 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROFIT: A Specialized Optimizer for Deep Fine Tuning
Dec 09, 2024

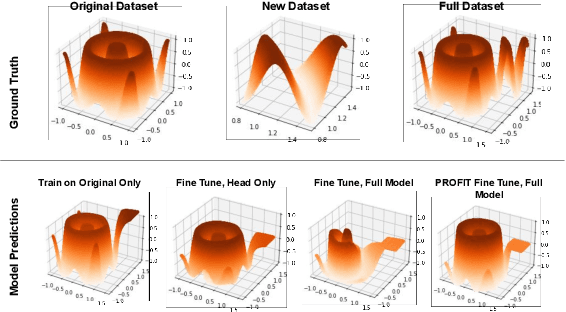
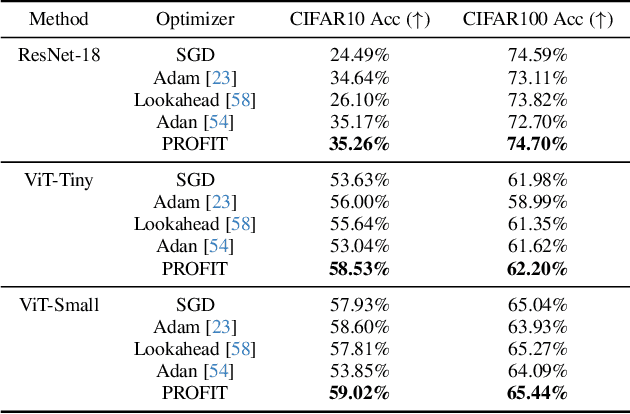
Fine-tuning pre-trained models has become invaluable in computer vision and robotics. Recent fine-tuning approaches focus on improving efficiency rather than accuracy by using a mixture of smaller learning rates or frozen backbones. To return the spotlight to model accuracy, we present PROFIT (Proximally Restricted Optimizer For Iterative Training), one of the first optimizers specifically designed for incrementally fine-tuning converged models on new tasks or datasets. Unlike traditional optimizers such as SGD or Adam, which make minimal assumptions due to random initialization, PROFIT leverages the structure of a converged model to regularize the optimization process, leading to improved results. By employing a simple temporal gradient orthogonalization process, PROFIT outperforms traditional fine-tuning methods across various tasks: image classification, representation learning, and large-scale motion prediction. Moreover, PROFIT is encapsulated within the optimizer logic, making it easily integrated into any training pipeline with minimal engineering effort. A new class of fine-tuning optimizers like PROFIT can drive advancements as fine-tuning and incremental training become increasingly prevalent, reducing reliance on costly model training from scratch.
PROFIT: A PROximal FIne Tuning Optimizer for Multi-Task Learning
Dec 02, 2024Fine-tuning pre-trained models has become invaluable in computer vision and robotics. Recent fine-tuning approaches focus on improving efficiency rather than accuracy by using a mixture of smaller learning rates or frozen backbones. To return the spotlight to model accuracy, we present PROFIT, one of the first optimizers specifically designed for incrementally fine-tuning converged models on new tasks or datasets. Unlike traditional optimizers such as SGD or Adam, which make minimal assumptions due to random initialization, PROFIT leverages the structure of a converged model to regularize the optimization process, leading to improved results. By employing a simple temporal gradient orthogonalization process, PROFIT outperforms traditional fine-tuning methods across various tasks: image classification, representation learning, and large-scale motion prediction. Moreover, PROFIT is encapsulated within the optimizer logic, making it easily integrated into any training pipeline with minimal engineering effort. A new class of fine-tuning optimizers like PROFIT can drive advancements as fine-tuning and incremental training become increasingly prevalent, reducing reliance on costly model training from scratch.
Lidar Panoptic Segmentation in an Open World
Sep 22, 2024Addressing Lidar Panoptic Segmentation (LPS ) is crucial for safe deployment of autonomous vehicles. LPS aims to recognize and segment lidar points w.r.t. a pre-defined vocabulary of semantic classes, including thing classes of countable objects (e.g., pedestrians and vehicles) and stuff classes of amorphous regions (e.g., vegetation and road). Importantly, LPS requires segmenting individual thing instances (e.g., every single vehicle). Current LPS methods make an unrealistic assumption that the semantic class vocabulary is fixed in the real open world, but in fact, class ontologies usually evolve over time as robots encounter instances of novel classes that are considered to be unknowns w.r.t. the pre-defined class vocabulary. To address this unrealistic assumption, we study LPS in the Open World (LiPSOW): we train models on a dataset with a pre-defined semantic class vocabulary and study their generalization to a larger dataset where novel instances of thing and stuff classes can appear. This experimental setting leads to interesting conclusions. While prior art train class-specific instance segmentation methods and obtain state-of-the-art results on known classes, methods based on class-agnostic bottom-up grouping perform favorably on classes outside of the initial class vocabulary (i.e., unknown classes). Unfortunately, these methods do not perform on-par with fully data-driven methods on known classes. Our work suggests a middle ground: we perform class-agnostic point clustering and over-segment the input cloud in a hierarchical fashion, followed by binary point segment classification, akin to Region Proposal Network [1]. We obtain the final point cloud segmentation by computing a cut in the weighted hierarchical tree of point segments, independently of semantic classification. Remarkably, this unified approach leads to strong performance on both known and unknown classes.
Nighttime Dehaze-Enhancement
Oct 18, 2022
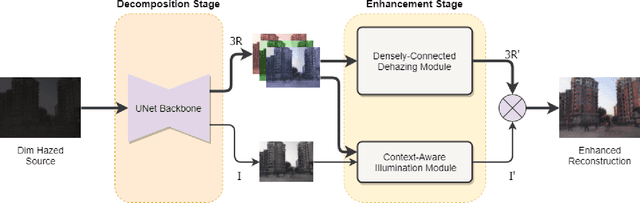


In this paper, we introduce a new computer vision task called nighttime dehaze-enhancement. This task aims to jointly perform dehazing and lightness enhancement. Our task fundamentally differs from nighttime dehazing -- our goal is to jointly dehaze and enhance scenes, while nighttime dehazing aims to dehaze scenes under a nighttime setting. In order to facilitate further research on this task, we release a new benchmark dataset called Reside-$\beta$ Night dataset, consisting of 4122 nighttime hazed images from 2061 scenes and 2061 ground truth images. Moreover, we also propose a new network called NDENet (Nighttime Dehaze-Enhancement Network), which jointly performs dehazing and low-light enhancement in an end-to-end manner. We evaluate our method on the proposed benchmark and achieve SSIM of 0.8962 and PSNR of 26.25. We also compare our network with other baseline networks on our benchmark to demonstrate the effectiveness of our approach. We believe that nighttime dehaze-enhancement is an essential task particularly for autonomous navigation applications, and hope that our work will open up new frontiers in research. Our dataset and code will be made publicly available upon acceptance of our paper.
Object Propagation via Inter-Frame Attentions for Temporally Stable Video Instance Segmentation
Nov 15, 2021
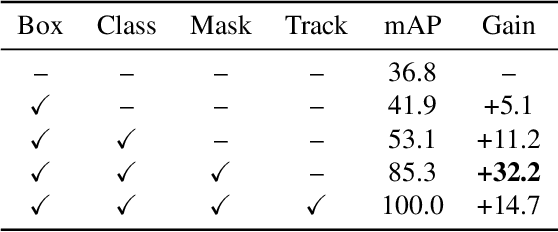

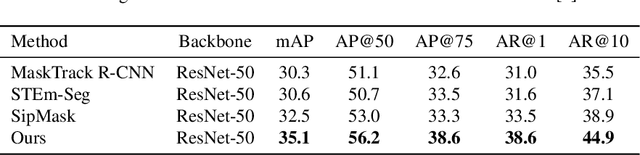
Video instance segmentation aims to detect, segment, and track objects in a video. Current approaches extend image-level segmentation algorithms to the temporal domain. However, this results in temporally inconsistent masks. In this work, we identify the mask quality due to temporal stability as a performance bottleneck. Motivated by this, we propose a video instance segmentation method that alleviates the problem due to missing detections. Since this cannot be solved simply using spatial information, we leverage temporal context using inter-frame attentions. This allows our network to refocus on missing objects using box predictions from the neighbouring frame, thereby overcoming missing detections. Our method significantly outperforms previous state-of-the-art algorithms using the Mask R-CNN backbone, by achieving 35.1% mAP on the YouTube-VIS benchmark. Additionally, our method is completely online and requires no future frames. Our code is publicly available at https://github.com/anirudh-chakravarthy/ObjProp.