 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Visual Semantics
Paper and Code
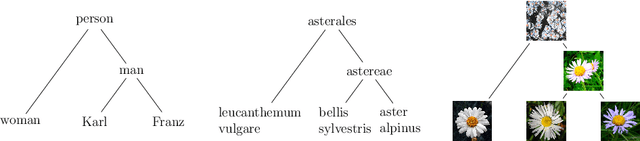
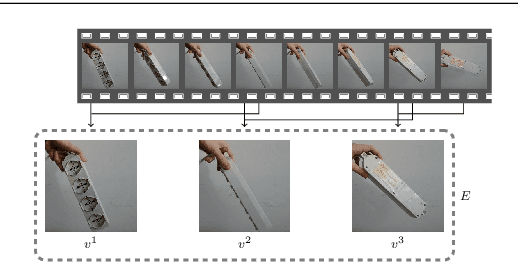


In Visual Semantics we study how humans build mental representations, i.e., concepts , of what they visually perceive. We call such concepts, substance concepts. In this paper we provide a theory and an algorithm which learns substance concepts which correspond to the concepts, that we call classification concepts , that in Lexical Semantics are used to encode word meanings. The theory and algorithm are based on three main contributions: (i) substance concepts are modeled as visual objects , namely sequences of similar frames, as perceived in multiple encounters ; (ii) substance concepts are organized into a visual subsumption hierarchy based on the notions of Genus and Differentia that resemble the notions that, in Lexical Semantics, allow to construct hierarchies of classification concepts; (iii) the human feedback is exploited not to name objects, as it has been the case so far, but, rather, to align the hierarchy of substance concepts with that of classification concepts. The learning algorithm is implemented for the base case of a hierarchy of depth two. The experiments, though preliminary, show that the algorithm manages to acquire the notions of Genus and Differentia with reasonable accuracy, this despite seeing a small number of examples and receiving supervision on a fraction of them.