 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide et Calibra: Multiclass Local Calibration via Vector Quantization
May 20, 2026Accurate and well-calibrated Machine Learning (ML) models are mandatory in high-stakes settings, yet effective multiclass calibration remains challenging: global approaches assume calibration errors are homogeneous across the latent space, while local methods often rely on latent-space dimensionality reduction, which leads to information loss. To address these issues, we propose a compositional approach to multiclass calibration, where region-specific calibration maps are constructed from shared codeword-dependent factors. We instantiate this idea via Vector Quantization (VQ), which induces a structured partition of the representation space, and an indexed parameterization of Dirichlet concentrations that enables parameter sharing across regions. Our approach learns heterogeneous calibration maps that generalize well even to sparse regions of the latent space. Experiments on benchmark datasets show significant improvements in local calibration while maintaining competitive global calibration and predictive performance.
With a Little Help From My Friends: Collective Manipulation in Risk-Controlling Recommender Systems
Mar 30, 2026Recommendation systems have become central gatekeepers of online information, shaping user behaviour across a wide range of activities. In response, users increasingly organize and coordinate to steer algorithmic outcomes toward diverse goals, such as promoting relevant content or limiting harmful material, relying on platform affordances -- such as likes, reviews, or ratings. While these mechanisms can serve beneficial purposes, they can also be leveraged for adversarial manipulation, particularly in systems where such feedback directly informs safety guarantees. In this paper, we study this vulnerability in recently proposed risk-controlling recommender systems, which use binary user feedback (e.g., "Not Interested") to provably limit exposure to unwanted content via conformal risk control. We empirically demonstrate that their reliance on aggregate feedback signals makes them inherently susceptible to coordinated adversarial user behaviour. Using data from a large-scale online video-sharing platform, we show that a small coordinated group (comprising only 1% of the user population) can induce up to a 20% degradation in nDCG for non-adversarial users by exploiting the affordances provided by risk-controlling recommender systems. We evaluate simple, realistic attack strategies that require little to no knowledge of the underlying recommendation algorithm and find that, while coordinated users can significantly harm overall recommendation quality, they cannot selectively suppress specific content groups through reporting alone. Finally, we propose a mitigation strategy that shifts guarantees from the group level to the user level, showing empirically how it can reduce the impact of adversarial coordinated behaviour while ensuring personalized safety for individuals.
Multiclass Local Calibration With the Jensen-Shannon Distance
Oct 30, 2025Developing trustworthy Machine Learning (ML) models requires their predicted probabilities to be well-calibrated, meaning they should reflect true-class frequencies. Among calibration notions in multiclass classification, strong calibration is the most stringent, as it requires all predicted probabilities to be simultaneously calibrated across all classes. However, existing approaches to multiclass calibration lack a notion of distance among inputs, which makes them vulnerable to proximity bias: predictions in sparse regions of the feature space are systematically miscalibrated. This is especially relevant in high-stakes settings, such as healthcare, where the sparse instances are exactly those most at risk of biased treatment. In this work, we address this main shortcoming by introducing a local perspective on multiclass calibration. First, we formally define multiclass local calibration and establish its relationship with strong calibration. Second, we theoretically analyze the pitfalls of existing evaluation metrics when applied to multiclass local calibration. Third, we propose a practical method for enhancing local calibration in Neural Networks, which enforces alignment between predicted probabilities and local estimates of class frequencies using the Jensen-Shannon distance. Finally, we empirically validate our approach against existing multiclass calibration techniques.
Who Pays for Fairness? Rethinking Recourse under Social Burden
Sep 04, 2025



Machine learning based predictions are increasingly used in sensitive decision-making applications that directly affect our lives. This has led to extensive research into ensuring the fairness of classifiers. Beyond just fair classification, emerging legislation now mandates that when a classifier delivers a negative decision, it must also offer actionable steps an individual can take to reverse that outcome. This concept is known as algorithmic recourse. Nevertheless, many researchers have expressed concerns about the fairness guarantees within the recourse process itself. In this work, we provide a holistic theoretical characterization of unfairness in algorithmic recourse, formally linking fairness guarantees in recourse and classification, and highlighting limitations of the standard equal cost paradigm. We then introduce a novel fairness framework based on social burden, along with a practical algorithm (MISOB), broadly applicable under real-world conditions. Empirical results on real-world datasets show that MISOB reduces the social burden across all groups without compromising overall classifier accuracy.
Time Can Invalidate Algorithmic Recourse
Oct 10, 2024



Algorithmic Recourse (AR) aims to provide users with actionable steps to overturn unfavourable decisions made by machine learning predictors. However, these actions often take time to implement (e.g., getting a degree can take years), and their effects may vary as the world evolves. Thus, it is natural to ask for recourse that remains valid in a dynamic environment. In this paper, we study the robustness of algorithmic recourse over time by casting the problem through the lens of causality. We demonstrate theoretically and empirically that (even robust) causal AR methods can fail over time except in the - unlikely - case that the world is stationary. Even more critically, unless the world is fully deterministic, counterfactual AR cannot be solved optimally. To account for this, we propose a simple yet effective algorithm for temporal AR that explicitly accounts for time. Our simulations on synthetic and realistic datasets show how considering time produces more resilient solutions to potential trends in the data distribution.
Towards Human-AI Complementarity with Predictions Sets
May 27, 2024
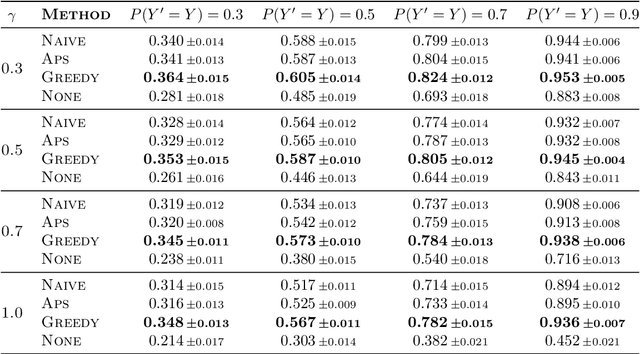
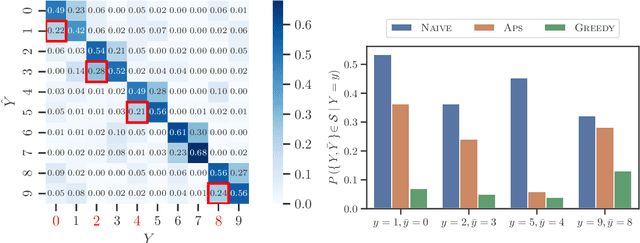

Decision support systems based on prediction sets have proven to be effective at helping human experts solve classification tasks. Rather than providing single-label predictions, these systems provide sets of label predictions constructed using conformal prediction, namely prediction sets, and ask human experts to predict label values from these sets. In this paper, we first show that the prediction sets constructed using conformal prediction are, in general, suboptimal in terms of average accuracy. Then, we show that the problem of finding the optimal prediction sets under which the human experts achieve the highest average accuracy is NP-hard. More strongly, unless P = NP, we show that the problem is hard to approximate to any factor less than the size of the label set. However, we introduce a simple and efficient greedy algorithm that, for a large class of expert models and non-conformity scores, is guaranteed to find prediction sets that provably offer equal or greater performance than those constructed using conformal prediction. Further, using a simulation study with both synthetic and real expert predictions, we demonstrate that, in practice, our greedy algorithm finds near-optimal prediction sets offering greater performance than conformal prediction.
Exploiting Preference Elicitation in Interactive and User-centered Algorithmic Recourse: An Initial Exploration
Apr 08, 2024

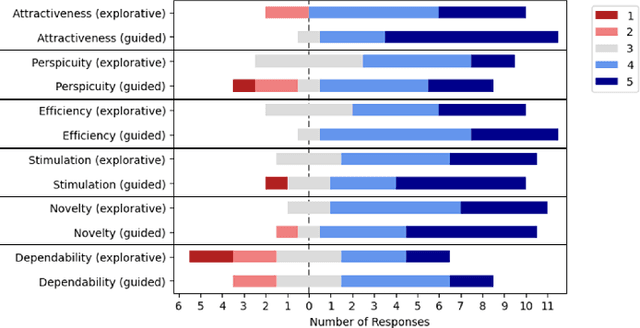
Algorithmic Recourse aims to provide actionable explanations, or recourse plans, to overturn potentially unfavourable decisions taken by automated machine learning models. In this paper, we propose an interaction paradigm based on a guided interaction pattern aimed at both eliciting the users' preferences and heading them toward effective recourse interventions. In a fictional task of money lending, we compare this approach with an exploratory interaction pattern based on a combination of alternative plans and the possibility of freely changing the configurations by the users themselves. Our results suggest that users may recognize that the guided interaction paradigm improves efficiency. However, they also feel less freedom to experiment with "what-if" scenarios. Nevertheless, the time spent on the purely exploratory interface tends to be perceived as a lack of efficiency, which reduces attractiveness, perspicuity, and dependability. Conversely, for the guided interface, more time on the interface seems to increase its attractiveness, perspicuity, and dependability while not impacting the perceived efficiency. That might suggest that this type of interfaces should combine these two approaches by trying to support exploratory behavior while gently pushing toward a guided effective solution.
Generating personalized counterfactual interventions for algorithmic recourse by eliciting user preferences
May 27, 2022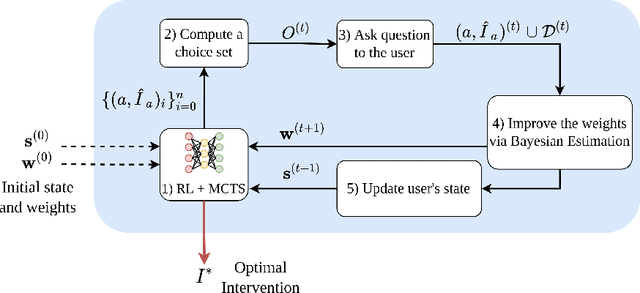
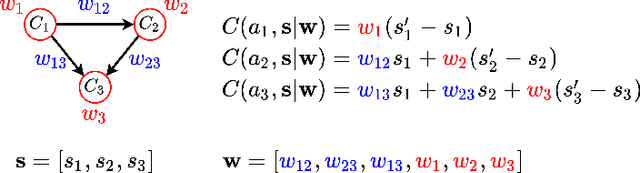
Counterfactual interventions are a powerful tool to explain the decisions of a black-box decision process, and to enable algorithmic recourse. They are a sequence of actions that, if performed by a user, can overturn an unfavourable decision made by an automated decision system. However, most of the current methods provide interventions without considering the user's preferences. For example, a user might prefer doing certain actions with respect to others. In this work, we present the first human-in-the-loop approach to perform algorithmic recourse by eliciting user preferences. We introduce a polynomial procedure to ask choice-set questions which maximize the Expected Utility of Selection (EUS), and use it to iteratively refine our cost estimates in a Bayesian setting. We integrate this preference elicitation strategy into a reinforcement learning agent coupled with Monte Carlo Tree Search for efficient exploration, so as to provide personalized interventions achieving algorithmic recourse. An experimental evaluation on synthetic and real-world datasets shows that a handful of queries allows to achieve a substantial reduction in the cost of interventions with respect to user-independent alternatives.
Synthesizing explainable counterfactual policies for algorithmic recourse with program synthesis
Jan 18, 2022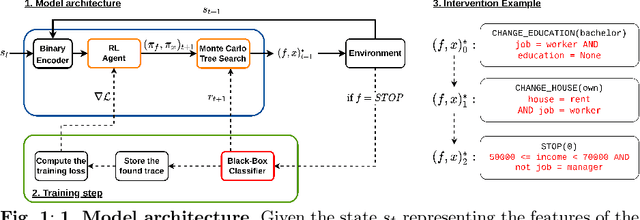

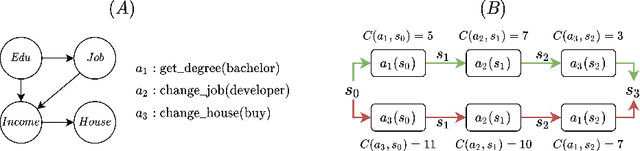
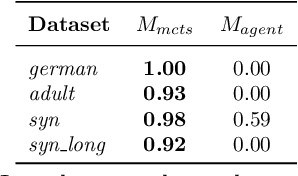
Being able to provide counterfactual interventions - sequences of actions we would have had to take for a desirable outcome to happen - is essential to explain how to change an unfavourable decision by a black-box machine learning model (e.g., being denied a loan request). Existing solutions have mainly focused on generating feasible interventions without providing explanations on their rationale. Moreover, they need to solve a separate optimization problem for each user. In this paper, we take a different approach and learn a program that outputs a sequence of explainable counterfactual actions given a user description and a causal graph. We leverage program synthesis techniques, reinforcement learning coupled with Monte Carlo Tree Search for efficient exploration, and rule learning to extract explanations for each recommended action. An experimental evaluation on synthetic and real-world datasets shows how our approach generates effective interventions by making orders of magnitude fewer queries to the black-box classifier with respect to existing solutions, with the additional benefit of complementing them with interpretable explanations.
Learning compositional programs with arguments and sampling
Sep 01, 2021
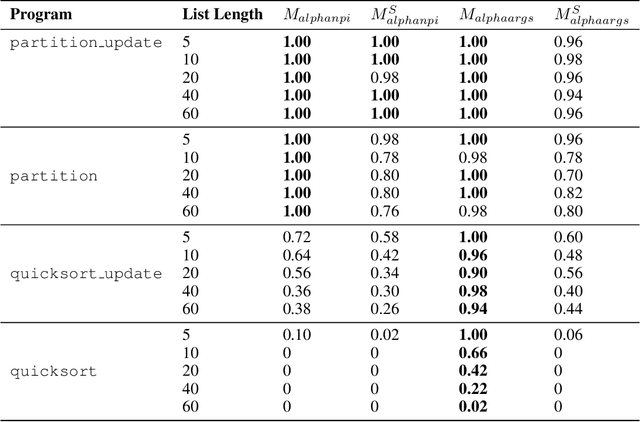

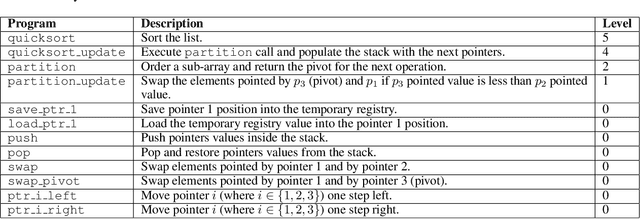
One of the most challenging goals in designing intelligent systems is empowering them with the ability to synthesize programs from data. Namely, given specific requirements in the form of input/output pairs, the goal is to train a machine learning model to discover a program that satisfies those requirements. A recent class of methods exploits combinatorial search procedures and deep learning to learn compositional programs. However, they usually generate only toy programs using a domain-specific language that does not provide any high-level feature, such as function arguments, which reduces their applicability in real-world settings. We extend upon a state of the art model, AlphaNPI, by learning to generate functions that can accept arguments. This improvement will enable us to move closer to real computer programs. Moreover, we investigate employing an Approximate version of Monte Carlo Tree Search (A-MCTS) to speed up convergence. We showcase the potential of our approach by learning the Quicksort algorithm, showing how the ability to deal with arguments is crucial for learning and generalization.