 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Interpretability -- Interactive Alignment of Prototypical Parts Networks
Jun 05, 2025Concept-based interpretable neural networks have gained significant attention due to their intuitive and easy-to-understand explanations based on case-based reasoning, such as "this bird looks like those sparrows". However, a major limitation is that these explanations may not always be comprehensible to users due to concept inconsistency, where multiple visual features are inappropriately mixed (e.g., a bird's head and wings treated as a single concept). This inconsistency breaks the alignment between model reasoning and human understanding. Furthermore, users have specific preferences for how concepts should look, yet current approaches provide no mechanism for incorporating their feedback. To address these issues, we introduce YoursProtoP, a novel interactive strategy that enables the personalization of prototypical parts - the visual concepts used by the model - according to user needs. By incorporating user supervision, YoursProtoP adapts and splits concepts used for both prediction and explanation to better match the user's preferences and understanding. Through experiments on both the synthetic FunnyBirds dataset and a real-world scenario using the CUB, CARS, and PETS datasets in a comprehensive user study, we demonstrate the effectiveness of YoursProtoP in achieving concept consistency without compromising the accuracy of the model.
Egocentric Hierarchical Visual Semantics
May 09, 2023We are interested in aligning how people think about objects and what machines perceive, meaning by this the fact that object recognition, as performed by a machine, should follow a process which resembles that followed by humans when thinking of an object associated with a certain concept. The ultimate goal is to build systems which can meaningfully interact with their users, describing what they perceive in the users' own terms. As from the field of Lexical Semantics, humans organize the meaning of words in hierarchies where the meaning of, e.g., a noun, is defined in terms of the meaning of a more general noun, its genus, and of one or more differentiating properties, its differentia. The main tenet of this paper is that object recognition should implement a hierarchical process which follows the hierarchical semantic structure used to define the meaning of words. We achieve this goal by implementing an algorithm which, for any object, recursively recognizes its visual genus and its visual differentia. In other words, the recognition of an object is decomposed in a sequence of steps where the locally relevant visual features are recognized. This paper presents the algorithm and a first evaluation.
Concept-level Debugging of Part-Prototype Networks
May 31, 2022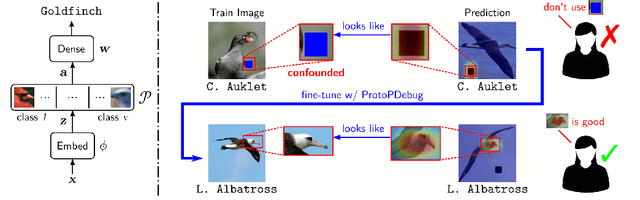
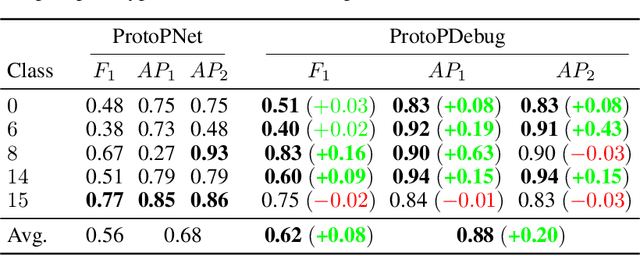

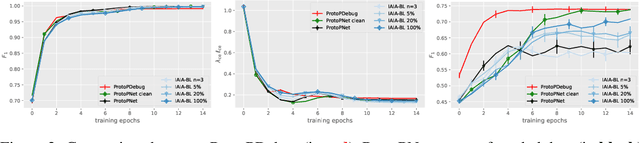
Part-prototype Networks (ProtoPNets) are concept-based classifiers designed to achieve the same performance as black-box models without compromising transparency. ProtoPNets compute predictions based on similarity to class-specific part-prototypes learned to recognize parts of training examples, making it easy to faithfully determine what examples are responsible for any target prediction and why. However, like other models, they are prone to picking up confounds and shortcuts from the data, thus suffering from compromised prediction accuracy and limited generalization. We propose ProtoPDebug, an effective concept-level debugger for ProtoPNets in which a human supervisor, guided by the model's explanations, supplies feedback in the form of what part-prototypes must be forgotten or kept, and the model is fine-tuned to align with this supervision. An extensive empirical evaluation on synthetic and real-world data shows that ProtoPDebug outperforms state-of-the-art debuggers for a fraction of the annotation cost.
Lifelong Personal Context Recognition
May 10, 2022
We focus on the development of AIs which live in lifelong symbiosis with a human. The key prerequisite for this task is that the AI understands - at any moment in time - the personal situational context that the human is in. We outline the key challenges that this task brings forth, namely (i) handling the human-like and ego-centric nature of the the user's context, necessary for understanding and providing useful suggestions, (ii) performing lifelong context recognition using machine learning in a way that is robust to change, and (iii) maintaining alignment between the AI's and human's representations of the world through continual bidirectional interaction. In this short paper, we summarize our recent attempts at tackling these challenges, discuss the lessons learned, and highlight directions of future research. The main take-away message is that pursuing this project requires research which lies at the intersection of knowledge representation and machine learning. Neither technology can achieve this goal without the other.
Toward a Unified Framework for Debugging Gray-box Models
Sep 23, 2021
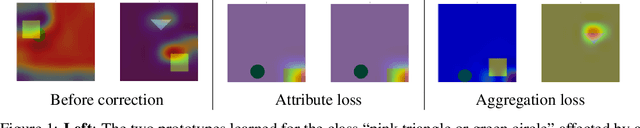
We are concerned with debugging concept-based gray-box models (GBMs). These models acquire task-relevant concepts appearing in the inputs and then compute a prediction by aggregating the concept activations. This work stems from the observation that in GBMs both the concepts and the aggregation function can be affected by different bugs, and that correcting these bugs requires different kinds of corrective supervision. To this end, we introduce a simple schema for identifying and prioritizing bugs in both components, discuss possible implementations and open problems. At the same time, we introduce a new loss function for debugging the aggregation step that extends existing approaches to align the model's explanations to GBMs by making them robust to how the concepts change during training.
Streaming and Learning the Personal Context
Aug 18, 2021

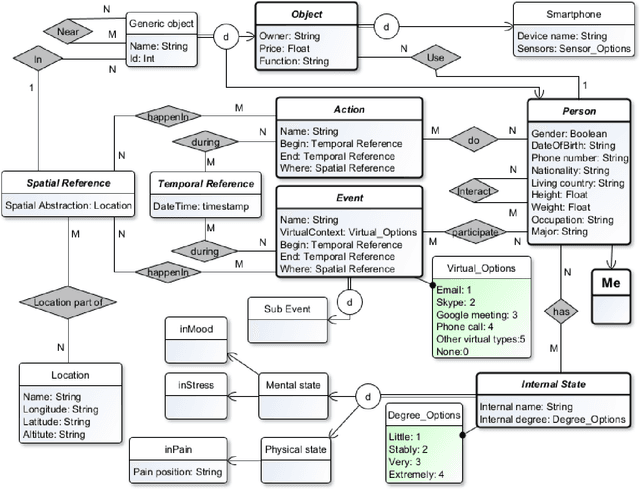
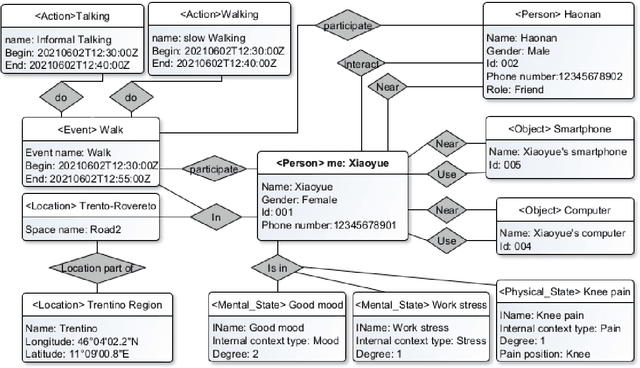
The representation of the personal context is complex and essential to improve the help machines can give to humans for making sense of the world, and the help humans can give to machines to improve their efficiency. We aim to design a novel model representation of the personal context and design a learning process for better integration with machine learning. We aim to implement these elements into a modern system architecture focus in real-life environments. Also, we show how our proposal can improve in specifically related work papers. Finally, we are moving forward with a better personal context representation with an improved model, the implementation of the learning process, and the architectural design of these components.
Interactive Label Cleaning with Example-based Explanations
Jun 07, 2021
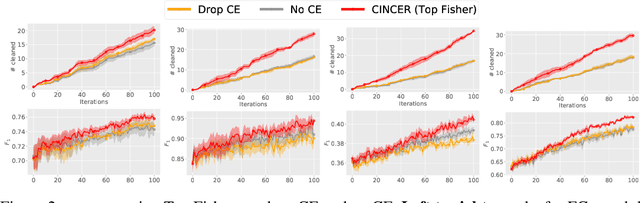

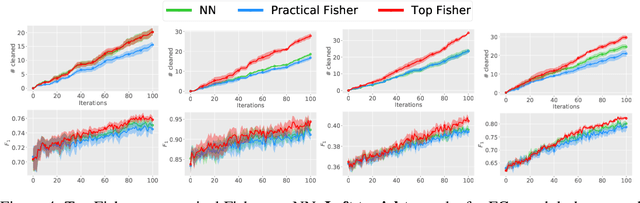
We tackle sequential learning under label noise in applications where a human supervisor can be queried to relabel suspicious examples. Existing approaches are flawed, in that they only relabel incoming examples that look ``suspicious'' to the model. As a consequence, those mislabeled examples that elude (or don't undergo) this cleaning step end up tainting the training data and the model with no further chance of being cleaned. We propose Cincer, a novel approach that cleans both new and past data by identifying pairs of mutually incompatible examples. Whenever it detects a suspicious example, Cincer identifies a counter-example in the training set that -- according to the model -- is maximally incompatible with the suspicious example, and asks the annotator to relabel either or both examples, resolving this possible inconsistency. The counter-examples are chosen to be maximally incompatible, so to serve as explanations of the model' suspicion, and highly influential, so to convey as much information as possible if relabeled. Cincer achieves this by leveraging an efficient and robust approximation of influence functions based on the Fisher information matrix (FIM). Our extensive empirical evaluation shows that clarifying the reasons behind the model's suspicions by cleaning the counter-examples helps acquiring substantially better data and models, especially when paired with our FIM approximation.
Human-in-the-loop Handling of Knowledge Drift
Mar 27, 2021
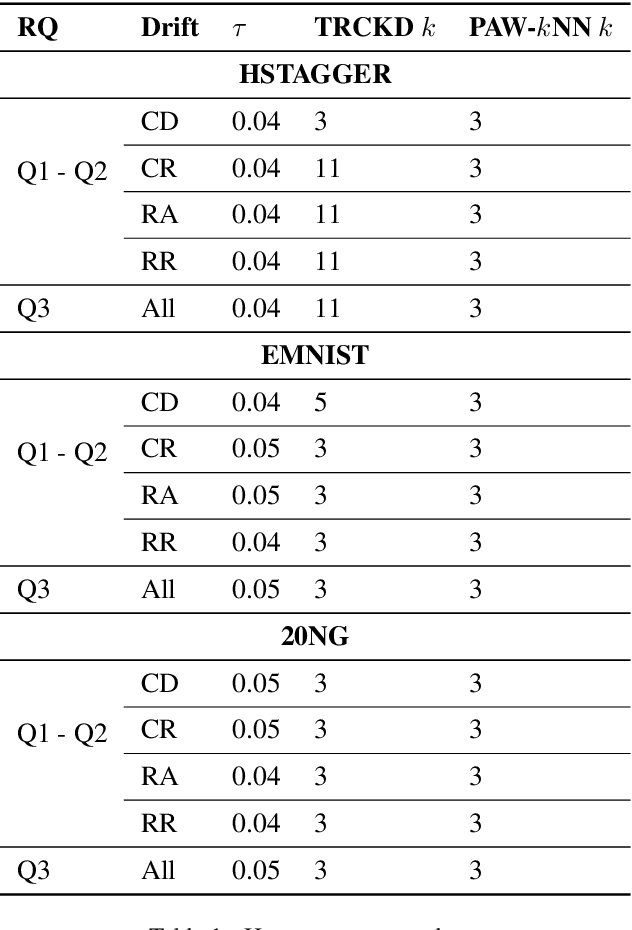


We introduce and study knowledge drift (KD), a complex form of drift that occurs in hierarchical classification. Under KD the vocabulary of concepts, their individual distributions, and the is-a relations between them can all change over time. The main challenge is that, since the ground-truth concept hierarchy is unobserved, it is hard to tell apart different forms of KD. For instance, introducing a new is-a relation between two concepts might be confused with individual changes to those concepts, but it is far from equivalent. Failure to identify the right kind of KD compromises the concept hierarchy used by the classifier, leading to systematic prediction errors. Our key observation is that in many human-in-the-loop applications (like smart personal assistants) the user knows whether and what kind of drift occurred recently. Motivated by this, we introduce TRCKD, a novel approach that combines automated drift detection and adaptation with an interactive stage in which the user is asked to disambiguate between different kinds of KD. In addition, TRCKD implements a simple but effective knowledge-aware adaptation strategy. Our simulations show that often a handful of queries to the user are enough to substantially improve prediction performance on both synthetic and realistic data.
Learning in the Wild with Incremental Skeptical Gaussian Processes
Nov 02, 2020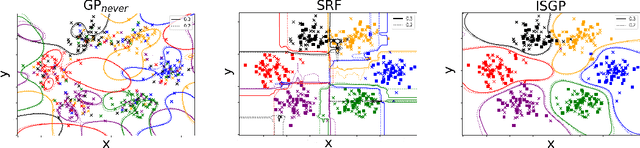
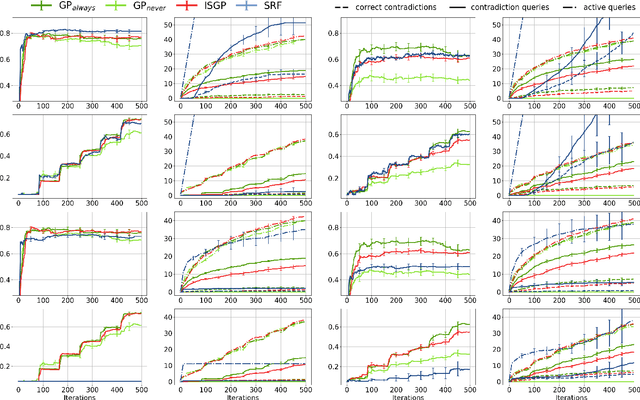

The ability to learn from human supervision is fundamental for personal assistants and other interactive applications of AI. Two central challenges for deploying interactive learners in the wild are the unreliable nature of the supervision and the varying complexity of the prediction task. We address a simple but representative setting, incremental classification in the wild, where the supervision is noisy and the number of classes grows over time. In order to tackle this task, we propose a redesign of skeptical learning centered around Gaussian Processes (GPs). Skeptical learning is a recent interactive strategy in which, if the machine is sufficiently confident that an example is mislabeled, it asks the annotator to reconsider her feedback. In many cases, this is often enough to obtain clean supervision. Our redesign, dubbed ISGP, leverages the uncertainty estimates supplied by GPs to better allocate labeling and contradiction queries, especially in the presence of noise. Our experiments on synthetic and real-world data show that, as a result, while the original formulation of skeptical learning produces over-confident models that can fail completely in the wild, ISGP works well at varying levels of noise and as new classes are observed.
* 7 pages, 3 figures, code: https://gitlab.com/abonte/incremental-skeptical-gp