 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhAME: Phenotype-Aware Molecular Editing via Latent Diffusion
May 27, 2026Small-molecule drug discovery requires simultaneous optimization of numerous properties of candidate molecules. These properties can be investigated through the analysis of high-dimensional biological signatures, such as cell morphology and transcriptomic perturbations, which provide a rich perspective on the underlying biological mechanisms. However, existing generative methods, which use those signatures for optimization, fail to meet two key requirements: providing precise guidance toward desired phenotypic signatures while maintaining structural proximity to a known hit. We introduce PhAME (Phenotype-Aware Molecular Editing), a latent diffusion framework that overcomes this challenge by recasting molecular optimization as editing in the latent space of a pretrained graph-based VAE. Our central contribution is a compositional classifier-free guidance scheme with two independent scales, one for the phenotype-conditioning and one for similarity to the seed structure, allowing practitioners to control the tradeoff between these two objectives. Empirical evaluations across diverse benchmarks, including docking score optimization and multimodal phenotypic generation, demonstrate that PhAME achieves state-of-the-art results while maintaining high chemical validity and novelty.
DAVE: Distribution-aware Attribution via ViT Gradient Decomposition
Feb 06, 2026Vision Transformers (ViTs) have become a dominant architecture in computer vision, yet producing stable and high-resolution attribution maps for these models remains challenging. Architectural components such as patch embeddings and attention routing often introduce structured artifacts in pixel-level explanations, causing many existing methods to rely on coarse patch-level attributions. We introduce DAVE \textit{(\underline{D}istribution-aware \underline{A}ttribution via \underline{V}iT Gradient D\underline{E}composition)}, a mathematically grounded attribution method for ViTs based on a structured decomposition of the input gradient. By exploiting architectural properties of ViTs, DAVE isolates locally equivariant and stable components of the effective input--output mapping. It separates these from architecture-induced artifacts and other sources of instability.
ProtoQuant: Quantization of Prototypical Parts For General and Fine-Grained Image Classification
Feb 06, 2026Prototypical parts-based models offer a "this looks like that" paradigm for intrinsic interpretability, yet they typically struggle with ImageNet-scale generalization and often require computationally expensive backbone finetuning. Furthermore, existing methods frequently suffer from "prototype drift," where learned prototypes lack tangible grounding in the training distribution and change their activation under small perturbations. We present ProtoQuant, a novel architecture that achieves prototype stability and grounded interpretability through latent vector quantization. By constraining prototypes to a discrete learned codebook within the latent space, we ensure they remain faithful representations of the training data without the need to update the backbone. This design allows ProtoQuant to function as an efficient, interpretable head that scales to large-scale datasets. We evaluate ProtoQuant on ImageNet and several fine-grained benchmarks (CUB-200, Cars-196). Our results demonstrate that ProtoQuant achieves competitive classification accuracy while generalizing to ImageNet and comparable interpretability metrics to other prototypical-parts-based methods.
SpaRRTa: A Synthetic Benchmark for Evaluating Spatial Intelligence in Visual Foundation Models
Jan 16, 2026Visual Foundation Models (VFMs), such as DINO and CLIP, excel in semantic understanding of images but exhibit limited spatial reasoning capabilities, which limits their applicability to embodied systems. As a result, recent work incorporates some 3D tasks (such as depth estimation) into VFM training. However, VFM performance remains inconsistent across other spatial tasks, raising the question of whether these models truly have spatial awareness or overfit to specific 3D objectives. To address this question, we introduce the Spatial Relation Recognition Task (SpaRRTa) benchmark, which evaluates the ability of VFMs to identify relative positions of objects in the image. Unlike traditional 3D objectives that focus on precise metric prediction (e.g., surface normal estimation), SpaRRTa probes a fundamental capability underpinning more advanced forms of human-like spatial understanding. SpaRRTa generates an arbitrary number of photorealistic images with diverse scenes and fully controllable object arrangements, along with freely accessible spatial annotations. Evaluating a range of state-of-the-art VFMs, we reveal significant disparities between their spatial reasoning abilities. Through our analysis, we provide insights into the mechanisms that support or hinder spatial awareness in modern VFMs. We hope that SpaRRTa will serve as a useful tool for guiding the development of future spatially aware visual models.
Efficient Multi-Source Knowledge Transfer by Model Merging
Aug 26, 2025While transfer learning is an advantageous strategy, it overlooks the opportunity to leverage knowledge from numerous available models online. Addressing this multi-source transfer learning problem is a promising path to boost adaptability and cut re-training costs. However, existing approaches are inherently coarse-grained, lacking the necessary precision for granular knowledge extraction and the aggregation efficiency required to fuse knowledge from either a large number of source models or those with high parameter counts. We address these limitations by leveraging Singular Value Decomposition (SVD) to first decompose each source model into its elementary, rank-one components. A subsequent aggregation stage then selects only the most salient components from all sources, thereby overcoming the previous efficiency and precision limitations. To best preserve and leverage the synthesized knowledge base, our method adapts to the target task by fine-tuning only the principal singular values of the merged matrix. In essence, this process only recalibrates the importance of top SVD components. The proposed framework allows for efficient transfer learning, is robust to perturbations both at the input level and in the parameter space (e.g., noisy or pruned sources), and scales well computationally.
Fragment-Wise Interpretability in Graph Neural Networks via Molecule Decomposition and Contribution Analysis
Aug 20, 2025Graph neural networks have demonstrated remarkable success in predicting molecular properties by leveraging the rich structural information encoded in molecular graphs. However, their black-box nature reduces interpretability, which limits trust in their predictions for important applications such as drug discovery and materials design. Furthermore, existing explanation techniques often fail to reliably quantify the contribution of individual atoms or substructures due to the entangled message-passing dynamics. We introduce SEAL (Substructure Explanation via Attribution Learning), a new interpretable graph neural network that attributes model predictions to meaningful molecular subgraphs. SEAL decomposes input graphs into chemically relevant fragments and estimates their causal influence on the output. The strong alignment between fragment contributions and model predictions is achieved by explicitly reducing inter-fragment message passing in our proposed model architecture. Extensive evaluations on synthetic benchmarks and real-world molecular datasets demonstrate that SEAL outperforms other explainability methods in both quantitative attribution metrics and human-aligned interpretability. A user study further confirms that SEAL provides more intuitive and trustworthy explanations to domain experts. By bridging the gap between predictive performance and interpretability, SEAL offers a promising direction for more transparent and actionable molecular modeling.
Personalized Interpretability -- Interactive Alignment of Prototypical Parts Networks
Jun 05, 2025Concept-based interpretable neural networks have gained significant attention due to their intuitive and easy-to-understand explanations based on case-based reasoning, such as "this bird looks like those sparrows". However, a major limitation is that these explanations may not always be comprehensible to users due to concept inconsistency, where multiple visual features are inappropriately mixed (e.g., a bird's head and wings treated as a single concept). This inconsistency breaks the alignment between model reasoning and human understanding. Furthermore, users have specific preferences for how concepts should look, yet current approaches provide no mechanism for incorporating their feedback. To address these issues, we introduce YoursProtoP, a novel interactive strategy that enables the personalization of prototypical parts - the visual concepts used by the model - according to user needs. By incorporating user supervision, YoursProtoP adapts and splits concepts used for both prediction and explanation to better match the user's preferences and understanding. Through experiments on both the synthetic FunnyBirds dataset and a real-world scenario using the CUB, CARS, and PETS datasets in a comprehensive user study, we demonstrate the effectiveness of YoursProtoP in achieving concept consistency without compromising the accuracy of the model.
AI-Driven Rapid Identification of Bacterial and Fungal Pathogens in Blood Smears of Septic Patients
Mar 17, 2025Sepsis is a life-threatening condition which requires rapid diagnosis and treatment. Traditional microbiological methods are time-consuming and expensive. In response to these challenges, deep learning algorithms were developed to identify 14 bacteria species and 3 yeast-like fungi from microscopic images of Gram-stained smears of positive blood samples from sepsis patients. A total of 16,637 Gram-stained microscopic images were used in the study. The analysis used the Cellpose 3 model for segmentation and Attention-based Deep Multiple Instance Learning for classification. Our model achieved an accuracy of 77.15% for bacteria and 71.39% for fungi, with ROC AUC of 0.97 and 0.88, respectively. The highest values, reaching up to 96.2%, were obtained for Cutibacterium acnes, Enterococcus faecium, Stenotrophomonas maltophilia and Nakaseomyces glabratus. Classification difficulties were observed in closely related species, such as Staphylococcus hominis and Staphylococcus haemolyticus, due to morphological similarity, and within Candida albicans due to high morphotic diversity. The study confirms the potential of our model for microbial classification, but it also indicates the need for further optimisation and expansion of the training data set. In the future, this technology could support microbial diagnosis, reducing diagnostic time and improving the effectiveness of sepsis treatment due to its simplicity and accessibility. Part of the results presented in this publication was covered by a patent application at the European Patent Office EP24461637.1 "A computer implemented method for identifying a microorganism in a blood and a data processing system therefor".
This looks like what? Challenges and Future Research Directions for Part-Prototype Models
Feb 13, 2025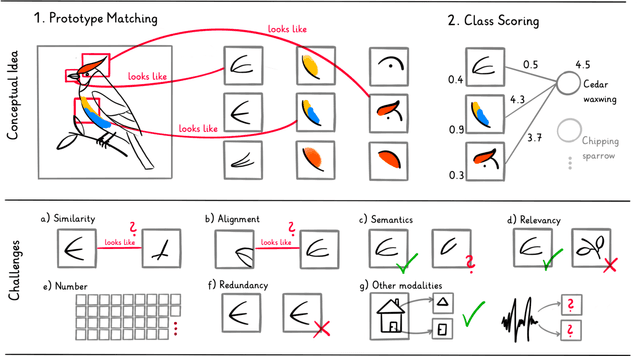
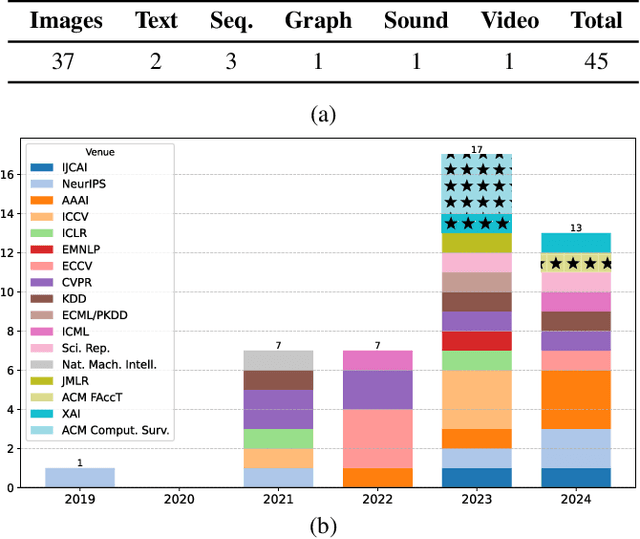
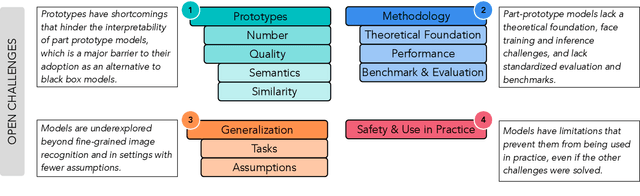
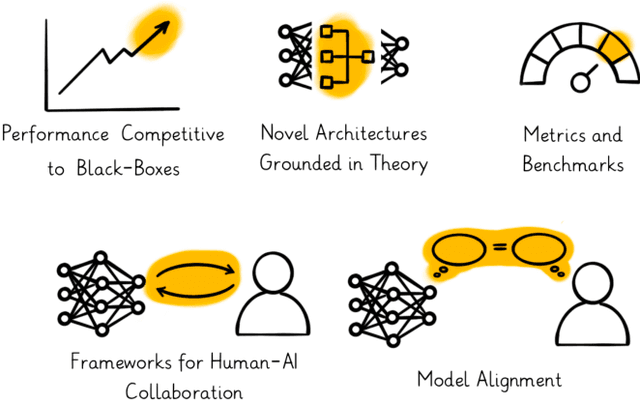
The growing interest in eXplainable Artificial Intelligence (XAI) has prompted research into models with built-in interpretability, the most prominent of which are part-prototype models. Part-Prototype Models (PPMs) make decisions by comparing an input image to a set of learned prototypes, providing human-understandable explanations in the form of ``this looks like that''. Despite their inherent interpretability, PPMS are not yet considered a valuable alternative to post-hoc models. In this survey, we investigate the reasons for this and provide directions for future research. We analyze papers from 2019 to 2024, and derive a taxonomy of the challenges that current PPMS face. Our analysis shows that the open challenges are quite diverse. The main concern is the quality and quantity of prototypes. Other concerns are the lack of generalization to a variety of tasks and contexts, and general methodological issues, including non-standardized evaluation. We provide ideas for future research in five broad directions: improving predictive performance, developing novel architectures grounded in theory, establishing frameworks for human-AI collaboration, aligning models with humans, and establishing metrics and benchmarks for evaluation. We hope that this survey will stimulate research and promote intrinsically interpretable models for application domains. Our list of surveyed papers is available at https://github.com/aix-group/ppm-survey.
Parameter-Efficient Interventions for Enhanced Model Merging
Dec 22, 2024



Model merging combines knowledge from task-specific models into a unified multi-task model to avoid joint training on all task data. However, current methods face challenges due to representation bias, which can interfere with tasks performance. As a remedy, we propose IntervMerge, a novel approach to multi-task model merging that effectively mitigates representation bias across the model using taskspecific interventions. To further enhance its efficiency, we introduce mini-interventions, which modify only part of the representation, thereby reducing the additional parameters without compromising performance. Experimental results demonstrate that IntervMerge consistently outperforms the state-of-the-art approaches using fewer parameters.