 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriverGym: Democratising Reinforcement Learning for Autonomous Driving
Nov 12, 2021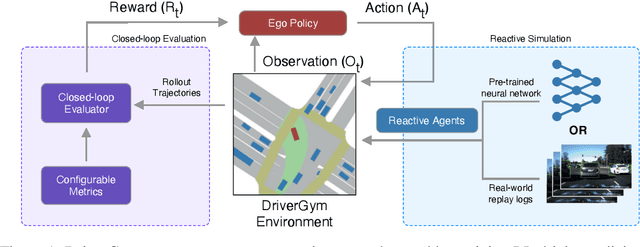


Despite promising progress in reinforcement learning (RL), developing algorithms for autonomous driving (AD) remains challenging: one of the critical issues being the absence of an open-source platform capable of training and effectively validating the RL policies on real-world data. We propose DriverGym, an open-source OpenAI Gym-compatible environment specifically tailored for developing RL algorithms for autonomous driving. DriverGym provides access to more than 1000 hours of expert logged data and also supports reactive and data-driven agent behavior. The performance of an RL policy can be easily validated on real-world data using our extensive and flexible closed-loop evaluation protocol. In this work, we also provide behavior cloning baselines using supervised learning and RL, trained in DriverGym. We make DriverGym code, as well as all the baselines publicly available to further stimulate development from the community.
Urban Driver: Learning to Drive from Real-world Demonstrations Using Policy Gradients
Sep 27, 2021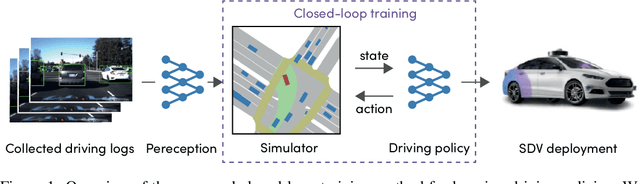

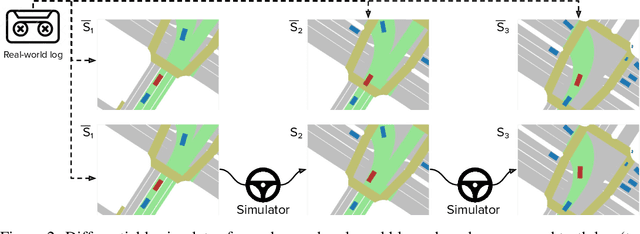
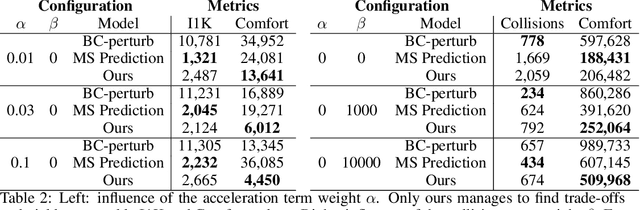
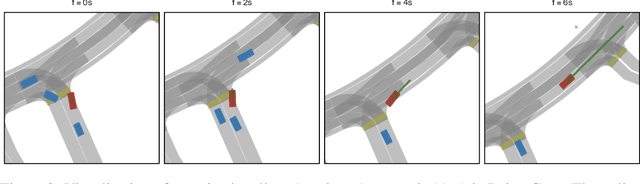
In this work we are the first to present an offline policy gradient method for learning imitative policies for complex urban driving from a large corpus of real-world demonstrations. This is achieved by building a differentiable data-driven simulator on top of perception outputs and high-fidelity HD maps of the area. It allows us to synthesize new driving experiences from existing demonstrations using mid-level representations. Using this simulator we then train a policy network in closed-loop employing policy gradients. We train our proposed method on 100 hours of expert demonstrations on urban roads and show that it learns complex driving policies that generalize well and can perform a variety of driving maneuvers. We demonstrate this in simulation as well as deploy our model to self-driving vehicles in the real-world. Our method outperforms previously demonstrated state-of-the-art for urban driving scenarios -- all this without the need for complex state perturbations or collecting additional on-policy data during training. We make code and data publicly available.
SimNet: Learning Reactive Self-driving Simulations from Real-world Observations
May 26, 2021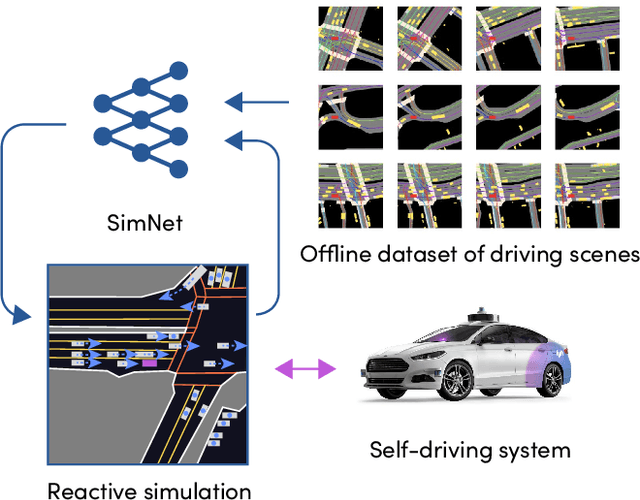
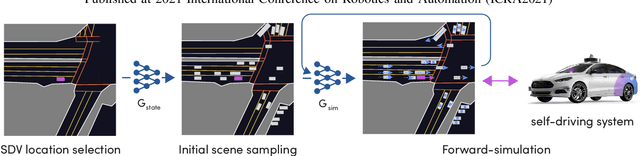
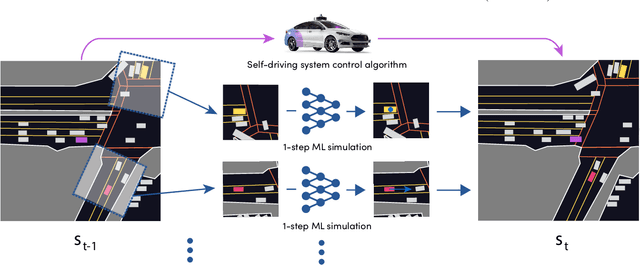
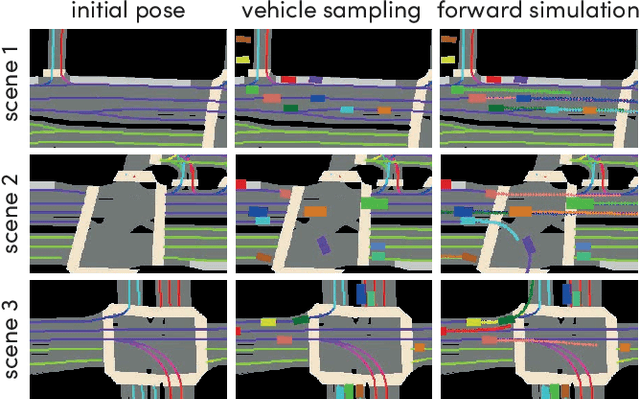
In this work, we present a simple end-to-end trainable machine learning system capable of realistically simulating driving experiences. This can be used for the verification of self-driving system performance without relying on expensive and time-consuming road testing. In particular, we frame the simulation problem as a Markov Process, leveraging deep neural networks to model both state distribution and transition function. These are trainable directly from the existing raw observations without the need for any handcrafting in the form of plant or kinematic models. All that is needed is a dataset of historical traffic episodes. Our formulation allows the system to construct never seen scenes that unfold realistically reacting to the self-driving car's behaviour. We train our system directly from 1,000 hours of driving logs and measure both realism, reactivity of the simulation as the two key properties of the simulation. At the same time, we apply the method to evaluate the performance of a recently proposed state-of-the-art ML planning system trained from human driving logs. We discover this planning system is prone to previously unreported causal confusion issues that are difficult to test by non-reactive simulation. To the best of our knowledge, this is the first work that directly merges highly realistic data-driven simulations with a closed-loop evaluation for self-driving vehicles. We make the data, code, and pre-trained models publicly available to further stimulate simulation development.
Robust Re-Identification by Multiple Views Knowledge Distillation
Jul 08, 2020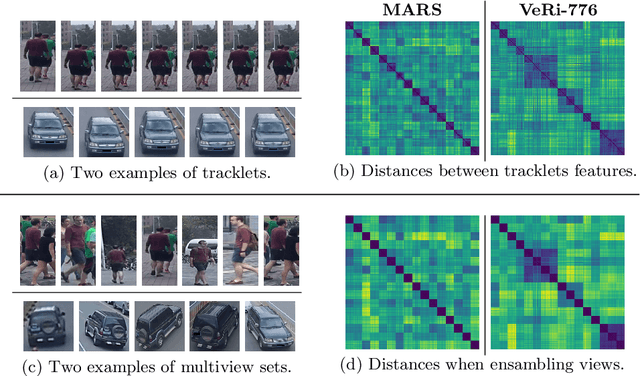
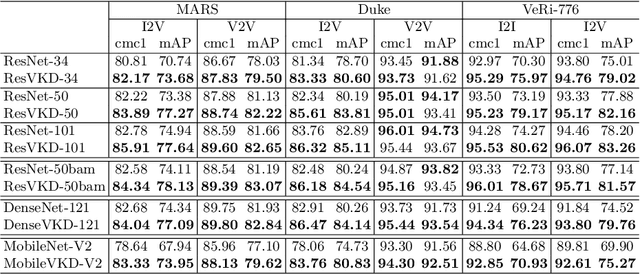

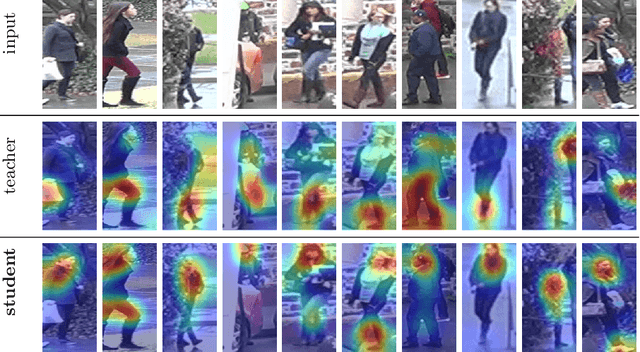
To achieve robustness in Re-Identification, standard methods leverage tracking information in a Video-To-Video fashion. However, these solutions face a large drop in performance for single image queries (e.g., Image-To-Video setting). Recent works address this severe degradation by transferring temporal information from a Video-based network to an Image-based one. In this work, we devise a training strategy that allows the transfer of a superior knowledge, arising from a set of views depicting the target object. Our proposal - Views Knowledge Distillation (VKD) - pins this visual variety as a supervision signal within a teacher-student framework, where the teacher educates a student who observes fewer views. As a result, the student outperforms not only its teacher but also the current state-of-the-art in Image-To-Video by a wide margin (6.3% mAP on MARS, 8.6% on Duke-Video-ReId and 5% on VeRi-776). A thorough analysis - on Person, Vehicle and Animal Re-ID - investigates the properties of VKD from a qualitatively and quantitatively perspective. Code is available at https://github.com/aimagelab/VKD.
Future Urban Scenes Generation Through Vehicles Synthesis
Jul 01, 2020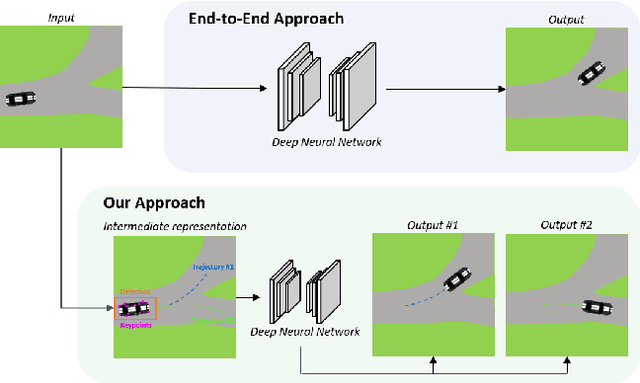
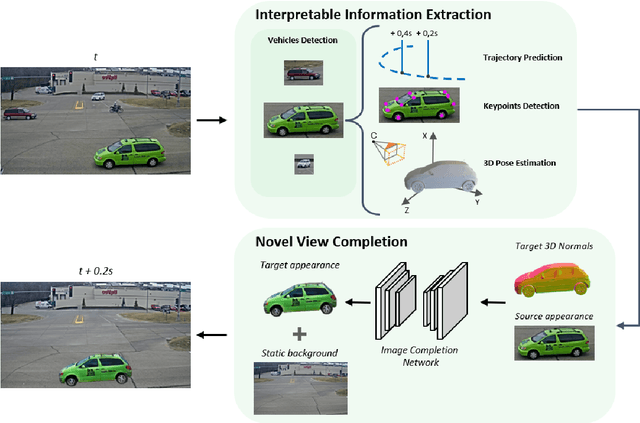

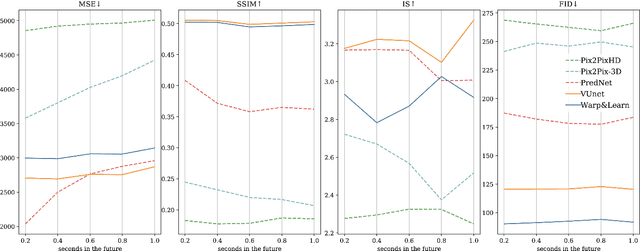
In this work we propose a deep learning pipeline to predict the visual future appearance of an urban scene. Despite recent advances, generating the entire scene in an end-to-end fashion is still far from being achieved. Instead, here we follow a two stages approach, where interpretable information is included in the loop and each actor is modelled independently. We leverage a per-object novel view synthesis paradigm; i.e. generating a synthetic representation of an object undergoing a geometrical roto-translation in the 3D space. Our model can be easily conditioned with constraints (e.g. input trajectories) provided by state-of-the-art tracking methods or by the user itself. This allows us to generate a set of diverse realistic futures starting from the same input in a multi-modal fashion. We visually and quantitatively show the superiority of this approach over traditional end-to-end scene-generation methods on CityFlow, a challenging real world dataset.
One Thousand and One Hours: Self-driving Motion Prediction Dataset
Jun 25, 2020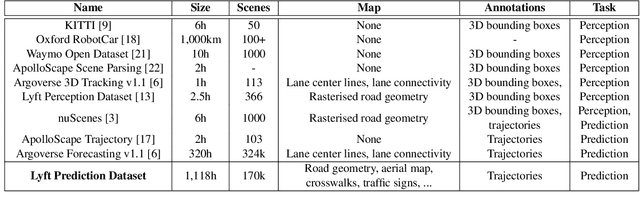

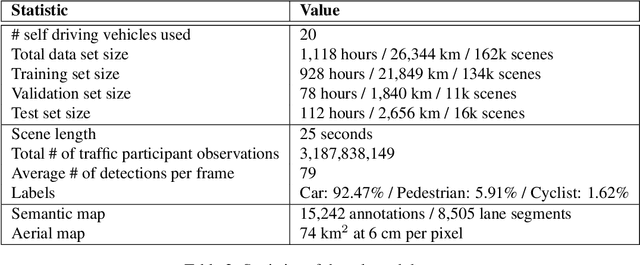
We present the largest self-driving dataset for motion prediction to date, with over 1,000 hours of data. This was collected by a fleet of 20 autonomous vehicles along a fixed route in Palo Alto, California over a four-month period. It consists of 170,000 scenes, where each scene is 25 seconds long and captures the perception output of the self-driving system, which encodes the precise positions and motions of nearby vehicles, cyclists, and pedestrians over time. On top of this, the dataset contains a high-definition semantic map with 15,242 labelled elements and a high-definition aerial view over the area. Together with the provided software kit, this collection forms the largest, most complete and detailed dataset to date for the development of self-driving, machine learning tasks such as motion forecasting, planning and simulation. The full dataset is available at http://level5.lyft.com/.
Semi-parametric Object Synthesis
Jul 24, 2019

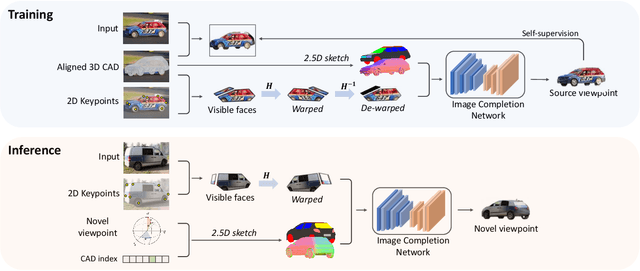
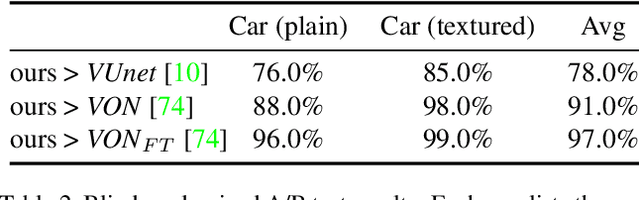
We present a new semi-parametric approach to synthesize novel views of an object from a single monocular image. First, we exploit man-made object symmetry and piece-wise planarity to integrate rich a-priori visual information into the novel viewpoint synthesis process. An Image Completion Network (ICN) then leverages 2.5D sketches rendered from a 3D CAD as guidance to generate a realistic image. In contrast to concurrent works, we do not rely solely on synthetic data but leverage instead existing datasets for 3D object detection to operate in a real-world scenario. Differently from competitors, our semi-parametric framework allows the handling of a wide range of 3D transformations. Thorough experimental analysis against state-of-the-art baselines shows the efficacy of our method both from a quantitative and a perceptive point of view. Code and supplementary material are available at: https://github.com/ndrplz/semiparametric
Multi-views Embedding for Cattle Re-identification
Feb 13, 2019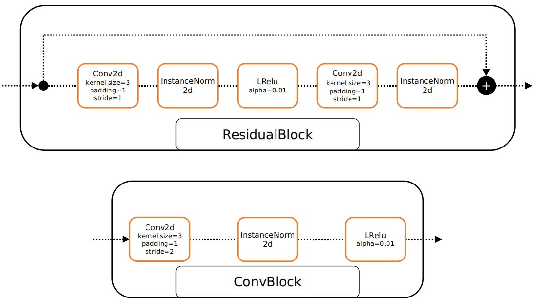
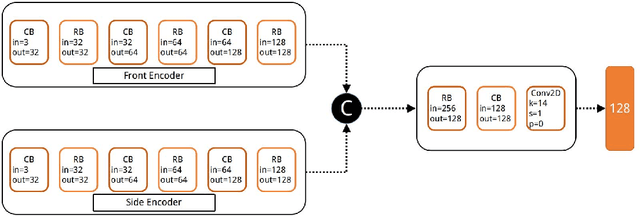

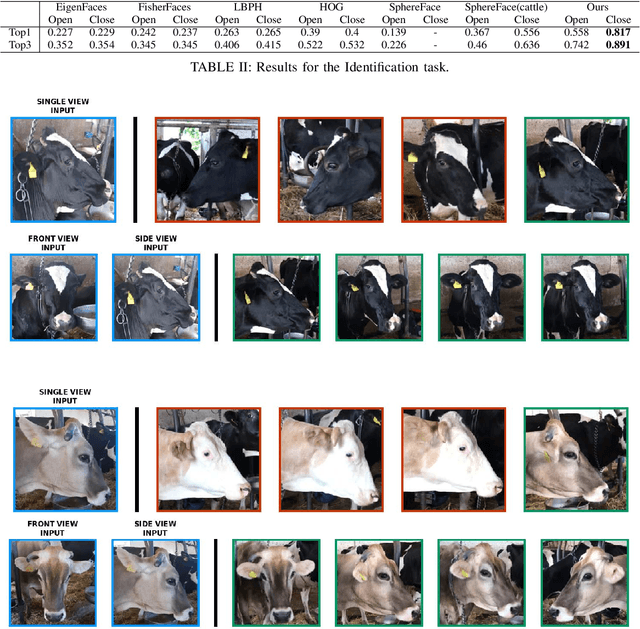
People re-identification task has seen enormous improvements in the latest years, mainly due to the development of better image features extraction from deep Convolutional Neural Networks (CNN) and the availability of large datasets. However, little research has been conducted on animal identification and re-identification, even if this knowledge may be useful in a rich variety of different scenarios. Here, we tackle cattle re-identification exploiting deep CNN and show how this task is poorly related with the human one, presenting unique challenges that makes it far from being solved. We present various baselines, both based on deep architectures or on standard machine learning algorithms, and compared them with our solution. Finally, a rich ablation study has been conducted to further investigate the unique peculiarities of this task.