 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturBench: Benchmarking Machine Learning Models for Cellular Perturbation Analysis
Aug 20, 2024



We present a comprehensive framework for predicting the effects of perturbations in single cells, designed to standardize benchmarking in this rapidly evolving field. Our framework, PerturBench, includes a user-friendly platform, diverse datasets, metrics for fair model comparison, and detailed performance analysis. Extensive evaluations of published and baseline models reveal limitations like mode or posterior collapse, and underscore the importance of rank metrics that assess the ordering of perturbations alongside traditional measures like RMSE. Our findings show that simple models can outperform more complex approaches. This benchmarking exercise sets new standards for model evaluation, supports robust model development, and advances the potential of these models to use high-throughput and high-content genetic and chemical screens for disease target discovery.
Off-Policy Correction For Multi-Agent Reinforcement Learning
Nov 22, 2021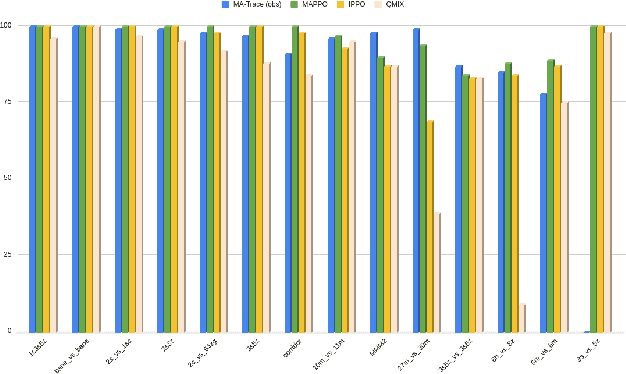
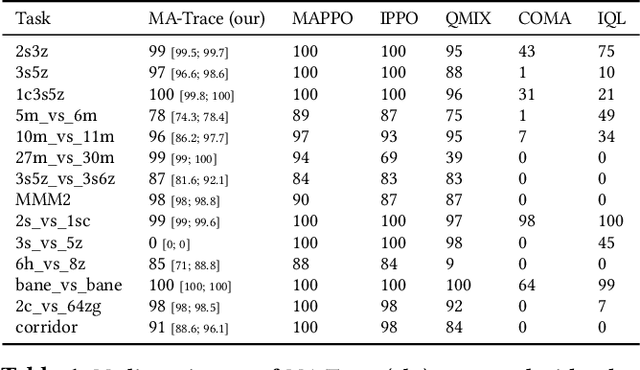
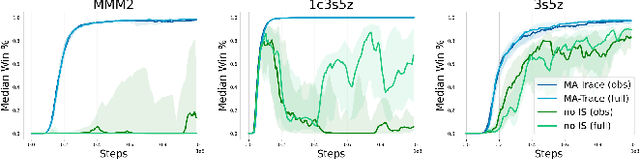

Multi-agent reinforcement learning (MARL) provides a framework for problems involving multiple interacting agents. Despite apparent similarity to the single-agent case, multi-agent problems are often harder to train and analyze theoretically. In this work, we propose MA-Trace, a new on-policy actor-critic algorithm, which extends V-Trace to the MARL setting. The key advantage of our algorithm is its high scalability in a multi-worker setting. To this end, MA-Trace utilizes importance sampling as an off-policy correction method, which allows distributing the computations with no impact on the quality of training. Furthermore, our algorithm is theoretically grounded - we prove a fixed-point theorem that guarantees convergence. We evaluate the algorithm extensively on the StarCraft Multi-Agent Challenge, a standard benchmark for multi-agent algorithms. MA-Trace achieves high performance on all its tasks and exceeds state-of-the-art results on some of them.
SafetyNet: Safe planning for real-world self-driving vehicles using machine-learned policies
Sep 28, 2021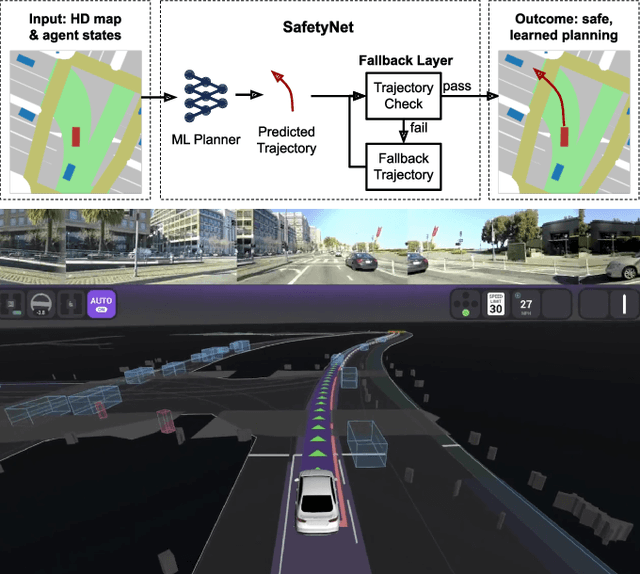
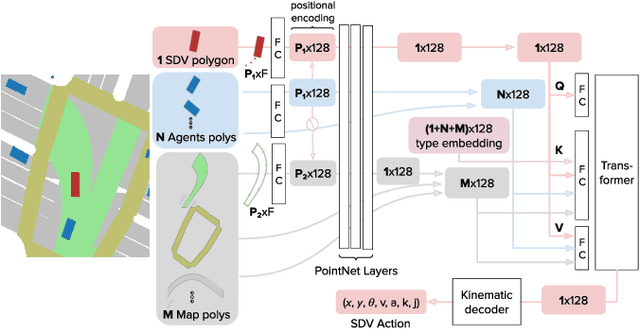
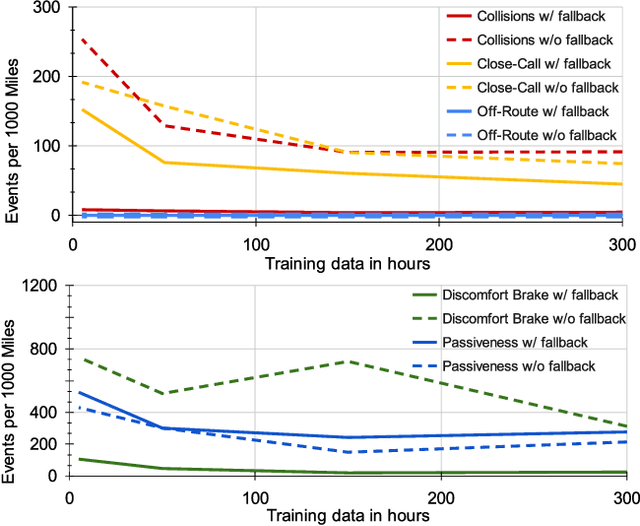
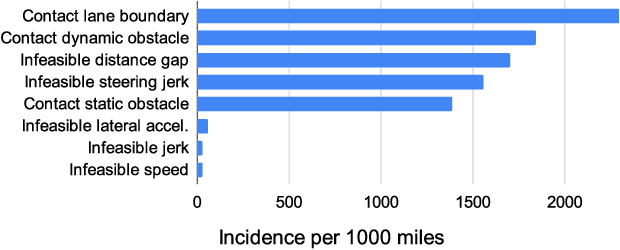
In this paper we present the first safe system for full control of self-driving vehicles trained from human demonstrations and deployed in challenging, real-world, urban environments. Current industry-standard solutions use rule-based systems for planning. Although they perform reasonably well in common scenarios, the engineering complexity renders this approach incompatible with human-level performance. On the other hand, the performance of machine-learned (ML) planning solutions can be improved by simply adding more exemplar data. However, ML methods cannot offer safety guarantees and sometimes behave unpredictably. To combat this, our approach uses a simple yet effective rule-based fallback layer that performs sanity checks on an ML planner's decisions (e.g. avoiding collision, assuring physical feasibility). This allows us to leverage ML to handle complex situations while still assuring the safety, reducing ML planner-only collisions by 95%. We train our ML planner on 300 hours of expert driving demonstrations using imitation learning and deploy it along with the fallback layer in downtown San Francisco, where it takes complete control of a real vehicle and navigates a wide variety of challenging urban driving scenarios.
Urban Driver: Learning to Drive from Real-world Demonstrations Using Policy Gradients
Sep 27, 2021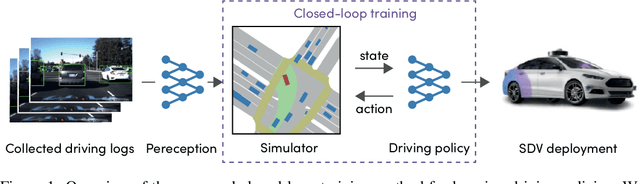

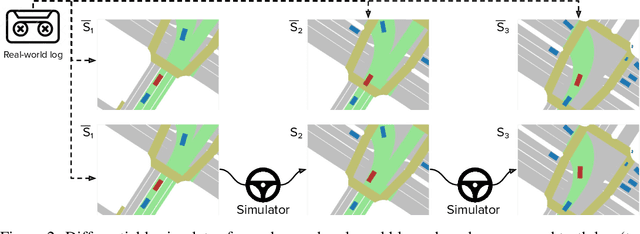
In this work we are the first to present an offline policy gradient method for learning imitative policies for complex urban driving from a large corpus of real-world demonstrations. This is achieved by building a differentiable data-driven simulator on top of perception outputs and high-fidelity HD maps of the area. It allows us to synthesize new driving experiences from existing demonstrations using mid-level representations. Using this simulator we then train a policy network in closed-loop employing policy gradients. We train our proposed method on 100 hours of expert demonstrations on urban roads and show that it learns complex driving policies that generalize well and can perform a variety of driving maneuvers. We demonstrate this in simulation as well as deploy our model to self-driving vehicles in the real-world. Our method outperforms previously demonstrated state-of-the-art for urban driving scenarios -- all this without the need for complex state perturbations or collecting additional on-policy data during training. We make code and data publicly available.
CARLA Real Traffic Scenarios -- novel training ground and benchmark for autonomous driving
Dec 16, 2020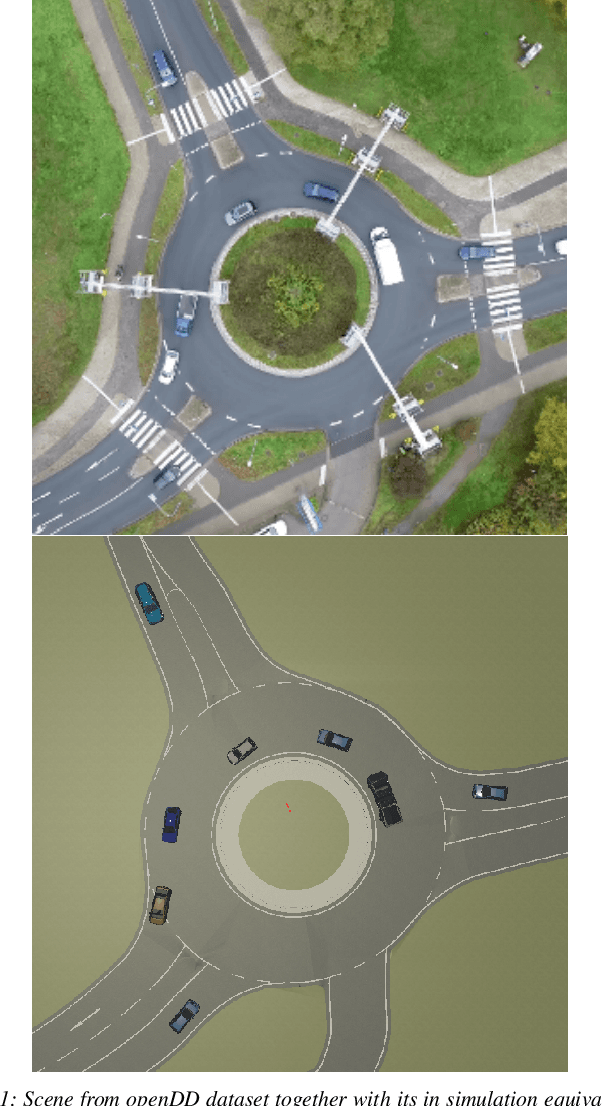

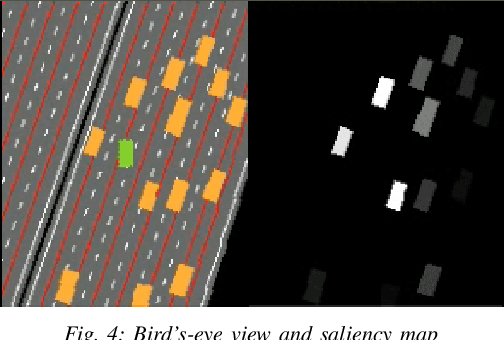
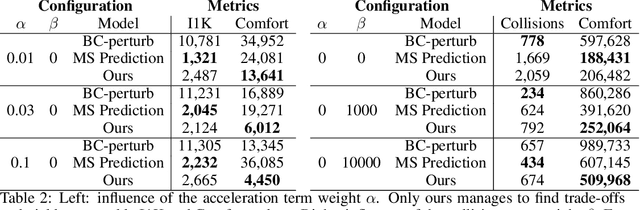
This work introduces interactive traffic scenarios in the CARLA simulator, which are based on real-world traffic. We concentrate on tactical tasks lasting several seconds, which are especially challenging for current control methods. The CARLA Real Traffic Scenarios (CRTS) is intended to be a training and testing ground for autonomous driving systems. To this end, we open-source the code under a permissive license and present a set of baseline policies. CRTS combines the realism of traffic scenarios and the flexibility of simulation. We use it to train agents using a reinforcement learning algorithm. We show how to obtain competitive polices and evaluate experimentally how observation types and reward schemes affect the training process and the resulting agent's behavior.
Simulation-based reinforcement learning for real-world autonomous driving
Dec 26, 2019
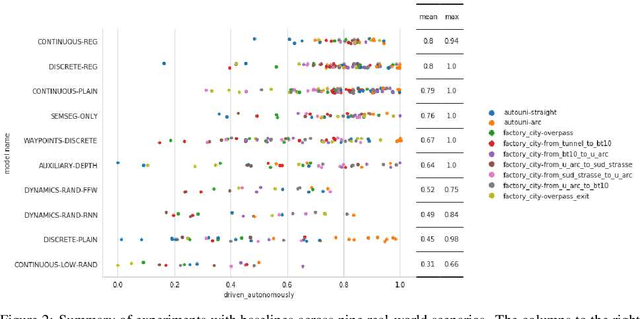
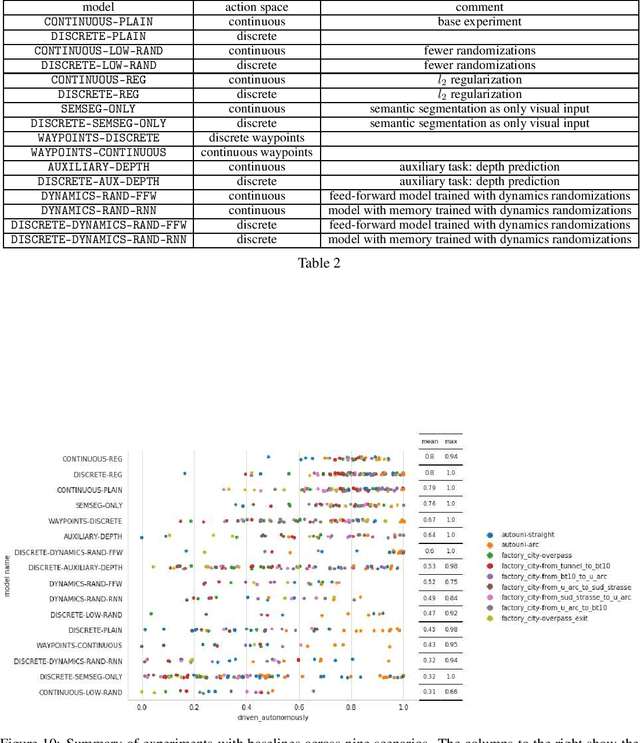
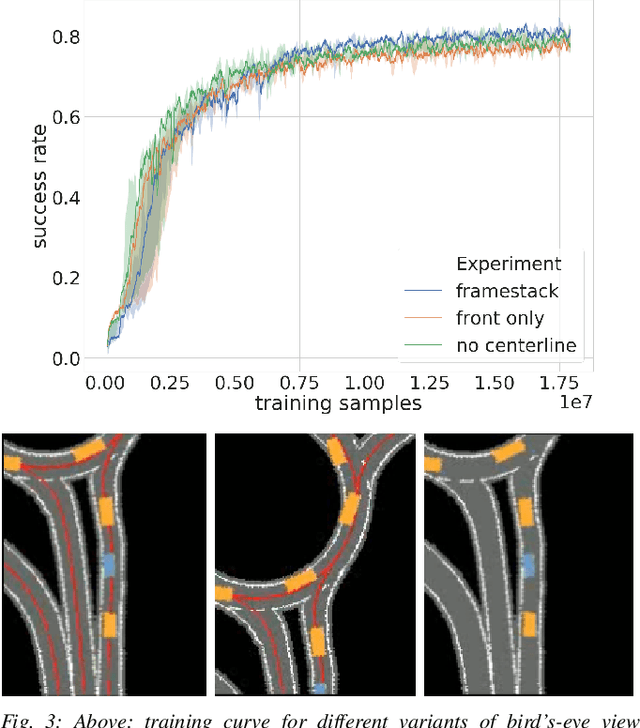
We use synthetic data and a reinforcement learning algorithm to train a system controlling a full-size real-world vehicle in a number of restricted driving scenarios. The driving policy uses RGB images as input. We analyze how design decisions about perception, control and training impact the real-world performance.
Learning to Run challenge solutions: Adapting reinforcement learning methods for neuromusculoskeletal environments
Apr 02, 2018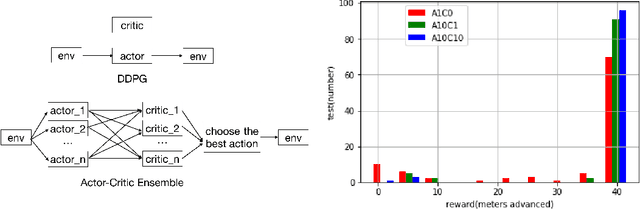

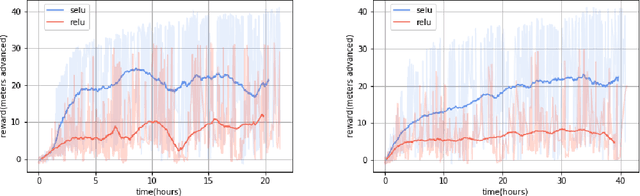
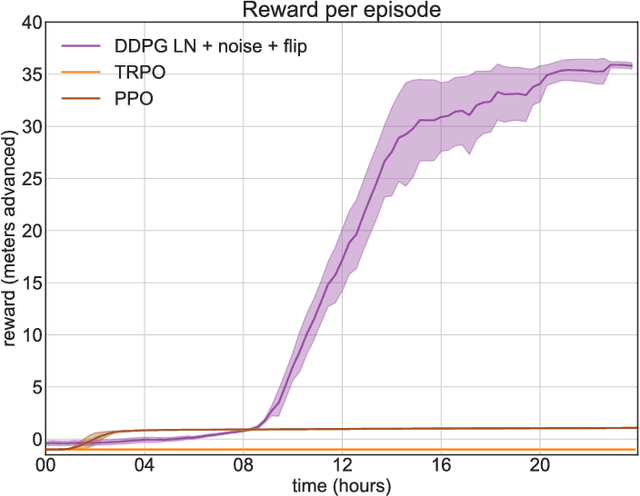
In the NIPS 2017 Learning to Run challenge, participants were tasked with building a controller for a musculoskeletal model to make it run as fast as possible through an obstacle course. Top participants were invited to describe their algorithms. In this work, we present eight solutions that used deep reinforcement learning approaches, based on algorithms such as Deep Deterministic Policy Gradient, Proximal Policy Optimization, and Trust Region Policy Optimization. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each of the eight teams implemented different modifications of the known algorithms.