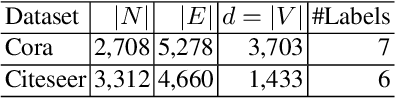
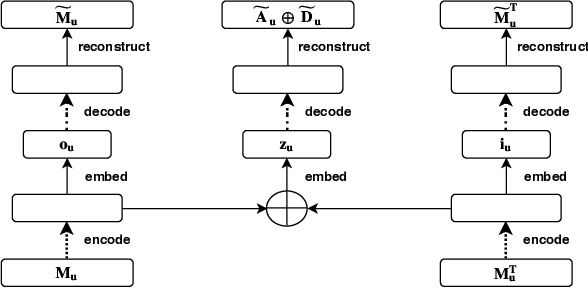
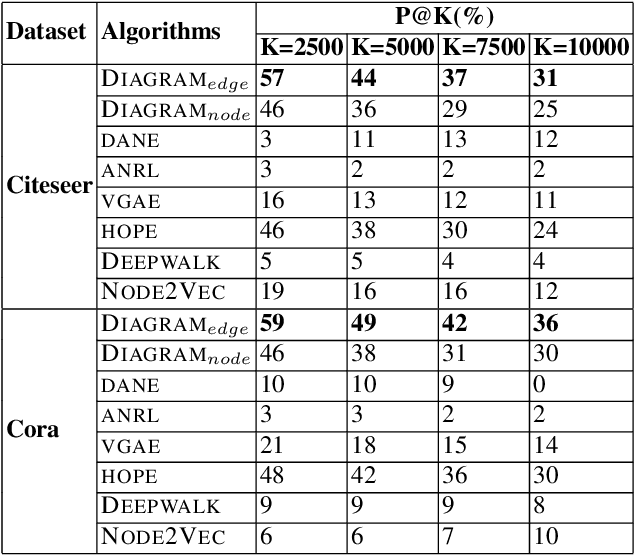
Graph embedding algorithms are used to efficiently represent (encode) a graph in a low-dimensional continuous vector space that preserves the most important properties of the graph. One aspect that is often overlooked is whether the graph is directed or not. Most studies ignore the directionality, so as to learn high-quality representations optimized for node classification. On the other hand, studies that capture directionality are usually effective on link prediction but do not perform well on other tasks. This preliminary study presents a novel text-enriched, direction-aware algorithm called DIAGRAM , based on a carefully designed multi-objective model to learn embeddings that preserve the direction of edges, textual features and graph context of nodes. As a result, our algorithm does not have to trade one property for another and jointly learns high-quality representations for multiple network analysis tasks. We empirically show that DIAGRAM significantly outperforms six state-of-the-art baselines, both direction-aware and oblivious ones,on link prediction and network reconstruction experiments using two popular datasets. It also achieves a comparable performance on node classification experiments against these baselines using the same datasets.