 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Very Long Video Understanding
Jan 26, 2026The advent of always-on personal AI assistants, enabled by all-day wearable devices such as smart glasses, demands a new level of contextual understanding, one that goes beyond short, isolated events to encompass the continuous, longitudinal stream of egocentric video. Achieving this vision requires advances in long-horizon video understanding, where systems must interpret and recall visual and audio information spanning days or even weeks. Existing methods, including large language models and retrieval-augmented generation, are constrained by limited context windows and lack the ability to perform compositional, multi-hop reasoning over very long video streams. In this work, we address these challenges through EGAgent, an enhanced agentic framework centered on entity scene graphs, which represent people, places, objects, and their relationships over time. Our system equips a planning agent with tools for structured search and reasoning over these graphs, as well as hybrid visual and audio search capabilities, enabling detailed, cross-modal, and temporally coherent reasoning. Experiments on the EgoLifeQA and Video-MME (Long) datasets show that our method achieves state-of-the-art performance on EgoLifeQA (57.5%) and competitive performance on Video-MME (Long) (74.1%) for complex longitudinal video understanding tasks.
Reading Recognition in the Wild
May 30, 2025To enable egocentric contextual AI in always-on smart glasses, it is crucial to be able to keep a record of the user's interactions with the world, including during reading. In this paper, we introduce a new task of reading recognition to determine when the user is reading. We first introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We then identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading understanding studies conducted in constrained settings to larger scale, diversity and realism. Code, model, and data will be public.
Generative Data Mining with Longtail-Guided Diffusion
Feb 04, 2025
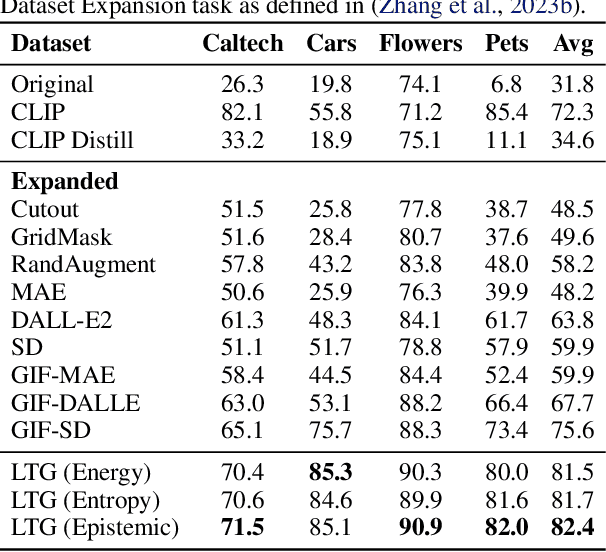
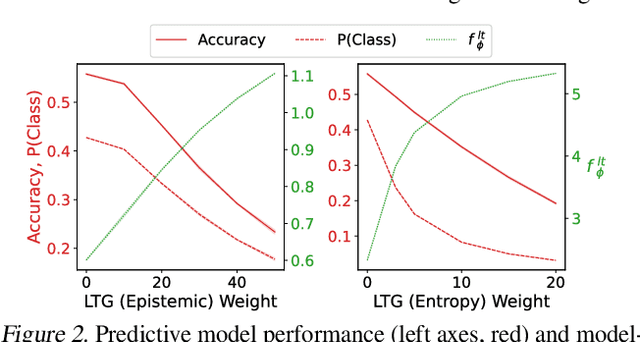
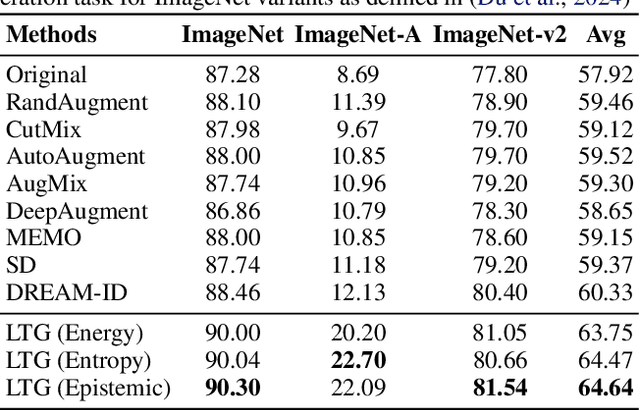
It is difficult to anticipate the myriad challenges that a predictive model will encounter once deployed. Common practice entails a reactive, cyclical approach: model deployment, data mining, and retraining. We instead develop a proactive longtail discovery process by imagining additional data during training. In particular, we develop general model-based longtail signals, including a differentiable, single forward pass formulation of epistemic uncertainty that does not impact model parameters or predictive performance but can flag rare or hard inputs. We leverage these signals as guidance to generate additional training data from a latent diffusion model in a process we call Longtail Guidance (LTG). Crucially, we can perform LTG without retraining the diffusion model or the predictive model, and we do not need to expose the predictive model to intermediate diffusion states. Data generated by LTG exhibit semantically meaningful variation, yield significant generalization improvements on image classification benchmarks, and can be analyzed to proactively discover, explain, and address conceptual gaps in a predictive model.
DriveGPT: Scaling Autoregressive Behavior Models for Driving
Dec 19, 2024



We present DriveGPT, a scalable behavior model for autonomous driving. We model driving as a sequential decision making task, and learn a transformer model to predict future agent states as tokens in an autoregressive fashion. We scale up our model parameters and training data by multiple orders of magnitude, enabling us to explore the scaling properties in terms of dataset size, model parameters, and compute. We evaluate DriveGPT across different scales in a planning task, through both quantitative metrics and qualitative examples including closed-loop driving in complex real-world scenarios. In a separate prediction task, DriveGPT outperforms a state-of-the-art baseline and exhibits improved performance by pretraining on a large-scale dataset, further validating the benefits of data scaling.
PROFIT: A Specialized Optimizer for Deep Fine Tuning
Dec 09, 2024

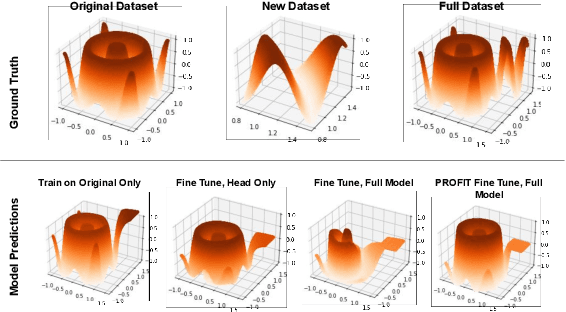
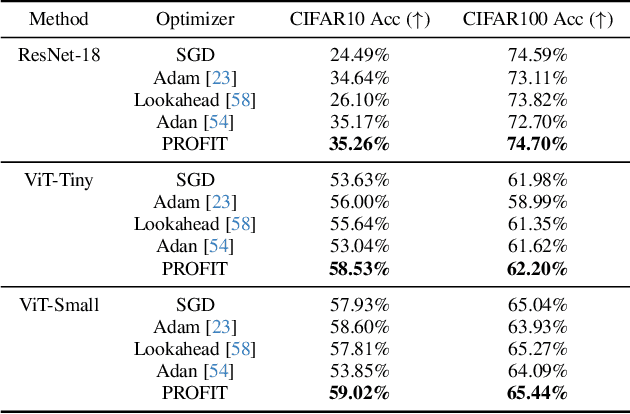
Fine-tuning pre-trained models has become invaluable in computer vision and robotics. Recent fine-tuning approaches focus on improving efficiency rather than accuracy by using a mixture of smaller learning rates or frozen backbones. To return the spotlight to model accuracy, we present PROFIT (Proximally Restricted Optimizer For Iterative Training), one of the first optimizers specifically designed for incrementally fine-tuning converged models on new tasks or datasets. Unlike traditional optimizers such as SGD or Adam, which make minimal assumptions due to random initialization, PROFIT leverages the structure of a converged model to regularize the optimization process, leading to improved results. By employing a simple temporal gradient orthogonalization process, PROFIT outperforms traditional fine-tuning methods across various tasks: image classification, representation learning, and large-scale motion prediction. Moreover, PROFIT is encapsulated within the optimizer logic, making it easily integrated into any training pipeline with minimal engineering effort. A new class of fine-tuning optimizers like PROFIT can drive advancements as fine-tuning and incremental training become increasingly prevalent, reducing reliance on costly model training from scratch.
PROFIT: A PROximal FIne Tuning Optimizer for Multi-Task Learning
Dec 02, 2024Fine-tuning pre-trained models has become invaluable in computer vision and robotics. Recent fine-tuning approaches focus on improving efficiency rather than accuracy by using a mixture of smaller learning rates or frozen backbones. To return the spotlight to model accuracy, we present PROFIT, one of the first optimizers specifically designed for incrementally fine-tuning converged models on new tasks or datasets. Unlike traditional optimizers such as SGD or Adam, which make minimal assumptions due to random initialization, PROFIT leverages the structure of a converged model to regularize the optimization process, leading to improved results. By employing a simple temporal gradient orthogonalization process, PROFIT outperforms traditional fine-tuning methods across various tasks: image classification, representation learning, and large-scale motion prediction. Moreover, PROFIT is encapsulated within the optimizer logic, making it easily integrated into any training pipeline with minimal engineering effort. A new class of fine-tuning optimizers like PROFIT can drive advancements as fine-tuning and incremental training become increasingly prevalent, reducing reliance on costly model training from scratch.
Cohere3D: Exploiting Temporal Coherence for Unsupervised Representation Learning of Vision-based Autonomous Driving
Feb 23, 2024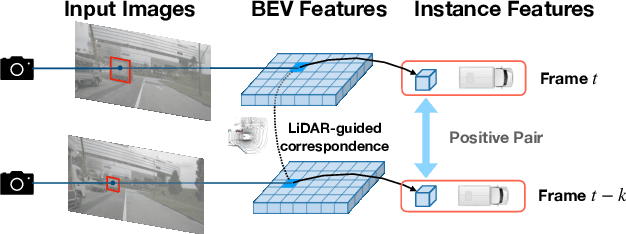
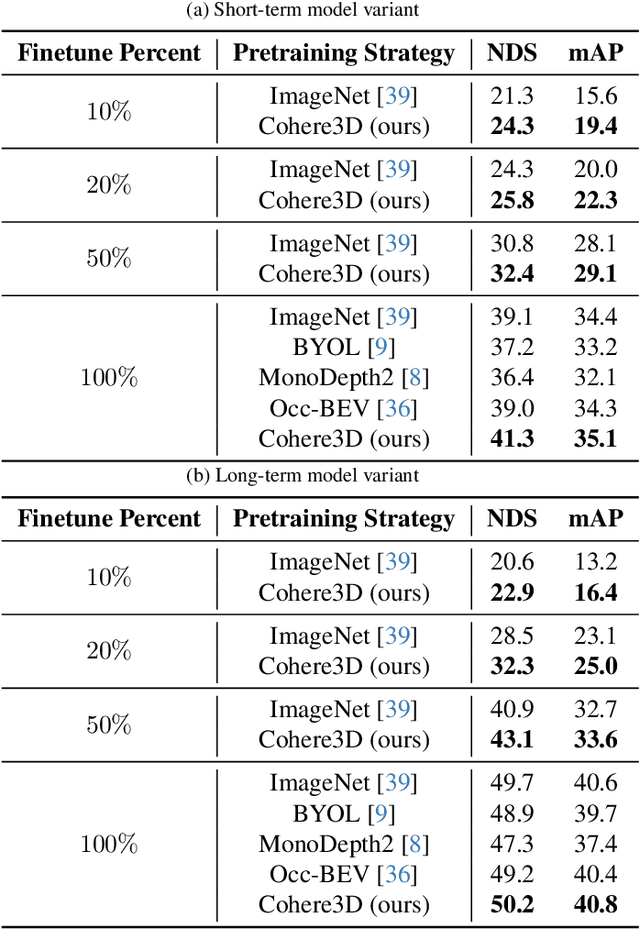
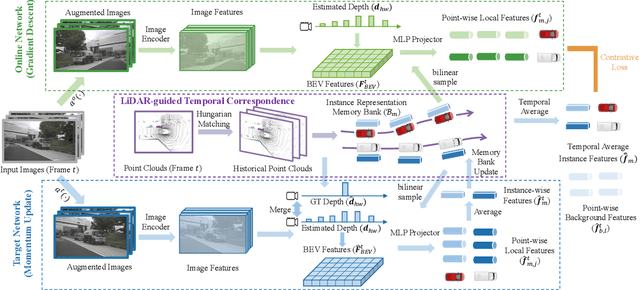

Due to the lack of depth cues in images, multi-frame inputs are important for the success of vision-based perception, prediction, and planning in autonomous driving. Observations from different angles enable the recovery of 3D object states from 2D image inputs if we can identify the same instance in different input frames. However, the dynamic nature of autonomous driving scenes leads to significant changes in the appearance and shape of each instance captured by the camera at different time steps. To this end, we propose a novel contrastive learning algorithm, Cohere3D, to learn coherent instance representations in a long-term input sequence robust to the change in distance and perspective. The learned representation aids in instance-level correspondence across multiple input frames in downstream tasks. In the pretraining stage, the raw point clouds from LiDAR sensors are utilized to construct the long-term temporal correspondence for each instance, which serves as guidance for the extraction of instance-level representation from the vision-based bird's eye-view (BEV) feature map. Cohere3D encourages a consistent representation for the same instance at different frames but distinguishes between representations of different instances. We evaluate our algorithm by finetuning the pretrained model on various downstream perception, prediction, and planning tasks. Results show a notable improvement in both data efficiency and task performance.
Making Large Multimodal Models Understand Arbitrary Visual Prompts
Dec 01, 2023

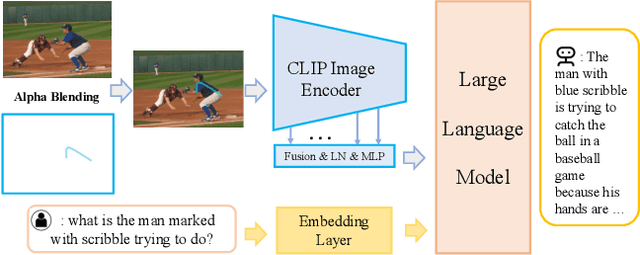

While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a "red bounding box" or "pointed arrow". Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.
SHIFT3D: Synthesizing Hard Inputs For Tricking 3D Detectors
Sep 11, 2023



We present SHIFT3D, a differentiable pipeline for generating 3D shapes that are structurally plausible yet challenging to 3D object detectors. In safety-critical applications like autonomous driving, discovering such novel challenging objects can offer insight into unknown vulnerabilities of 3D detectors. By representing objects with a signed distanced function (SDF), we show that gradient error signals allow us to smoothly deform the shape or pose of a 3D object in order to confuse a downstream 3D detector. Importantly, the objects generated by SHIFT3D physically differ from the baseline object yet retain a semantically recognizable shape. Our approach provides interpretable failure modes for modern 3D object detectors, and can aid in preemptive discovery of potential safety risks within 3D perception systems before these risks become critical failures.
NOVA: NOvel View Augmentation for Neural Composition of Dynamic Objects
Aug 24, 2023We propose a novel-view augmentation (NOVA) strategy to train NeRFs for photo-realistic 3D composition of dynamic objects in a static scene. Compared to prior work, our framework significantly reduces blending artifacts when inserting multiple dynamic objects into a 3D scene at novel views and times; achieves comparable PSNR without the need for additional ground truth modalities like optical flow; and overall provides ease, flexibility, and scalability in neural composition. Our codebase is on GitHub.