 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
Apr 07, 2023



Widely adopted motion forecasting datasets substitute the observed sensory inputs with higher-level abstractions such as 3D boxes and polylines. These sparse shapes are inferred through annotating the original scenes with perception systems' predictions. Such intermediate representations tie the quality of the motion forecasting models to the performance of computer vision models. Moreover, the human-designed explicit interfaces between perception and motion forecasting typically pass only a subset of the semantic information present in the original sensory input. To study the effect of these modular approaches, design new paradigms that mitigate these limitations, and accelerate the development of end-to-end motion forecasting models, we augment the Waymo Open Motion Dataset (WOMD) with large-scale, high-quality, diverse LiDAR data for the motion forecasting task. The new augmented dataset WOMD-LiDAR consists of over 100,000 scenes that each spans 20 seconds, consisting of well-synchronized and calibrated high quality LiDAR point clouds captured across a range of urban and suburban geographies (https://waymo.com/open/data/motion/). Compared to Waymo Open Dataset (WOD), WOMD-LiDAR dataset contains 100x more scenes. Furthermore, we integrate the LiDAR data into the motion forecasting model training and provide a strong baseline. Experiments show that the LiDAR data brings improvement in the motion forecasting task. We hope that WOMD-LiDAR will provide new opportunities for boosting end-to-end motion forecasting models.
Development of Hybrid ASR Systems for Low Resource Medical Domain Conversational Telephone Speech
Oct 26, 2022



Language barriers present a great challenge in our increasingly connected and global world. Especially within the medical domain, e.g. hospital or emergency room, communication difficulties and delays may lead to malpractice and non-optimal patient care. In the HYKIST project, we consider patient-physician communication, more specifically between a German-speaking physician and an Arabic- or Vietnamese-speaking patient. Currently, a doctor can call the Triaphon service to get assistance from an interpreter in order to help facilitate communication. The HYKIST goal is to support the usually non-professional bilingual interpreter with an automatic speech translation system to improve patient care and help overcome language barriers. In this work, we present our ASR system development efforts for this conversational telephone speech translation task in the medical domain for two languages pairs, data collection, various acoustic model architectures and dialect-induced difficulties.
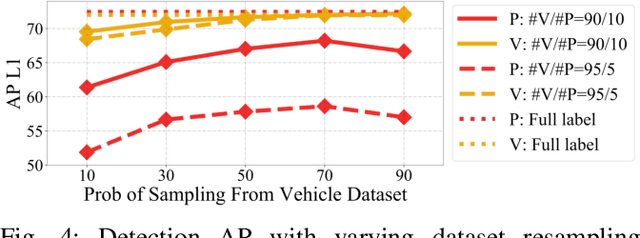
PseudoAugment: Learning to Use Unlabeled Data for Data Augmentation in Point Clouds
Oct 24, 2022Data augmentation is an important technique to improve data efficiency and save labeling cost for 3D detection in point clouds. Yet, existing augmentation policies have so far been designed to only utilize labeled data, which limits the data diversity. In this paper, we recognize that pseudo labeling and data augmentation are complementary, thus propose to leverage unlabeled data for data augmentation to enrich the training data. In particular, we design three novel pseudo-label based data augmentation policies (PseudoAugments) to fuse both labeled and pseudo-labeled scenes, including frames (PseudoFrame), objecta (PseudoBBox), and background (PseudoBackground). PseudoAugments outperforms pseudo labeling by mitigating pseudo labeling errors and generating diverse fused training scenes. We demonstrate PseudoAugments generalize across point-based and voxel-based architectures, different model capacity and both KITTI and Waymo Open Dataset. To alleviate the cost of hyperparameter tuning and iterative pseudo labeling, we develop a population-based data augmentation framework for 3D detection, named AutoPseudoAugment. Unlike previous works that perform pseudo-labeling offline, our framework performs PseudoAugments and hyperparameter tuning in one shot to reduce computational cost. Experimental results on the large-scale Waymo Open Dataset show our method outperforms state-of-the-art auto data augmentation method (PPBA) and self-training method (pseudo labeling). In particular, AutoPseudoAugment is about 3X and 2X data efficient on vehicle and pedestrian tasks compared to prior arts. Notably, AutoPseudoAugment nearly matches the full dataset training results, with just 10% of the labeled run segments on the vehicle detection task.
SWFormer: Sparse Window Transformer for 3D Object Detection in Point Clouds
Oct 13, 2022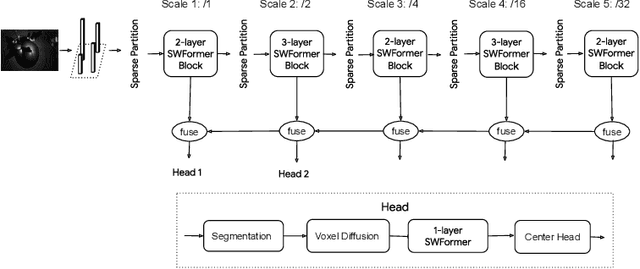
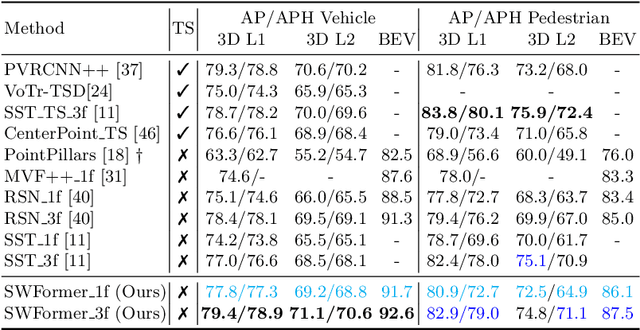
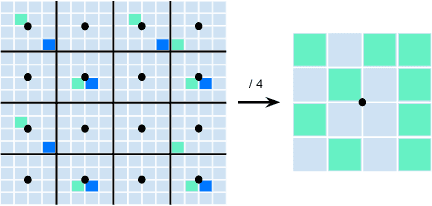

3D object detection in point clouds is a core component for modern robotics and autonomous driving systems. A key challenge in 3D object detection comes from the inherent sparse nature of point occupancy within the 3D scene. In this paper, we propose Sparse Window Transformer (SWFormer ), a scalable and accurate model for 3D object detection, which can take full advantage of the sparsity of point clouds. Built upon the idea of window-based Transformers, SWFormer converts 3D points into sparse voxels and windows, and then processes these variable-length sparse windows efficiently using a bucketing scheme. In addition to self-attention within each spatial window, our SWFormer also captures cross-window correlation with multi-scale feature fusion and window shifting operations. To further address the unique challenge of detecting 3D objects accurately from sparse features, we propose a new voxel diffusion technique. Experimental results on the Waymo Open Dataset show our SWFormer achieves state-of-the-art 73.36 L2 mAPH on vehicle and pedestrian for 3D object detection on the official test set, outperforming all previous single-stage and two-stage models, while being much more efficient.
Multi-Class 3D Object Detection with Single-Class Supervision
May 11, 2022


While multi-class 3D detectors are needed in many robotics applications, training them with fully labeled datasets can be expensive in labeling cost. An alternative approach is to have targeted single-class labels on disjoint data samples. In this paper, we are interested in training a multi-class 3D object detection model, while using these single-class labeled data. We begin by detailing the unique stance of our "Single-Class Supervision" (SCS) setting with respect to related concepts such as partial supervision and semi supervision. Then, based on the case study of training the multi-class version of Range Sparse Net (RSN), we adapt a spectrum of algorithms -- from supervised learning to pseudo-labeling -- to fully exploit the properties of our SCS setting, and perform extensive ablation studies to identify the most effective algorithm and practice. Empirical experiments on the Waymo Open Dataset show that proper training under SCS can approach or match full supervision training while saving labeling costs.
Investigation on Data Adaptation Techniques for Neural Named Entity Recognition
Oct 12, 2021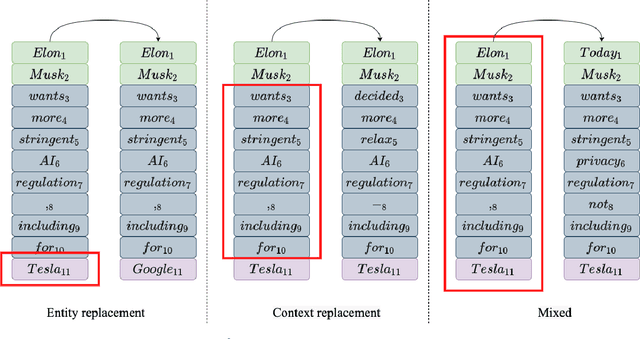
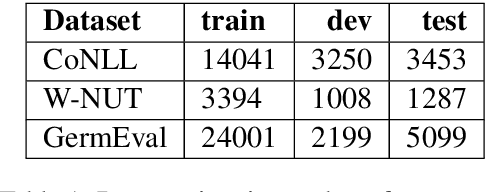
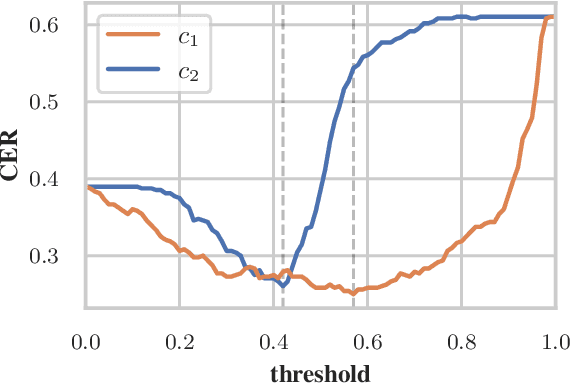
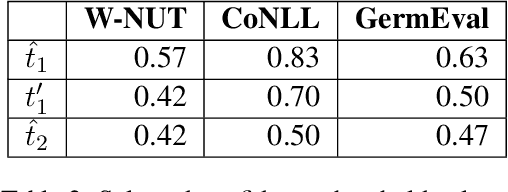
Data processing is an important step in various natural language processing tasks. As the commonly used datasets in named entity recognition contain only a limited number of samples, it is important to obtain additional labeled data in an efficient and reliable manner. A common practice is to utilize large monolingual unlabeled corpora. Another popular technique is to create synthetic data from the original labeled data (data augmentation). In this work, we investigate the impact of these two methods on the performance of three different named entity recognition tasks.
Towards Reinforcement Learning for Pivot-based Neural Machine Translation with Non-autoregressive Transformer
Sep 27, 2021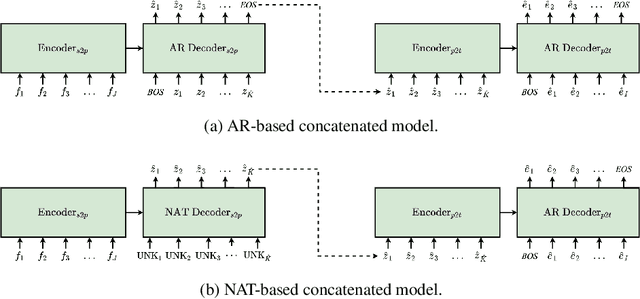
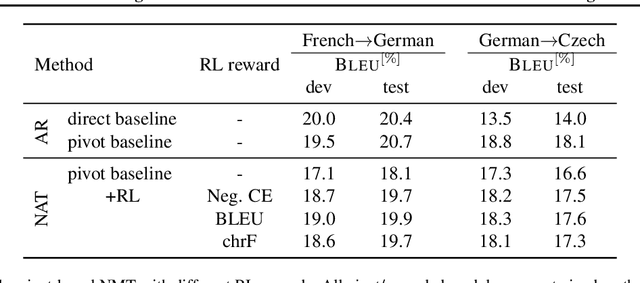
Pivot-based neural machine translation (NMT) is commonly used in low-resource setups, especially for translation between non-English language pairs. It benefits from using high resource source-pivot and pivot-target language pairs and an individual system is trained for both sub-tasks. However, these models have no connection during training, and the source-pivot model is not optimized to produce the best translation for the source-target task. In this work, we propose to train a pivot-based NMT system with the reinforcement learning (RL) approach, which has been investigated for various text generation tasks, including machine translation (MT). We utilize a non-autoregressive transformer and present an end-to-end pivot-based integrated model, enabling training on source-target data.
Integrated Training for Sequence-to-Sequence Models Using Non-Autoregressive Transformer
Sep 27, 2021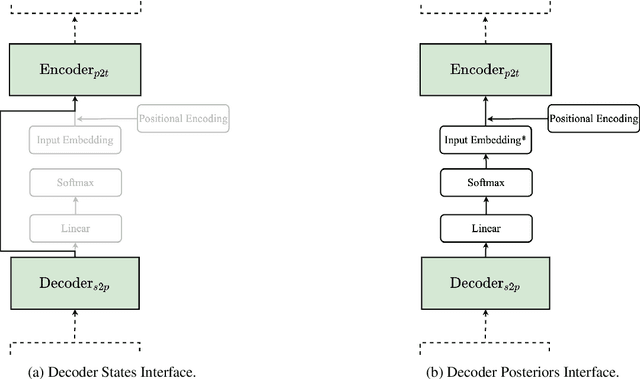
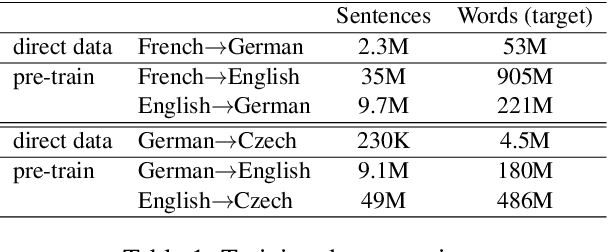
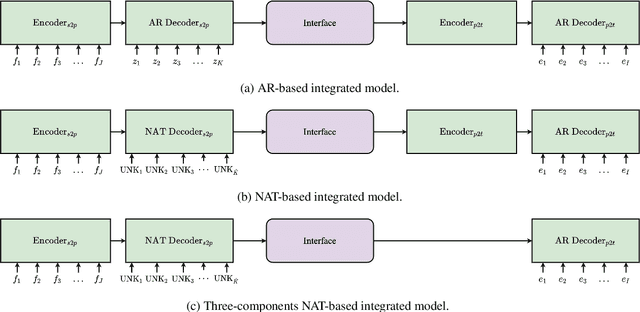
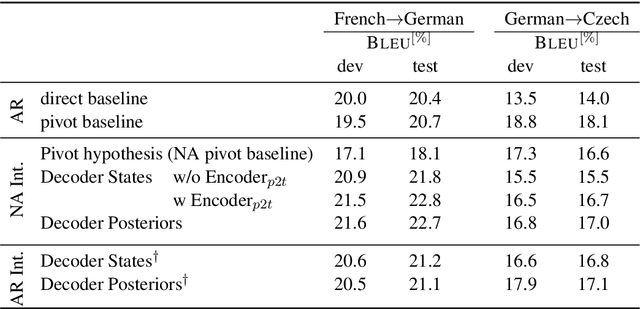
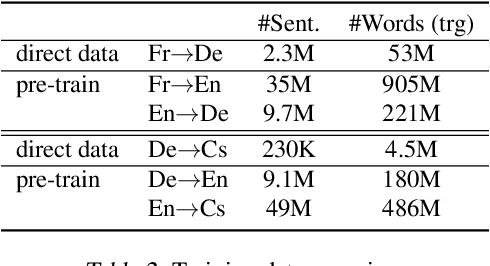
Complex natural language applications such as speech translation or pivot translation traditionally rely on cascaded models. However, cascaded models are known to be prone to error propagation and model discrepancy problems. Furthermore, there is no possibility of using end-to-end training data in conventional cascaded systems, meaning that the training data most suited for the task cannot be used. Previous studies suggested several approaches for integrated end-to-end training to overcome those problems, however they mostly rely on (synthetic or natural) three-way data. We propose a cascaded model based on the non-autoregressive Transformer that enables end-to-end training without the need for an explicit intermediate representation. This new architecture (i) avoids unnecessary early decisions that can cause errors which are then propagated throughout the cascaded models and (ii) utilizes the end-to-end training data directly. We conduct an evaluation on two pivot-based machine translation tasks, namely French-German and German-Czech. Our experimental results show that the proposed architecture yields an improvement of more than 2 BLEU for French-German over the cascaded baseline.
SPG: Unsupervised Domain Adaptation for 3D Object Detection via Semantic Point Generation
Aug 15, 2021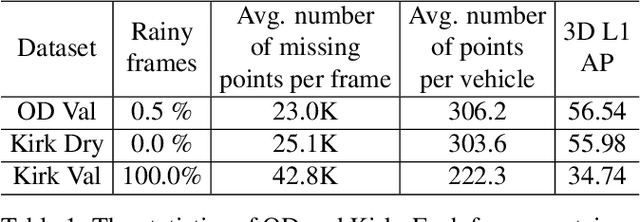

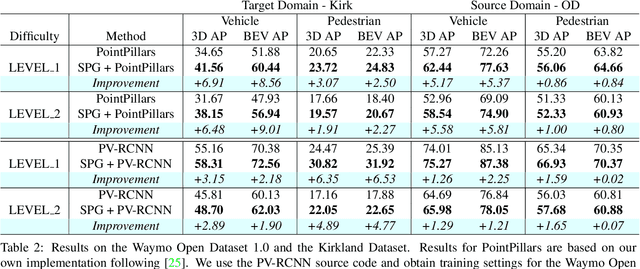
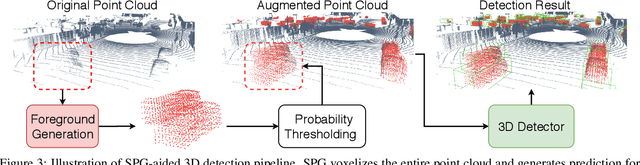
In autonomous driving, a LiDAR-based object detector should perform reliably at different geographic locations and under various weather conditions. While recent 3D detection research focuses on improving performance within a single domain, our study reveals that the performance of modern detectors can drop drastically cross-domain. In this paper, we investigate unsupervised domain adaptation (UDA) for LiDAR-based 3D object detection. On the Waymo Domain Adaptation dataset, we identify the deteriorating point cloud quality as the root cause of the performance drop. To address this issue, we present Semantic Point Generation (SPG), a general approach to enhance the reliability of LiDAR detectors against domain shifts. Specifically, SPG generates semantic points at the predicted foreground regions and faithfully recovers missing parts of the foreground objects, which are caused by phenomena such as occlusions, low reflectance or weather interference. By merging the semantic points with the original points, we obtain an augmented point cloud, which can be directly consumed by modern LiDAR-based detectors. To validate the wide applicability of SPG, we experiment with two representative detectors, PointPillars and PV-RCNN. On the UDA task, SPG significantly improves both detectors across all object categories of interest and at all difficulty levels. SPG can also benefit object detection in the original domain. On the Waymo Open Dataset and KITTI, SPG improves 3D detection results of these two methods across all categories. Combined with PV-RCNN, SPG achieves state-of-the-art 3D detection results on KITTI.
To the Point: Efficient 3D Object Detection in the Range Image with Graph Convolution Kernels
Jun 25, 2021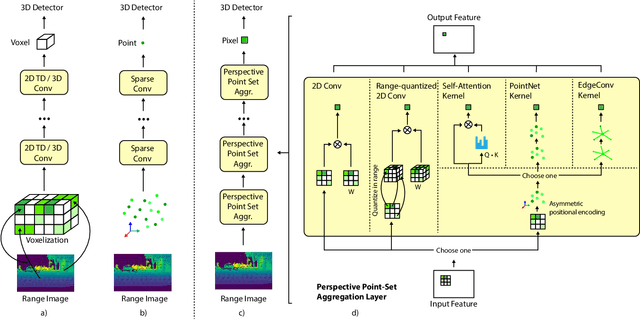
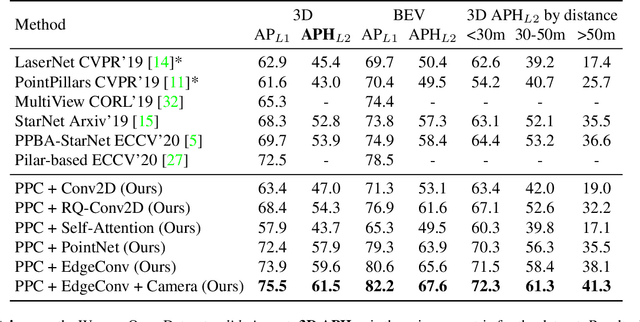
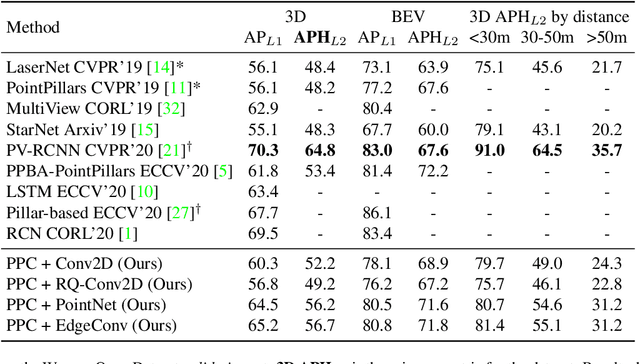
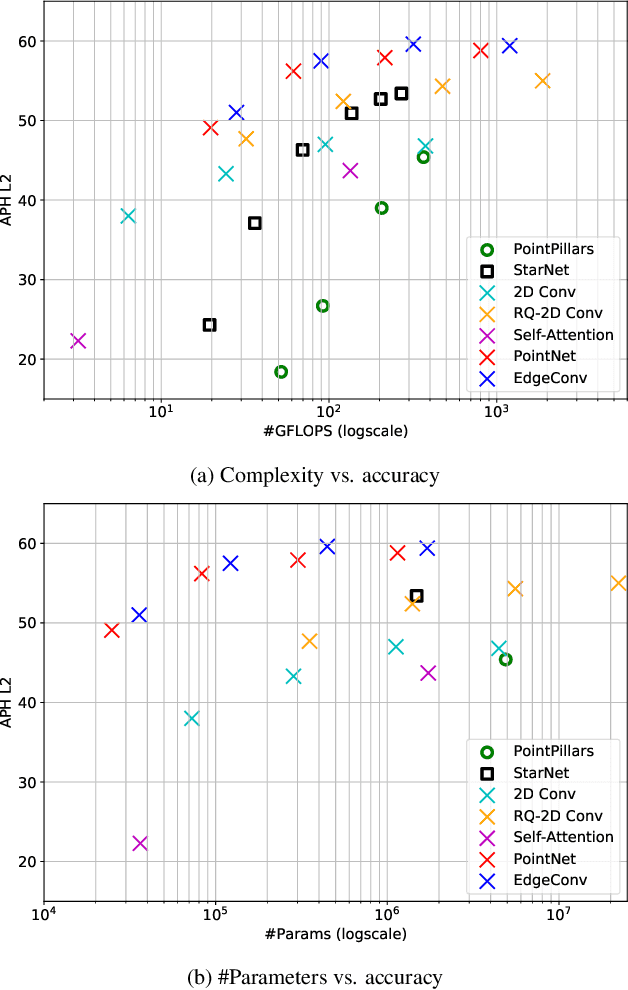
3D object detection is vital for many robotics applications. For tasks where a 2D perspective range image exists, we propose to learn a 3D representation directly from this range image view. To this end, we designed a 2D convolutional network architecture that carries the 3D spherical coordinates of each pixel throughout the network. Its layers can consume any arbitrary convolution kernel in place of the default inner product kernel and exploit the underlying local geometry around each pixel. We outline four such kernels: a dense kernel according to the bag-of-words paradigm, and three graph kernels inspired by recent graph neural network advances: the Transformer, the PointNet, and the Edge Convolution. We also explore cross-modality fusion with the camera image, facilitated by operating in the perspective range image view. Our method performs competitively on the Waymo Open Dataset and improves the state-of-the-art AP for pedestrian detection from 69.7% to 75.5%. It is also efficient in that our smallest model, which still outperforms the popular PointPillars in quality, requires 180 times fewer FLOPS and model parameters