 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Primitives for Generalized Sensor Fusion in Autonomous Vehicles
Dec 01, 2021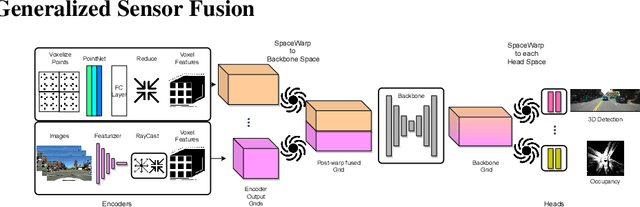
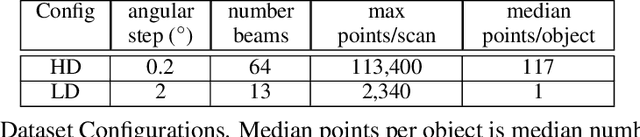
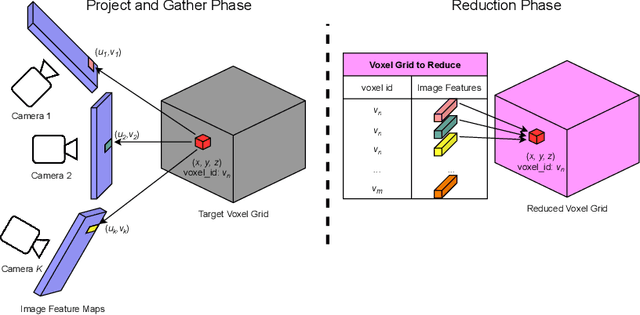

In autonomous driving, there has been an explosion in the use of deep neural networks for perception, prediction and planning tasks. As autonomous vehicles (AVs) move closer to production, multi-modal sensor inputs and heterogeneous vehicle fleets with different sets of sensor platforms are becoming increasingly common in the industry. However, neural network architectures typically target specific sensor platforms and are not robust to changes in input, making the problem of scaling and model deployment particularly difficult. Furthermore, most players still treat the problem of optimizing software and hardware as entirely independent problems. We propose a new end to end architecture, Generalized Sensor Fusion (GSF), which is designed in such a way that both sensor inputs and target tasks are modular and modifiable. This enables AV system designers to easily experiment with different sensor configurations and methods and opens up the ability to deploy on heterogeneous fleets using the same models that are shared across a large engineering organization. Using this system, we report experimental results where we demonstrate near-parity of an expensive high-density (HD) LiDAR sensor with a cheap low-density (LD) LiDAR plus camera setup in the 3D object detection task. This paves the way for the industry to jointly design hardware and software architectures as well as large fleets with heterogeneous configurations.
SafetyNet: Safe planning for real-world self-driving vehicles using machine-learned policies
Sep 28, 2021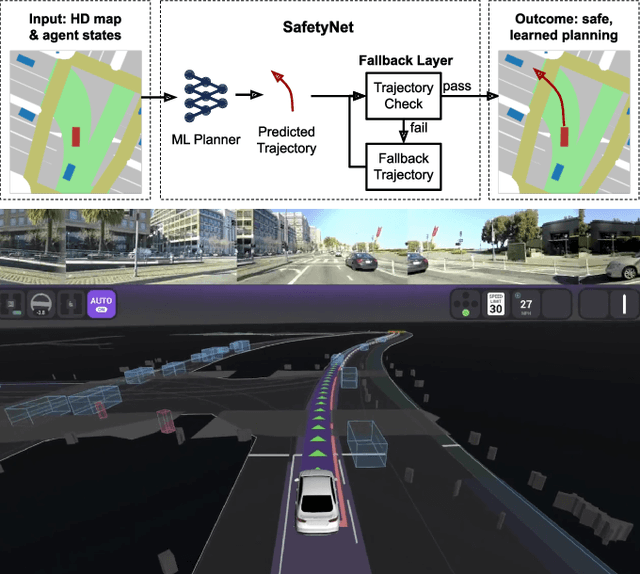
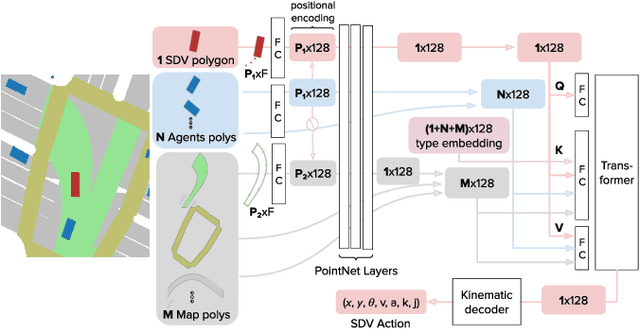
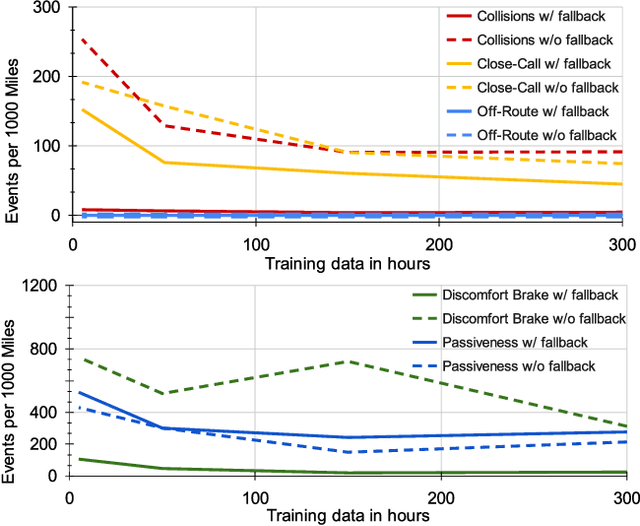
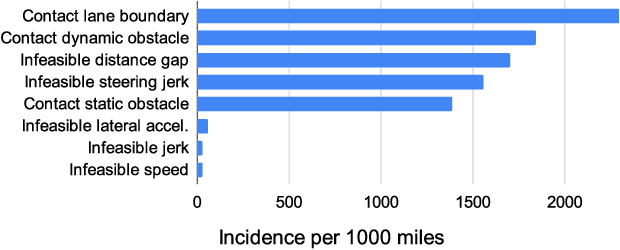
In this paper we present the first safe system for full control of self-driving vehicles trained from human demonstrations and deployed in challenging, real-world, urban environments. Current industry-standard solutions use rule-based systems for planning. Although they perform reasonably well in common scenarios, the engineering complexity renders this approach incompatible with human-level performance. On the other hand, the performance of machine-learned (ML) planning solutions can be improved by simply adding more exemplar data. However, ML methods cannot offer safety guarantees and sometimes behave unpredictably. To combat this, our approach uses a simple yet effective rule-based fallback layer that performs sanity checks on an ML planner's decisions (e.g. avoiding collision, assuring physical feasibility). This allows us to leverage ML to handle complex situations while still assuring the safety, reducing ML planner-only collisions by 95%. We train our ML planner on 300 hours of expert driving demonstrations using imitation learning and deploy it along with the fallback layer in downtown San Francisco, where it takes complete control of a real vehicle and navigates a wide variety of challenging urban driving scenarios.
Recurrent Slice Networks for 3D Segmentation of Point Clouds
Mar 29, 2018

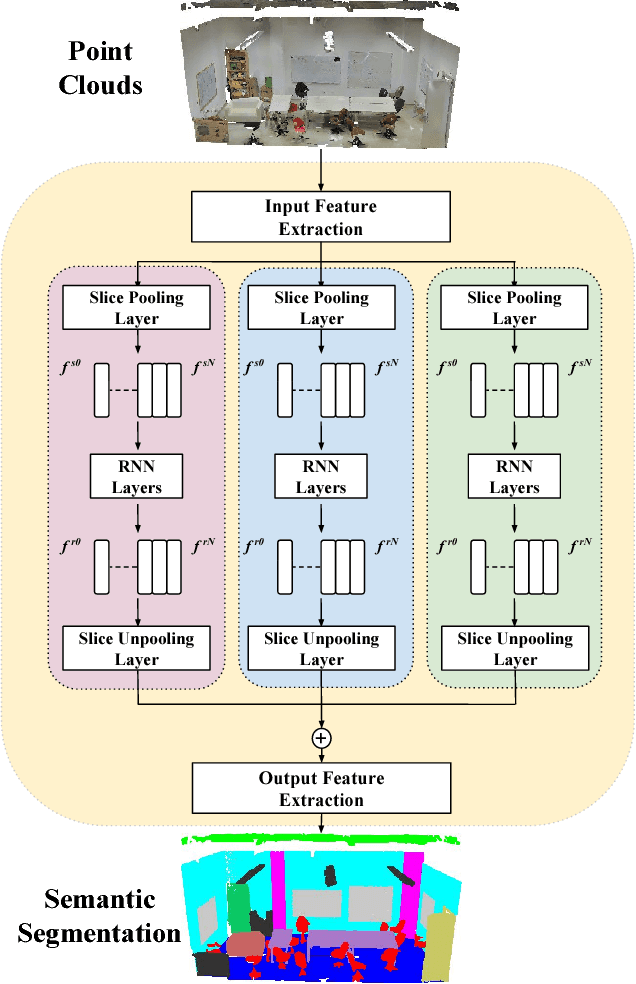
Point clouds are an efficient data format for 3D data. However, existing 3D segmentation methods for point clouds either do not model local dependencies \cite{pointnet} or require added computations \cite{kd-net,pointnet2}. This work presents a novel 3D segmentation framework, RSNet\footnote{Codes are released here https://github.com/qianguih/RSNet}, to efficiently model local structures in point clouds. The key component of the RSNet is a lightweight local dependency module. It is a combination of a novel slice pooling layer, Recurrent Neural Network (RNN) layers, and a slice unpooling layer. The slice pooling layer is designed to project features of unordered points onto an ordered sequence of feature vectors so that traditional end-to-end learning algorithms (RNNs) can be applied. The performance of RSNet is validated by comprehensive experiments on the S3DIS\cite{stanford}, ScanNet\cite{scannet}, and ShapeNet \cite{shapenet} datasets. In its simplest form, RSNets surpass all previous state-of-the-art methods on these benchmarks. And comparisons against previous state-of-the-art methods \cite{pointnet, pointnet2} demonstrate the efficiency of RSNets.
Learning to Prune Filters in Convolutional Neural Networks
Jan 23, 2018
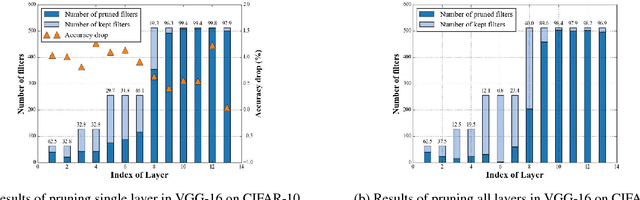

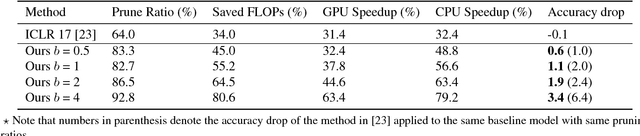
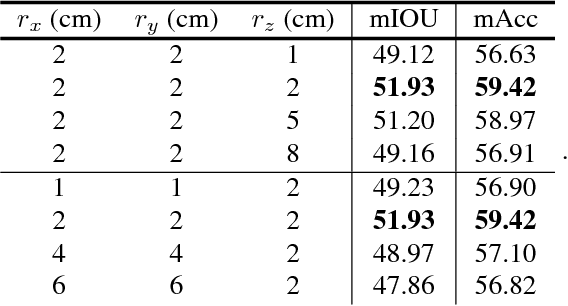
Many state-of-the-art computer vision algorithms use large scale convolutional neural networks (CNNs) as basic building blocks. These CNNs are known for their huge number of parameters, high redundancy in weights, and tremendous computing resource consumptions. This paper presents a learning algorithm to simplify and speed up these CNNs. Specifically, we introduce a "try-and-learn" algorithm to train pruning agents that remove unnecessary CNN filters in a data-driven way. With the help of a novel reward function, our agents removes a significant number of filters in CNNs while maintaining performance at a desired level. Moreover, this method provides an easy control of the tradeoff between network performance and its scale. Per- formance of our algorithm is validated with comprehensive pruning experiments on several popular CNNs for visual recognition and semantic segmentation tasks.
SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation
Nov 23, 2017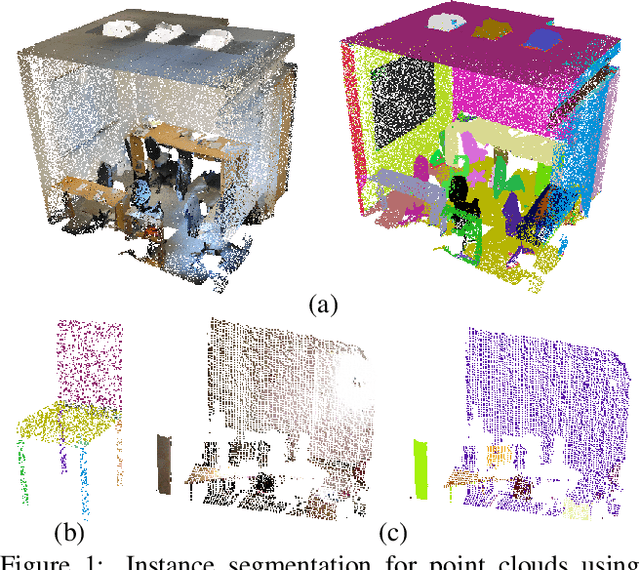

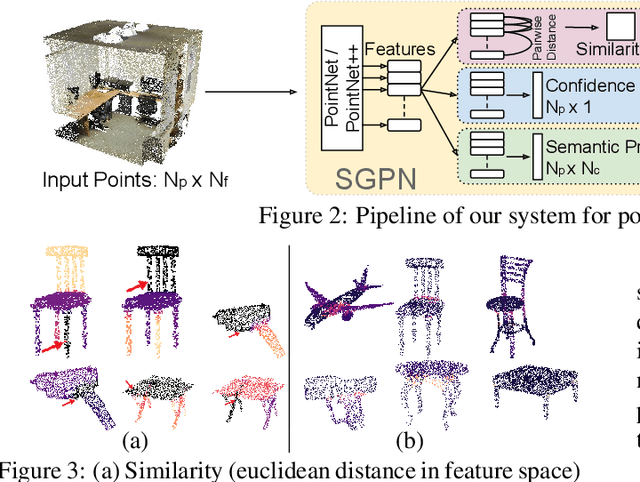

We introduce Similarity Group Proposal Network (SGPN), a simple and intuitive deep learning framework for 3D object instance segmentation on point clouds. SGPN uses a single network to predict point grouping proposals and a corresponding semantic class for each proposal, from which we can directly extract instance segmentation results. Important to the effectiveness of SGPN is its novel representation of 3D instance segmentation results in the form of a similarity matrix that indicates the similarity between each pair of points in embedded feature space, thus producing an accurate grouping proposal for each point. To the best of our knowledge, SGPN is the first framework to learn 3D instance-aware semantic segmentation on point clouds. Experimental results on various 3D scenes show the effectiveness of our method on 3D instance segmentation, and we also evaluate the capability of SGPN to improve 3D object detection and semantic segmentation results. We also demonstrate its flexibility by seamlessly incorporating 2D CNN features into the framework to boost performance.
Shape Inpainting using 3D Generative Adversarial Network and Recurrent Convolutional Networks
Nov 17, 2017

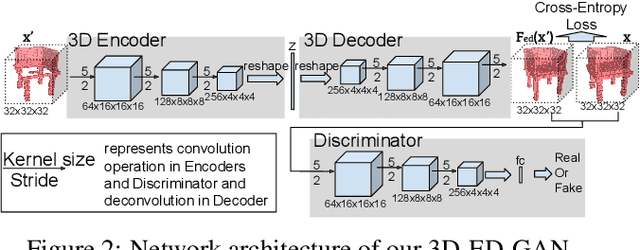
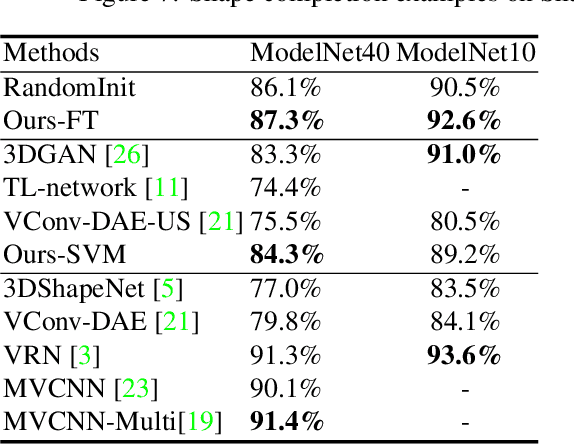
Recent advances in convolutional neural networks have shown promising results in 3D shape completion. But due to GPU memory limitations, these methods can only produce low-resolution outputs. To inpaint 3D models with semantic plausibility and contextual details, we introduce a hybrid framework that combines a 3D Encoder-Decoder Generative Adversarial Network (3D-ED-GAN) and a Long-term Recurrent Convolutional Network (LRCN). The 3D-ED-GAN is a 3D convolutional neural network trained with a generative adversarial paradigm to fill missing 3D data in low-resolution. LRCN adopts a recurrent neural network architecture to minimize GPU memory usage and incorporates an Encoder-Decoder pair into a Long Short-term Memory Network. By handling the 3D model as a sequence of 2D slices, LRCN transforms a coarse 3D shape into a more complete and higher resolution volume. While 3D-ED-GAN captures global contextual structure of the 3D shape, LRCN localizes the fine-grained details. Experimental results on both real-world and synthetic data show reconstructions from corrupted models result in complete and high-resolution 3D objects.
Automatic Vertebra Labeling in Large-Scale 3D CT using Deep Image-to-Image Network with Message Passing and Sparsity Regularization
May 17, 2017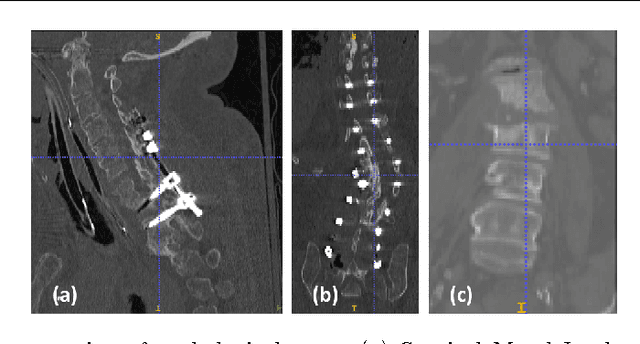
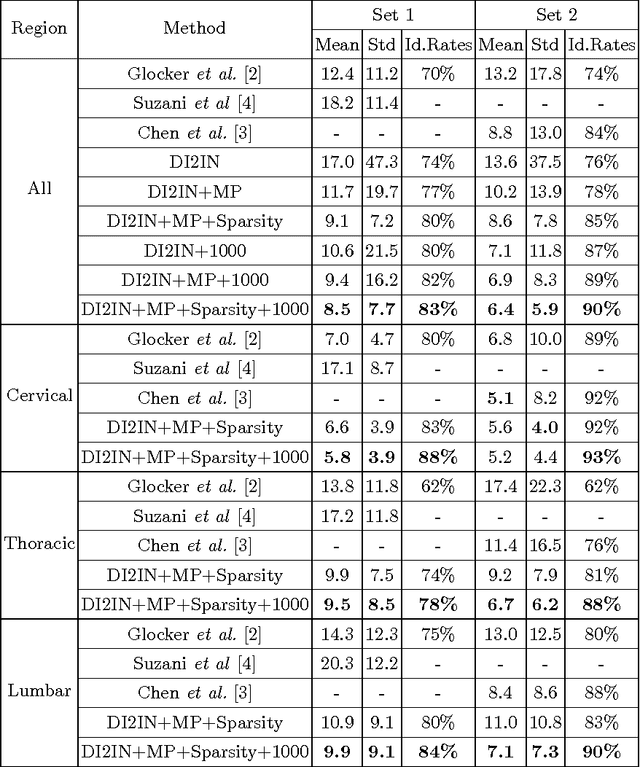

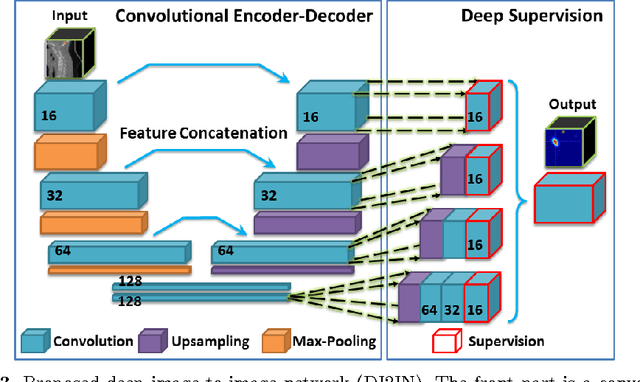
Automatic localization and labeling of vertebra in 3D medical images plays an important role in many clinical tasks, including pathological diagnosis, surgical planning and postoperative assessment. However, the unusual conditions of pathological cases, such as the abnormal spine curvature, bright visual imaging artifacts caused by metal implants, and the limited field of view, increase the difficulties of accurate localization. In this paper, we propose an automatic and fast algorithm to localize and label the vertebra centroids in 3D CT volumes. First, we deploy a deep image-to-image network (DI2IN) to initialize vertebra locations, employing the convolutional encoder-decoder architecture together with multi-level feature concatenation and deep supervision. Next, the centroid probability maps from DI2IN are iteratively evolved with the message passing schemes based on the mutual relation of vertebra centroids. Finally, the localization results are refined with sparsity regularization. The proposed method is evaluated on a public dataset of 302 spine CT volumes with various pathologies. Our method outperforms other state-of-the-art methods in terms of localization accuracy. The run time is around 3 seconds on average per case. To further boost the performance, we retrain the DI2IN on additional 1000+ 3D CT volumes from different patients. To the best of our knowledge, this is the first time more than 1000 3D CT volumes with expert annotation are adopted in experiments for the anatomic landmark detection tasks. Our experimental results show that training with such a large dataset significantly improves the performance and the overall identification rate, for the first time by our knowledge, reaches 90 %.
Scene Labeling using Gated Recurrent Units with Explicit Long Range Conditioning
Mar 28, 2017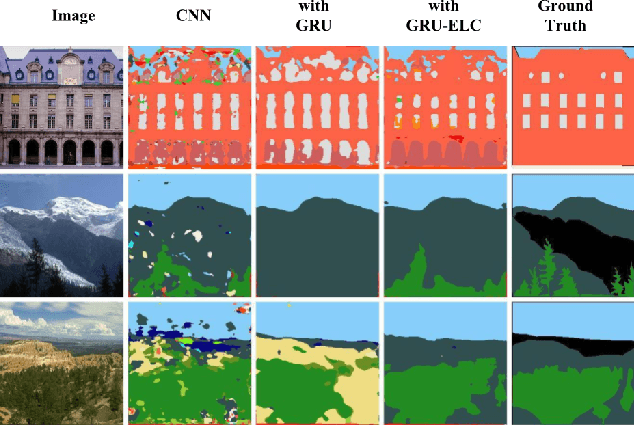
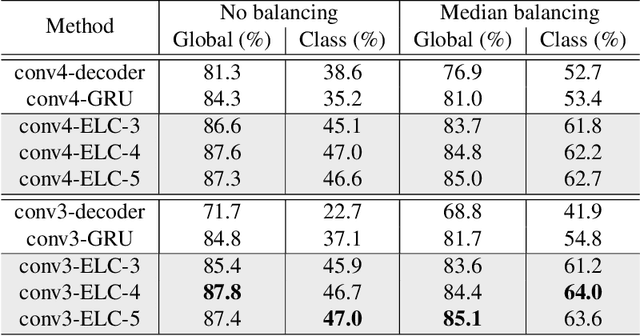
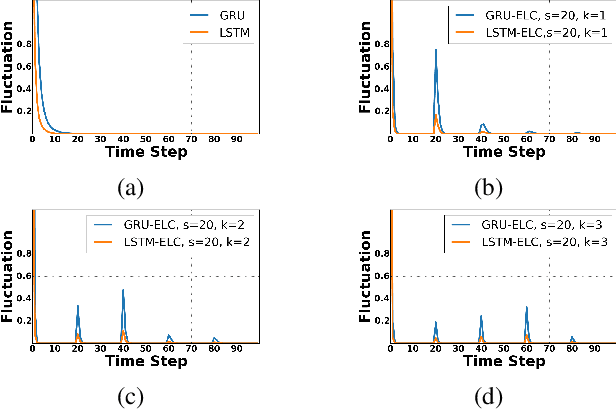
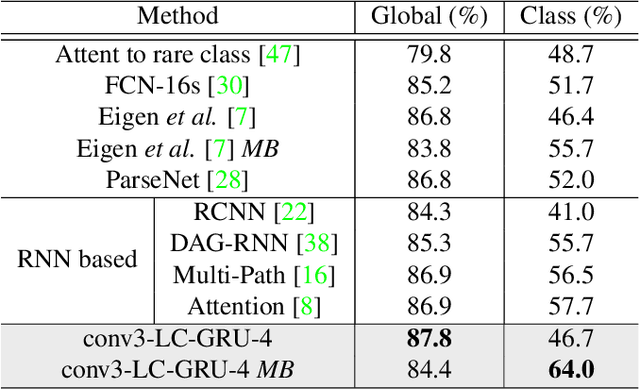
Recurrent neural network (RNN), as a powerful contextual dependency modeling framework, has been widely applied to scene labeling problems. However, this work shows that directly applying traditional RNN architectures, which unfolds a 2D lattice grid into a sequence, is not sufficient to model structure dependencies in images due to the "impact vanishing" problem. First, we give an empirical analysis about the "impact vanishing" problem. Then, a new RNN unit named Recurrent Neural Network with explicit long range conditioning (RNN-ELC) is designed to alleviate this problem. A novel neural network architecture is built for scene labeling tasks where one of the variants of the new RNN unit, Gated Recurrent Unit with Explicit Long-range Conditioning (GRU-ELC), is used to model multi scale contextual dependencies in images. We validate the use of GRU-ELC units with state-of-the-art performance on three standard scene labeling datasets. Comprehensive experiments demonstrate that the new GRU-ELC unit benefits scene labeling problem a lot as it can encode longer contextual dependencies in images more effectively than traditional RNN units.