 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-Source Knowledge Transfer by Model Merging
Aug 26, 2025While transfer learning is an advantageous strategy, it overlooks the opportunity to leverage knowledge from numerous available models online. Addressing this multi-source transfer learning problem is a promising path to boost adaptability and cut re-training costs. However, existing approaches are inherently coarse-grained, lacking the necessary precision for granular knowledge extraction and the aggregation efficiency required to fuse knowledge from either a large number of source models or those with high parameter counts. We address these limitations by leveraging Singular Value Decomposition (SVD) to first decompose each source model into its elementary, rank-one components. A subsequent aggregation stage then selects only the most salient components from all sources, thereby overcoming the previous efficiency and precision limitations. To best preserve and leverage the synthesized knowledge base, our method adapts to the target task by fine-tuning only the principal singular values of the merged matrix. In essence, this process only recalibrates the importance of top SVD components. The proposed framework allows for efficient transfer learning, is robust to perturbations both at the input level and in the parameter space (e.g., noisy or pruned sources), and scales well computationally.
Maybe I Should Not Answer That, but... Do LLMs Understand The Safety of Their Inputs?
Feb 22, 2025



Ensuring the safety of the Large Language Model (LLM) is critical, but currently used methods in most cases sacrifice the model performance to obtain increased safety or perform poorly on data outside of their adaptation distribution. We investigate existing methods for such generalization and find them insufficient. Surprisingly, while even plain LLMs recognize unsafe prompts, they may still generate unsafe responses. To avoid performance degradation and preserve safe performance, we advocate for a two-step framework, where we first identify unsafe prompts via a lightweight classifier, and apply a "safe" model only to such prompts. In particular, we explore the design of the safety detector in more detail, investigating the use of different classifier architectures and prompting techniques. Interestingly, we find that the final hidden state for the last token is enough to provide robust performance, minimizing false positives on benign data while performing well on malicious prompt detection. Additionally, we show that classifiers trained on the representations from different model layers perform comparably on the latest model layers, indicating that safety representation is present in the LLMs' hidden states at most model stages. Our work is a step towards efficient, representation-based safety mechanisms for LLMs.
Joint or Disjoint: Mixing Training Regimes for Early-Exit Models
Jul 19, 2024Early exits are an important efficiency mechanism integrated into deep neural networks that allows for the termination of the network's forward pass before processing through all its layers. By allowing early halting of the inference process for less complex inputs that reached high confidence, early exits significantly reduce the amount of computation required. Early exit methods add trainable internal classifiers which leads to more intricacy in the training process. However, there is no consistent verification of the approaches of training of early exit methods, and no unified scheme of training such models. Most early exit methods employ a training strategy that either simultaneously trains the backbone network and the exit heads or trains the exit heads separately. We propose a training approach where the backbone is initially trained on its own, followed by a phase where both the backbone and the exit heads are trained together. Thus, we advocate for organizing early-exit training strategies into three distinct categories, and then validate them for their performance and efficiency. In this benchmark, we perform both theoretical and empirical analysis of early-exit training regimes. We study the methods in terms of information flow, loss landscape and numerical rank of activations and gauge the suitability of regimes for various architectures and datasets.
Adaptive Computation Modules: Granular Conditional Computation For Efficient Inference
Dec 15, 2023The computational cost of transformer models makes them inefficient in low-latency or low-power applications. While techniques such as quantization or linear attention can reduce the computational load, they may incur a reduction in accuracy. In addition, globally reducing the cost for all inputs may be sub-optimal. We observe that for each layer, the full width of the layer may be needed only for a small subset of tokens inside a batch and that the "effective" width needed to process a token can vary from layer to layer. Motivated by this observation, we introduce the Adaptive Computation Module (ACM), a generic module that dynamically adapts its computational load to match the estimated difficulty of the input on a per-token basis. An ACM consists of a sequence of learners that progressively refine the output of their preceding counterparts. An additional gating mechanism determines the optimal number of learners to execute for each token. We also describe a distillation technique to replace any pre-trained model with an "ACMized" variant. The distillation phase is designed to be highly parallelizable across layers while being simple to plug-and-play into existing networks. Our evaluation of transformer models in computer vision and speech recognition demonstrates that substituting layers with ACMs significantly reduces inference costs without degrading the downstream accuracy for a wide interval of user-defined budgets.
Exploiting Transformer Activation Sparsity with Dynamic Inference
Oct 06, 2023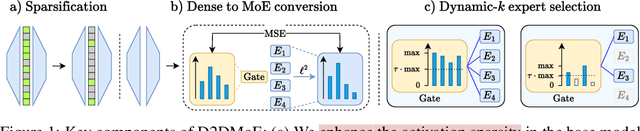
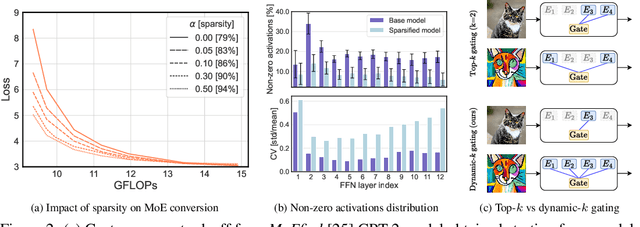
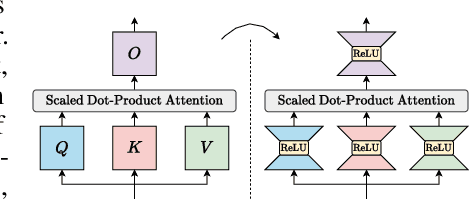
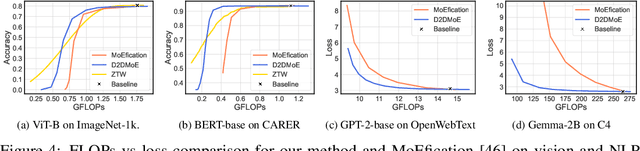
Transformer models, despite their impressive performance, often face practical limitations due to their high computational requirements. At the same time, previous studies have revealed significant activation sparsity in these models, indicating the presence of redundant computations. In this paper, we propose Dynamic Sparsified Transformer Inference (DSTI), a method that radically reduces the inference cost of Transformer models by enforcing activation sparsity and subsequently transforming a dense model into its sparse Mixture of Experts (MoE) version. We demonstrate that it is possible to train small gating networks that successfully predict the relative contribution of each expert during inference. Furthermore, we introduce a mechanism that dynamically determines the number of executed experts individually for each token. DSTI can be applied to any Transformer-based architecture and has negligible impact on the accuracy. For the BERT-base classification model, we reduce inference cost by almost 60%.
Face Identity-Aware Disentanglement in StyleGAN
Sep 21, 2023



Conditional GANs are frequently used for manipulating the attributes of face images, such as expression, hairstyle, pose, or age. Even though the state-of-the-art models successfully modify the requested attributes, they simultaneously modify other important characteristics of the image, such as a person's identity. In this paper, we focus on solving this problem by introducing PluGeN4Faces, a plugin to StyleGAN, which explicitly disentangles face attributes from a person's identity. Our key idea is to perform training on images retrieved from movie frames, where a given person appears in various poses and with different attributes. By applying a type of contrastive loss, we encourage the model to group images of the same person in similar regions of latent space. Our experiments demonstrate that the modifications of face attributes performed by PluGeN4Faces are significantly less invasive on the remaining characteristics of the image than in the existing state-of-the-art models.
Computer Vision based inspection on post-earthquake with UAV synthetic dataset
Oct 11, 2022

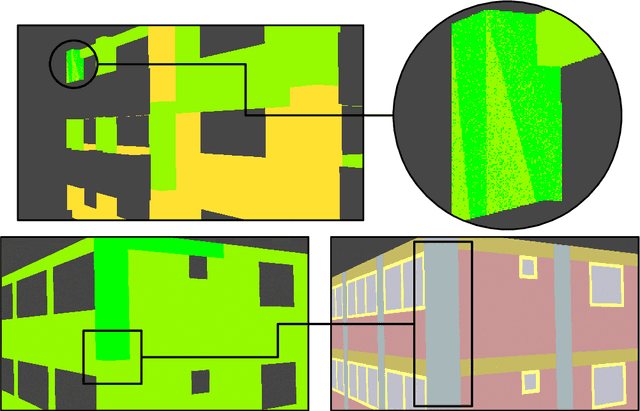

The area affected by the earthquake is vast and often difficult to entirely cover, and the earthquake itself is a sudden event that causes multiple defects simultaneously, that cannot be effectively traced using traditional, manual methods. This article presents an innovative approach to the problem of detecting damage after sudden events by using an interconnected set of deep machine learning models organized in a single pipeline and allowing for easy modification and swapping models seamlessly. Models in the pipeline were trained with a synthetic dataset and were adapted to be further evaluated and used with unmanned aerial vehicles (UAVs) in real-world conditions. Thanks to the methods presented in the article, it is possible to obtain high accuracy in detecting buildings defects, segmenting constructions into their components and estimating their technical condition based on a single drone flight.
SLOVA: Uncertainty Estimation Using Single Label One-Vs-All Classifier
Jun 28, 2022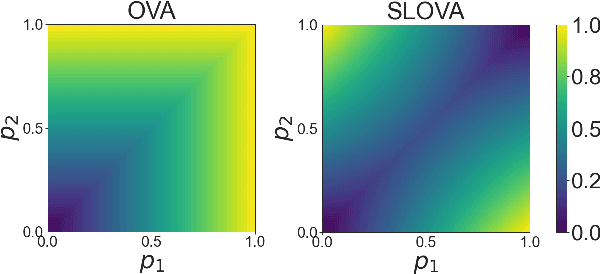
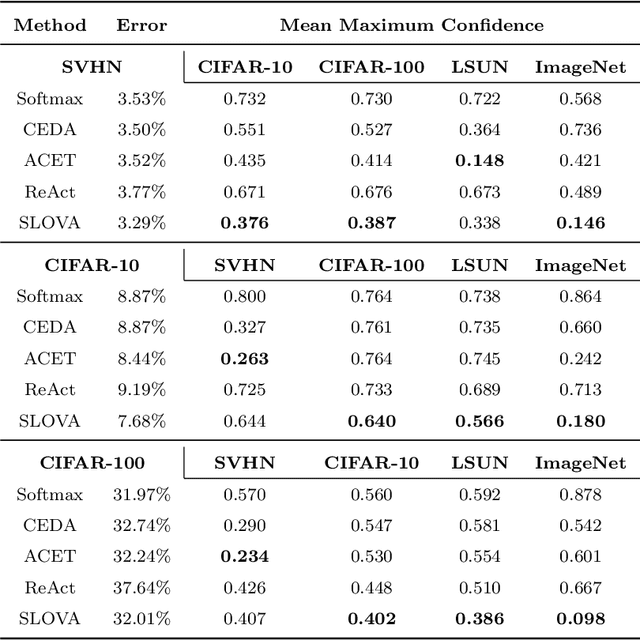
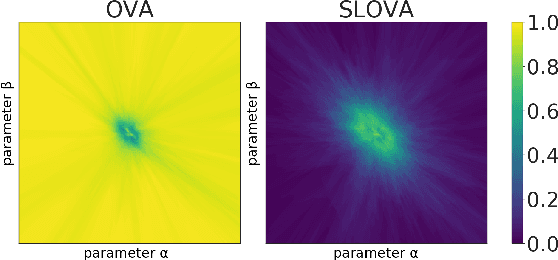

Deep neural networks present impressive performance, yet they cannot reliably estimate their predictive confidence, limiting their applicability in high-risk domains. We show that applying a multi-label one-vs-all loss reveals classification ambiguity and reduces model overconfidence. The introduced SLOVA (Single Label One-Vs-All) model redefines typical one-vs-all predictive probabilities to a single label situation, where only one class is the correct answer. The proposed classifier is confident only if a single class has a high probability and other probabilities are negligible. Unlike the typical softmax function, SLOVA naturally detects out-of-distribution samples if the probabilities of all other classes are small. The model is additionally fine-tuned with exponential calibration, which allows us to precisely align the confidence score with model accuracy. We verify our approach on three tasks. First, we demonstrate that SLOVA is competitive with the state-of-the-art on in-distribution calibration. Second, the performance of SLOVA is robust under dataset shifts. Finally, our approach performs extremely well in the detection of out-of-distribution samples. Consequently, SLOVA is a tool that can be used in various applications where uncertainty modeling is required.
Continual Learning with Guarantees via Weight Interval Constraints
Jun 16, 2022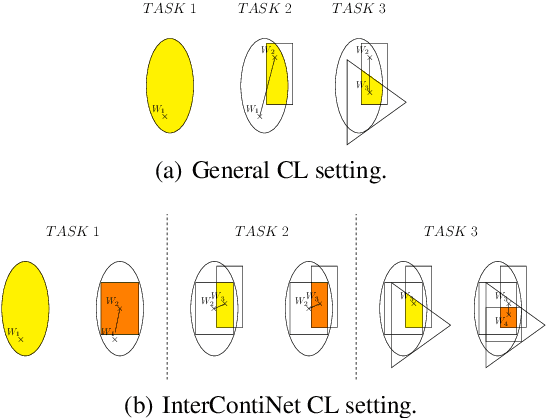



We introduce a new training paradigm that enforces interval constraints on neural network parameter space to control forgetting. Contemporary Continual Learning (CL) methods focus on training neural networks efficiently from a stream of data, while reducing the negative impact of catastrophic forgetting, yet they do not provide any firm guarantees that network performance will not deteriorate uncontrollably over time. In this work, we show how to put bounds on forgetting by reformulating continual learning of a model as a continual contraction of its parameter space. To that end, we propose Hyperrectangle Training, a new training methodology where each task is represented by a hyperrectangle in the parameter space, fully contained in the hyperrectangles of the previous tasks. This formulation reduces the NP-hard CL problem back to polynomial time while providing full resilience against forgetting. We validate our claim by developing InterContiNet (Interval Continual Learning) algorithm which leverages interval arithmetic to effectively model parameter regions as hyperrectangles. Through experimental results, we show that our approach performs well in a continual learning setup without storing data from previous tasks.
Hard hat wearing detection based on head keypoint localization
Jun 21, 2021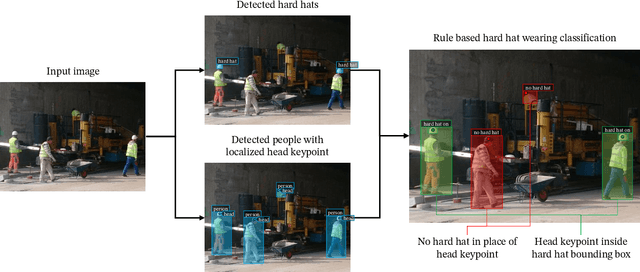
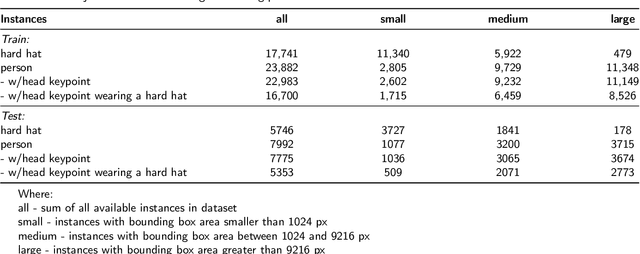
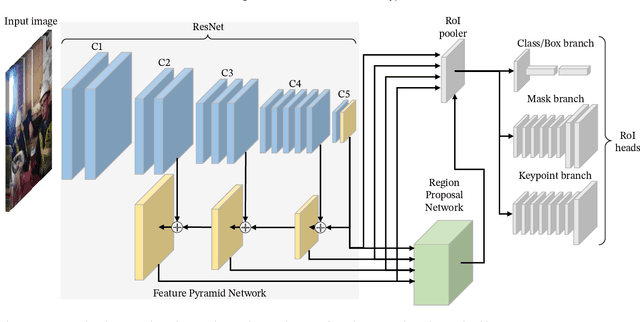
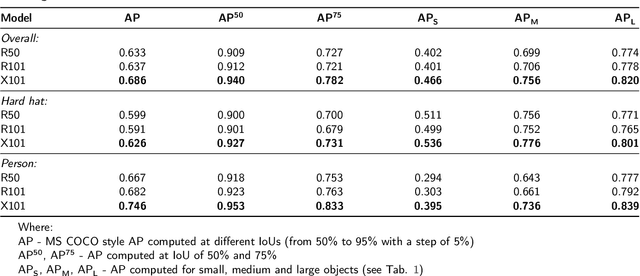
In recent years, a lot of attention is paid to deep learning methods in the context of vision-based construction site safety systems, especially regarding personal protective equipment. However, despite all this attention, there is still no reliable way to establish the relationship between workers and their hard hats. To answer this problem a combination of deep learning, object detection and head keypoint localization, with simple rule-based reasoning is proposed in this article. In tests, this solution surpassed the previous methods based on the relative bounding box position of different instances, as well as direct detection of hard hat wearers and non-wearers. The results show that the conjunction of novel deep learning methods with humanly-interpretable rule-based systems can result in a solution that is both reliable and can successfully mimic manual, on-site supervision. This work is the next step in the development of fully autonomous construction site safety systems and shows that there is still room for improvement in this area.