 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Recognition: Evaluating Visual Perspective Taking in Vision Language Models
May 03, 2025We investigate the ability of Vision Language Models (VLMs) to perform visual perspective taking using a novel set of visual tasks inspired by established human tests. Our approach leverages carefully controlled scenes, in which a single humanoid minifigure is paired with a single object. By systematically varying spatial configurations - such as object position relative to the humanoid minifigure and the humanoid minifigure's orientation - and using both bird's-eye and surface-level views, we created 144 unique visual tasks. Each visual task is paired with a series of 7 diagnostic questions designed to assess three levels of visual cognition: scene understanding, spatial reasoning, and visual perspective taking. Our evaluation of several state-of-the-art models, including GPT-4-Turbo, GPT-4o, Llama-3.2-11B-Vision-Instruct, and variants of Claude Sonnet, reveals that while they excel in scene understanding, the performance declines significantly on spatial reasoning and further deteriorates on perspective-taking. Our analysis suggests a gap between surface-level object recognition and the deeper spatial and perspective reasoning required for complex visual tasks, pointing to the need for integrating explicit geometric representations and tailored training protocols in future VLM development.
State Soup: In-Context Skill Learning, Retrieval and Mixing
Jun 12, 2024A new breed of gated-linear recurrent neural networks has reached state-of-the-art performance on a range of sequence modeling problems. Such models naturally handle long sequences efficiently, as the cost of processing a new input is independent of sequence length. Here, we explore another advantage of these stateful sequence models, inspired by the success of model merging through parameter interpolation. Building on parallels between fine-tuning and in-context learning, we investigate whether we can treat internal states as task vectors that can be stored, retrieved, and then linearly combined, exploiting the linearity of recurrence. We study this form of fast model merging on Mamba-2.8b, a pretrained recurrent model, and present preliminary evidence that simple linear state interpolation methods suffice to improve next-token perplexity as well as downstream in-context learning task performance.
AdaGlimpse: Active Visual Exploration with Arbitrary Glimpse Position and Scale
Apr 04, 2024Active Visual Exploration (AVE) is a task that involves dynamically selecting observations (glimpses), which is critical to facilitate comprehension and navigation within an environment. While modern AVE methods have demonstrated impressive performance, they are constrained to fixed-scale glimpses from rigid grids. In contrast, existing mobile platforms equipped with optical zoom capabilities can capture glimpses of arbitrary positions and scales. To address this gap between software and hardware capabilities, we introduce AdaGlimpse. It uses Soft Actor-Critic, a reinforcement learning algorithm tailored for exploration tasks, to select glimpses of arbitrary position and scale. This approach enables our model to rapidly establish a general awareness of the environment before zooming in for detailed analysis. Experimental results demonstrate that AdaGlimpse surpasses previous methods across various visual tasks while maintaining greater applicability in realistic AVE scenarios.
Fine-tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem
Feb 05, 2024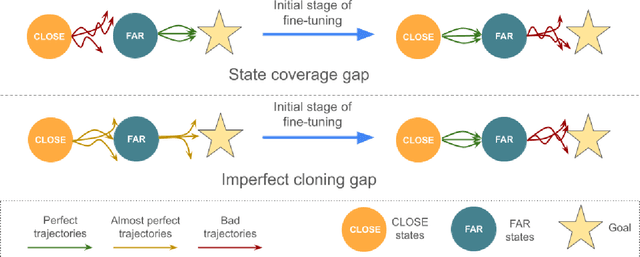
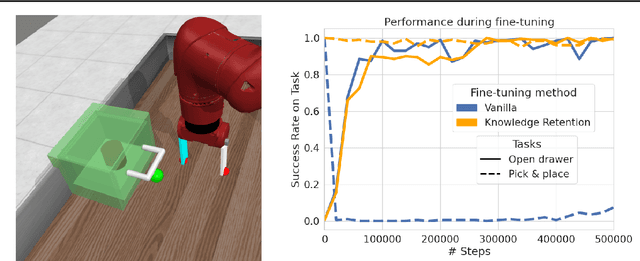
Fine-tuning is a widespread technique that allows practitioners to transfer pre-trained capabilities, as recently showcased by the successful applications of foundation models. However, fine-tuning reinforcement learning (RL) models remains a challenge. This work conceptualizes one specific cause of poor transfer, accentuated in the RL setting by the interplay between actions and observations: forgetting of pre-trained capabilities. Namely, a model deteriorates on the state subspace of the downstream task not visited in the initial phase of fine-tuning, on which the model behaved well due to pre-training. This way, we lose the anticipated transfer benefits. We identify conditions when this problem occurs, showing that it is common and, in many cases, catastrophic. Through a detailed empirical analysis of the challenging NetHack and Montezuma's Revenge environments, we show that standard knowledge retention techniques mitigate the problem and thus allow us to take full advantage of the pre-trained capabilities. In particular, in NetHack, we achieve a new state-of-the-art for neural models, improving the previous best score from $5$K to over $10$K points in the Human Monk scenario.
Discovering modular solutions that generalize compositionally
Dec 22, 2023Many complex tasks and environments can be decomposed into simpler, independent parts. Discovering such underlying compositional structure has the potential to expedite adaptation and enable compositional generalization. Despite progress, our most powerful systems struggle to compose flexibly. While most of these systems are monolithic, modularity promises to allow capturing the compositional nature of many tasks. However, it is unclear under which circumstances modular systems discover this hidden compositional structure. To shed light on this question, we study a teacher-student setting with a modular teacher where we have full control over the composition of ground truth modules. This allows us to relate the problem of compositional generalization to that of identification of the underlying modules. We show theoretically that identification up to linear transformation purely from demonstrations is possible in hypernetworks without having to learn an exponential number of module combinations. While our theory assumes the infinite data limit, in an extensive empirical study we demonstrate how meta-learning from finite data can discover modular solutions that generalize compositionally in modular but not monolithic architectures. We further show that our insights translate outside the teacher-student setting and demonstrate that in tasks with compositional preferences and tasks with compositional goals hypernetworks can discover modular policies that compositionally generalize.
Disentangling Transfer in Continual Reinforcement Learning
Sep 28, 2022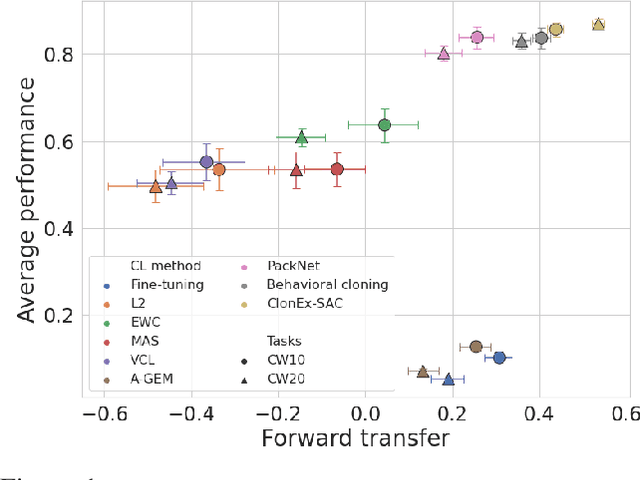
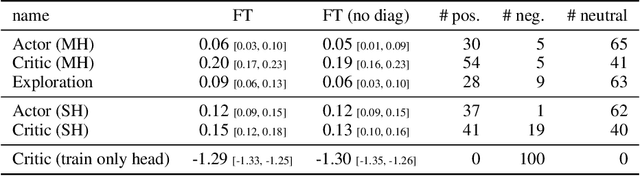
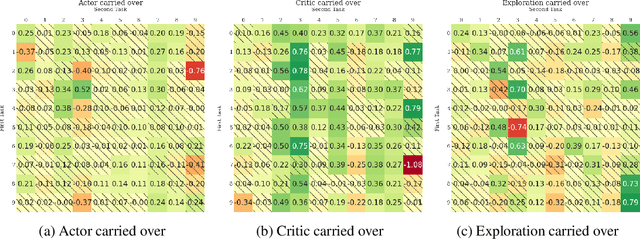
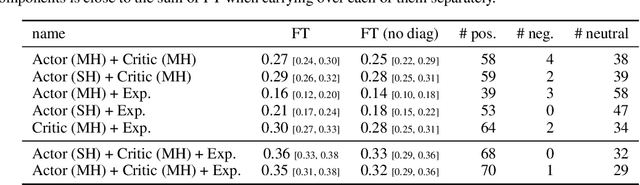
The ability of continual learning systems to transfer knowledge from previously seen tasks in order to maximize performance on new tasks is a significant challenge for the field, limiting the applicability of continual learning solutions to realistic scenarios. Consequently, this study aims to broaden our understanding of transfer and its driving forces in the specific case of continual reinforcement learning. We adopt SAC as the underlying RL algorithm and Continual World as a suite of continuous control tasks. We systematically study how different components of SAC (the actor and the critic, exploration, and data) affect transfer efficacy, and we provide recommendations regarding various modeling options. The best set of choices, dubbed ClonEx-SAC, is evaluated on the recent Continual World benchmark. ClonEx-SAC achieves 87% final success rate compared to 80% of PackNet, the best method in the benchmark. Moreover, the transfer grows from 0.18 to 0.54 according to the metric provided by Continual World.
Continual Learning with Guarantees via Weight Interval Constraints
Jun 16, 2022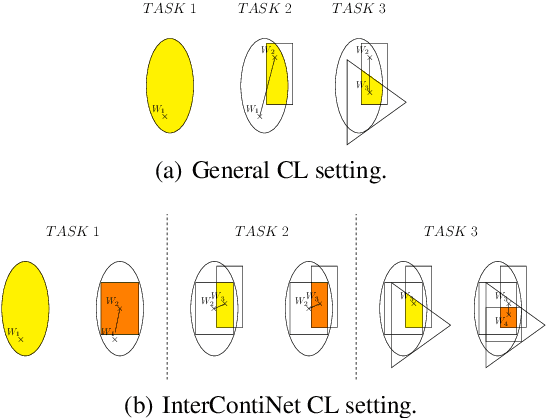



We introduce a new training paradigm that enforces interval constraints on neural network parameter space to control forgetting. Contemporary Continual Learning (CL) methods focus on training neural networks efficiently from a stream of data, while reducing the negative impact of catastrophic forgetting, yet they do not provide any firm guarantees that network performance will not deteriorate uncontrollably over time. In this work, we show how to put bounds on forgetting by reformulating continual learning of a model as a continual contraction of its parameter space. To that end, we propose Hyperrectangle Training, a new training methodology where each task is represented by a hyperrectangle in the parameter space, fully contained in the hyperrectangles of the previous tasks. This formulation reduces the NP-hard CL problem back to polynomial time while providing full resilience against forgetting. We validate our claim by developing InterContiNet (Interval Continual Learning) algorithm which leverages interval arithmetic to effectively model parameter regions as hyperrectangles. Through experimental results, we show that our approach performs well in a continual learning setup without storing data from previous tasks.
On the relationship between disentanglement and multi-task learning
Oct 07, 2021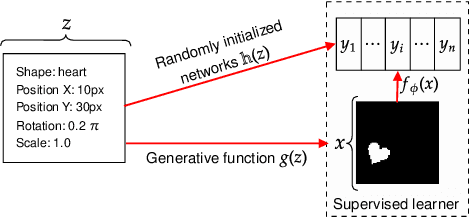

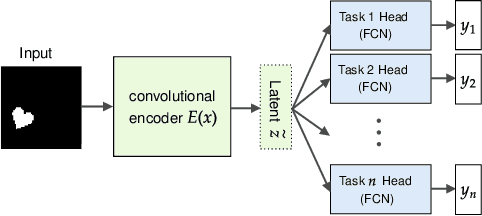
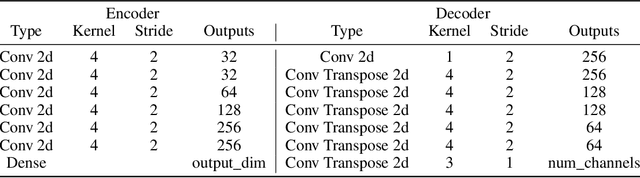
One of the main arguments behind studying disentangled representations is the assumption that they can be easily reused in different tasks. At the same time finding a joint, adaptable representation of data is one of the key challenges in the multi-task learning setting. In this paper, we take a closer look at the relationship between disentanglement and multi-task learning based on hard parameter sharing. We perform a thorough empirical study of the representations obtained by neural networks trained on automatically generated supervised tasks. Using a set of standard metrics we show that disentanglement appears naturally during the process of multi-task neural network training.
SafetyNet: Safe planning for real-world self-driving vehicles using machine-learned policies
Sep 28, 2021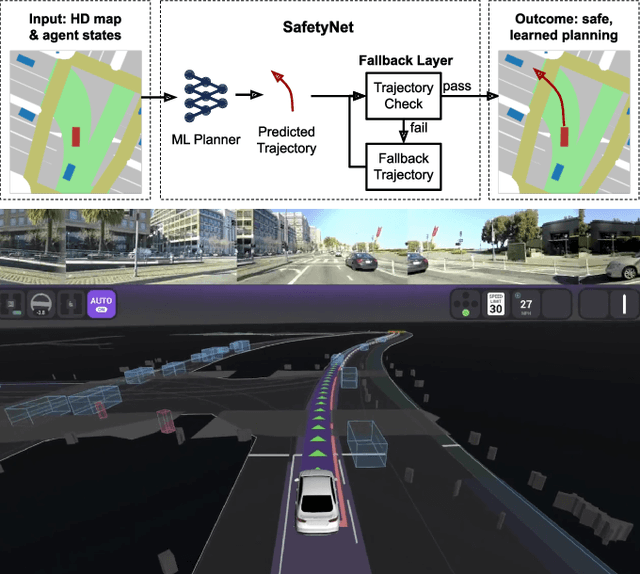
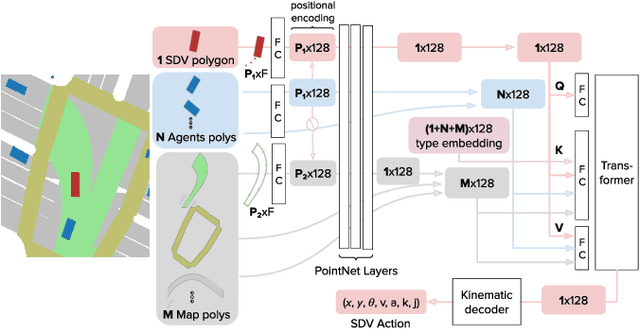
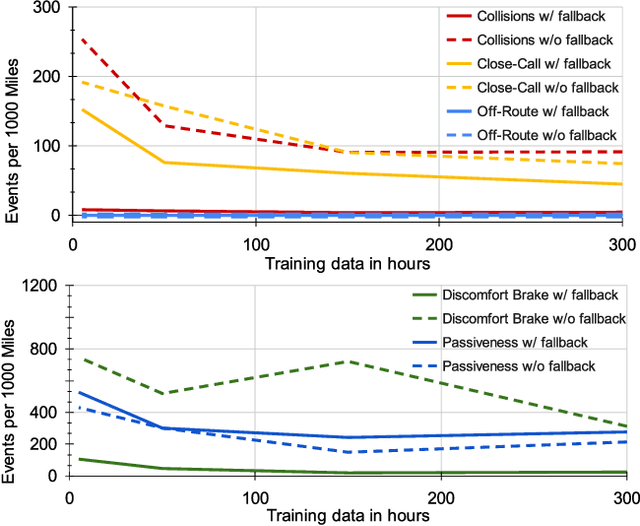
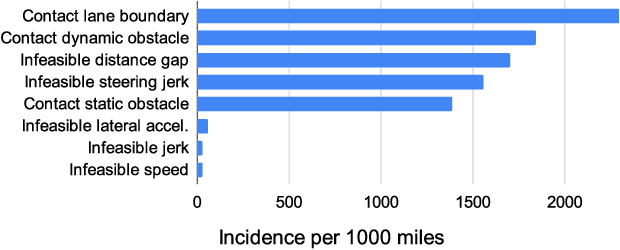
In this paper we present the first safe system for full control of self-driving vehicles trained from human demonstrations and deployed in challenging, real-world, urban environments. Current industry-standard solutions use rule-based systems for planning. Although they perform reasonably well in common scenarios, the engineering complexity renders this approach incompatible with human-level performance. On the other hand, the performance of machine-learned (ML) planning solutions can be improved by simply adding more exemplar data. However, ML methods cannot offer safety guarantees and sometimes behave unpredictably. To combat this, our approach uses a simple yet effective rule-based fallback layer that performs sanity checks on an ML planner's decisions (e.g. avoiding collision, assuring physical feasibility). This allows us to leverage ML to handle complex situations while still assuring the safety, reducing ML planner-only collisions by 95%. We train our ML planner on 300 hours of expert driving demonstrations using imitation learning and deploy it along with the fallback layer in downtown San Francisco, where it takes complete control of a real vehicle and navigates a wide variety of challenging urban driving scenarios.
Urban Driver: Learning to Drive from Real-world Demonstrations Using Policy Gradients
Sep 27, 2021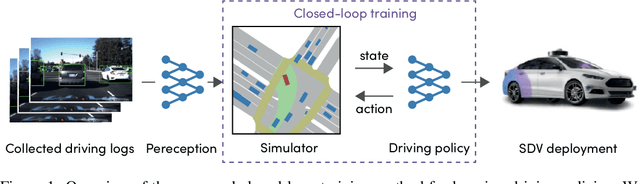

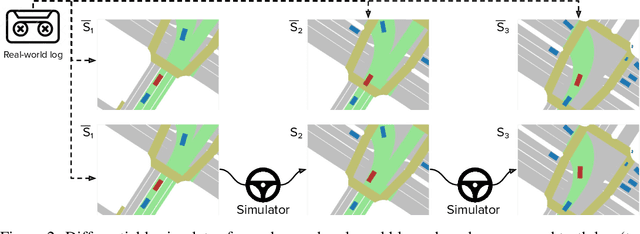
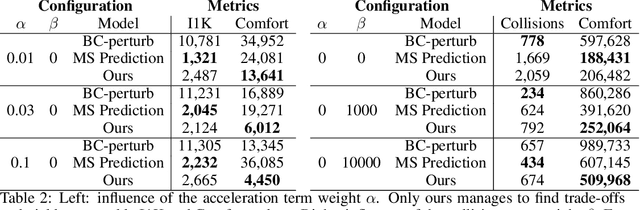
In this work we are the first to present an offline policy gradient method for learning imitative policies for complex urban driving from a large corpus of real-world demonstrations. This is achieved by building a differentiable data-driven simulator on top of perception outputs and high-fidelity HD maps of the area. It allows us to synthesize new driving experiences from existing demonstrations using mid-level representations. Using this simulator we then train a policy network in closed-loop employing policy gradients. We train our proposed method on 100 hours of expert demonstrations on urban roads and show that it learns complex driving policies that generalize well and can perform a variety of driving maneuvers. We demonstrate this in simulation as well as deploy our model to self-driving vehicles in the real-world. Our method outperforms previously demonstrated state-of-the-art for urban driving scenarios -- all this without the need for complex state perturbations or collecting additional on-policy data during training. We make code and data publicly available.