 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROFIT: A PROximal FIne Tuning Optimizer for Multi-Task Learning
Paper and Code
Dec 02, 2024

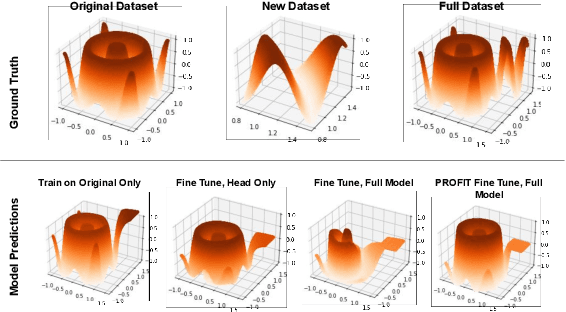
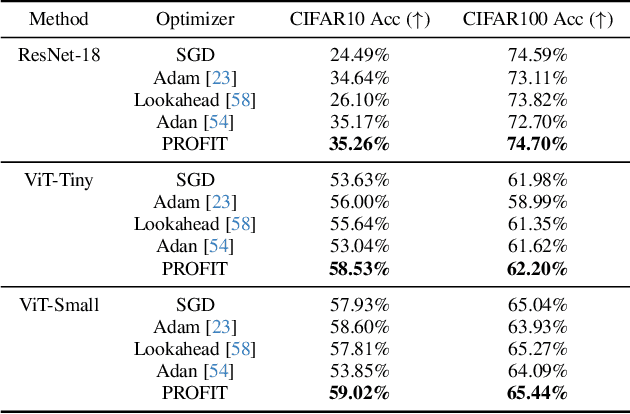
Fine-tuning pre-trained models has become invaluable in computer vision and robotics. Recent fine-tuning approaches focus on improving efficiency rather than accuracy by using a mixture of smaller learning rates or frozen backbones. To return the spotlight to model accuracy, we present PROFIT, one of the first optimizers specifically designed for incrementally fine-tuning converged models on new tasks or datasets. Unlike traditional optimizers such as SGD or Adam, which make minimal assumptions due to random initialization, PROFIT leverages the structure of a converged model to regularize the optimization process, leading to improved results. By employing a simple temporal gradient orthogonalization process, PROFIT outperforms traditional fine-tuning methods across various tasks: image classification, representation learning, and large-scale motion prediction. Moreover, PROFIT is encapsulated within the optimizer logic, making it easily integrated into any training pipeline with minimal engineering effort. A new class of fine-tuning optimizers like PROFIT can drive advancements as fine-tuning and incremental training become increasingly prevalent, reducing reliance on costly model training from scratch.