 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric Hierarchical Visual Semantics
May 09, 2023We are interested in aligning how people think about objects and what machines perceive, meaning by this the fact that object recognition, as performed by a machine, should follow a process which resembles that followed by humans when thinking of an object associated with a certain concept. The ultimate goal is to build systems which can meaningfully interact with their users, describing what they perceive in the users' own terms. As from the field of Lexical Semantics, humans organize the meaning of words in hierarchies where the meaning of, e.g., a noun, is defined in terms of the meaning of a more general noun, its genus, and of one or more differentiating properties, its differentia. The main tenet of this paper is that object recognition should implement a hierarchical process which follows the hierarchical semantic structure used to define the meaning of words. We achieve this goal by implementing an algorithm which, for any object, recursively recognizes its visual genus and its visual differentia. In other words, the recognition of an object is decomposed in a sequence of steps where the locally relevant visual features are recognized. This paper presents the algorithm and a first evaluation.
Lifelong Personal Context Recognition
May 10, 2022
We focus on the development of AIs which live in lifelong symbiosis with a human. The key prerequisite for this task is that the AI understands - at any moment in time - the personal situational context that the human is in. We outline the key challenges that this task brings forth, namely (i) handling the human-like and ego-centric nature of the the user's context, necessary for understanding and providing useful suggestions, (ii) performing lifelong context recognition using machine learning in a way that is robust to change, and (iii) maintaining alignment between the AI's and human's representations of the world through continual bidirectional interaction. In this short paper, we summarize our recent attempts at tackling these challenges, discuss the lessons learned, and highlight directions of future research. The main take-away message is that pursuing this project requires research which lies at the intersection of knowledge representation and machine learning. Neither technology can achieve this goal without the other.
Learning compositional programs with arguments and sampling
Sep 01, 2021
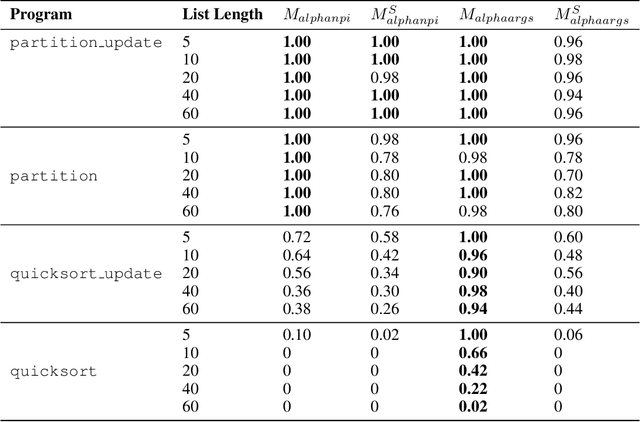

One of the most challenging goals in designing intelligent systems is empowering them with the ability to synthesize programs from data. Namely, given specific requirements in the form of input/output pairs, the goal is to train a machine learning model to discover a program that satisfies those requirements. A recent class of methods exploits combinatorial search procedures and deep learning to learn compositional programs. However, they usually generate only toy programs using a domain-specific language that does not provide any high-level feature, such as function arguments, which reduces their applicability in real-world settings. We extend upon a state of the art model, AlphaNPI, by learning to generate functions that can accept arguments. This improvement will enable us to move closer to real computer programs. Moreover, we investigate employing an Approximate version of Monte Carlo Tree Search (A-MCTS) to speed up convergence. We showcase the potential of our approach by learning the Quicksort algorithm, showing how the ability to deal with arguments is crucial for learning and generalization.
Towards Visual Semantics
Apr 26, 2021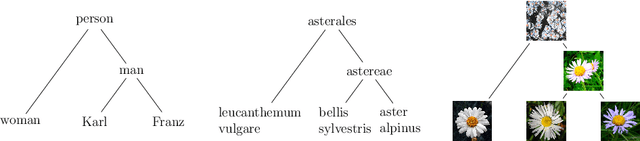
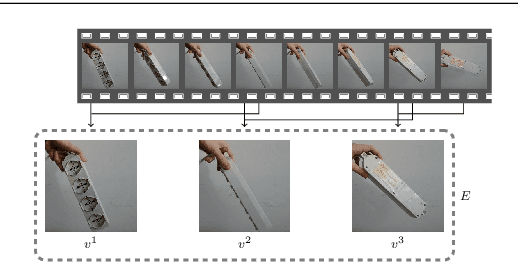


In Visual Semantics we study how humans build mental representations, i.e., concepts , of what they visually perceive. We call such concepts, substance concepts. In this paper we provide a theory and an algorithm which learns substance concepts which correspond to the concepts, that we call classification concepts , that in Lexical Semantics are used to encode word meanings. The theory and algorithm are based on three main contributions: (i) substance concepts are modeled as visual objects , namely sequences of similar frames, as perceived in multiple encounters ; (ii) substance concepts are organized into a visual subsumption hierarchy based on the notions of Genus and Differentia that resemble the notions that, in Lexical Semantics, allow to construct hierarchies of classification concepts; (iii) the human feedback is exploited not to name objects, as it has been the case so far, but, rather, to align the hierarchy of substance concepts with that of classification concepts. The learning algorithm is implemented for the base case of a hierarchy of depth two. The experiments, though preliminary, show that the algorithm manages to acquire the notions of Genus and Differentia with reasonable accuracy, this despite seeing a small number of examples and receiving supervision on a fraction of them.
Continual egocentric object recognition
Dec 06, 2019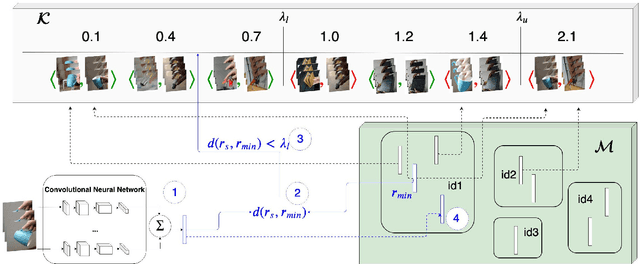
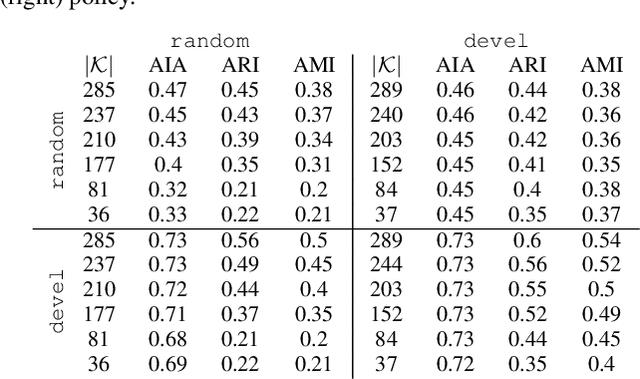

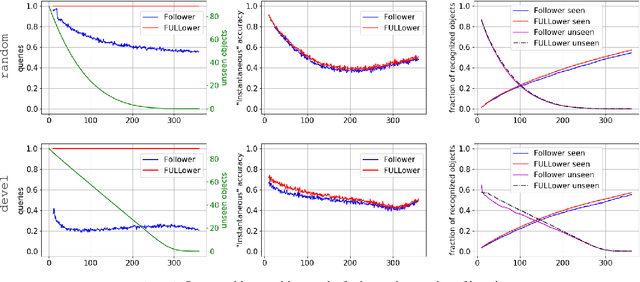
We are interested in the problem of continual object recognition in a setting which resembles that under which humans see and learn. This problem is of high relevance in all those applications where an agent must work collaboratively with a human in the same setting (e.g., personal assistance). The main innovative aspects of this setting with respect to the state-of-the-art are: it assumes an egocentric point-of-view bound to a single person, which implies a relatively low diversity of data and a cold start with no data; it requires to operate in a open world, where new objects can be encountered at any time; supervision is scarce and has to be solicited to the user, and completely unsupervised recognition of new objects should be possible. Note that this setting differs from the one addressed in the open world recognition literature, where supervised feedback is always requested to be able to incorporate new objects. We propose an incremental approach which is based on four main features: the use of time and space persistency (i.e., the appearance of objects changes relatively slowly), the use of similarity as the main driving principle for object recognition and novelty detection, the progressive introduction of new objects in a developmental fashion and the selective elicitation of user feedback in an online active learning fashion. Experimental results show the feasibility of open world, generic object recognition, the ability to recognize, memorize and re-identify new objects even in complete absence of user supervision, and the utility of persistency and incrementality in boosting performance.