 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCytoCrowd: A Multi-Annotator Benchmark Dataset for Cytology Image Analysis
Feb 06, 2026High-quality annotated datasets are crucial for advancing machine learning in medical image analysis. However, a critical gap exists: most datasets either offer a single, clean ground truth, which hides real-world expert disagreement, or they provide multiple annotations without a separate gold standard for objective evaluation. To bridge this gap, we introduce CytoCrowd, a new public benchmark for cytology analysis. The dataset features 446 high-resolution images, each with two key components: (1) raw, conflicting annotations from four independent pathologists, and (2) a separate, high-quality gold-standard ground truth established by a senior expert. This dual structure makes CytoCrowd a versatile resource. It serves as a benchmark for standard computer vision tasks, such as object detection and classification, using the ground truth. Simultaneously, it provides a realistic testbed for evaluating annotation aggregation algorithms that must resolve expert disagreements. We provide comprehensive baseline results for both tasks. Our experiments demonstrate the challenges presented by CytoCrowd and establish its value as a resource for developing the next generation of models for medical image analysis.
SCAR: A Characterization Scheme for Multi-Modal Dataset
Aug 27, 2025Foundation models exhibit remarkable generalization across diverse tasks, largely driven by the characteristics of their training data. Recent data-centric methods like pruning and compression aim to optimize training but offer limited theoretical insight into how data properties affect generalization, especially the data characteristics in sample scaling. Traditional perspectives further constrain progress by focusing predominantly on data quantity and training efficiency, often overlooking structural aspects of data quality. In this study, we introduce SCAR, a principled scheme for characterizing the intrinsic structural properties of datasets across four key measures: Scale, Coverage, Authenticity, and Richness. Unlike prior data-centric measures, SCAR captures stable characteristics that remain invariant under dataset scaling, providing a robust and general foundation for data understanding. Leveraging these structural properties, we introduce Foundation Data-a minimal subset that preserves the generalization behavior of the full dataset without requiring model-specific retraining. We model single-modality tasks as step functions and estimate the distribution of the foundation data size to capture step-wise generalization bias across modalities in the target multi-modal dataset. Finally, we develop a SCAR-guided data completion strategy based on this generalization bias, which enables efficient, modality-aware expansion of modality-specific characteristics in multimodal datasets. Experiments across diverse multi-modal datasets and model architectures validate the effectiveness of SCAR in predicting data utility and guiding data acquisition. Code is available at https://github.com/McAloma/SCAR.
Interpretable Deep Regression Models with Interval-Censored Failure Time Data
Mar 25, 2025Deep neural networks (DNNs) have become powerful tools for modeling complex data structures through sequentially integrating simple functions in each hidden layer. In survival analysis, recent advances of DNNs primarily focus on enhancing model capabilities, especially in exploring nonlinear covariate effects under right censoring. However, deep learning methods for interval-censored data, where the unobservable failure time is only known to lie in an interval, remain underexplored and limited to specific data type or model. This work proposes a general regression framework for interval-censored data with a broad class of partially linear transformation models, where key covariate effects are modeled parametrically while nonlinear effects of nuisance multi-modal covariates are approximated via DNNs, balancing interpretability and flexibility. We employ sieve maximum likelihood estimation by leveraging monotone splines to approximate the cumulative baseline hazard function. To ensure reliable and tractable estimation, we develop an EM algorithm incorporating stochastic gradient descent. We establish the asymptotic properties of parameter estimators and show that the DNN estimator achieves minimax-optimal convergence. Extensive simulations demonstrate superior estimation and prediction accuracy over state-of-the-art methods. Applying our method to the Alzheimer's Disease Neuroimaging Initiative dataset yields novel insights and improved predictive performance compared to traditional approaches.
Generative Data Mining with Longtail-Guided Diffusion
Feb 04, 2025
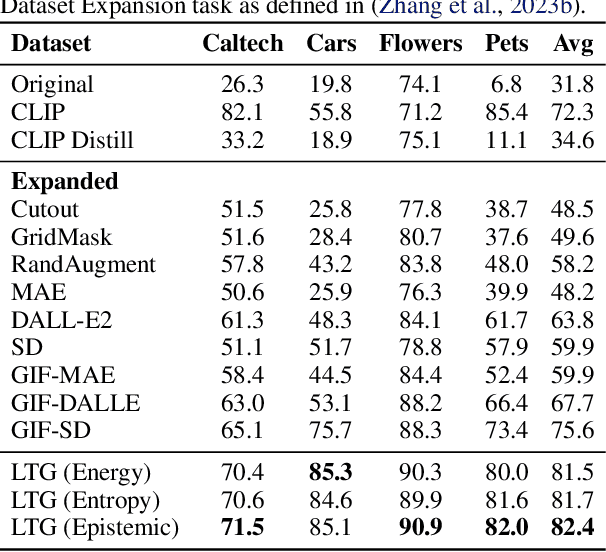
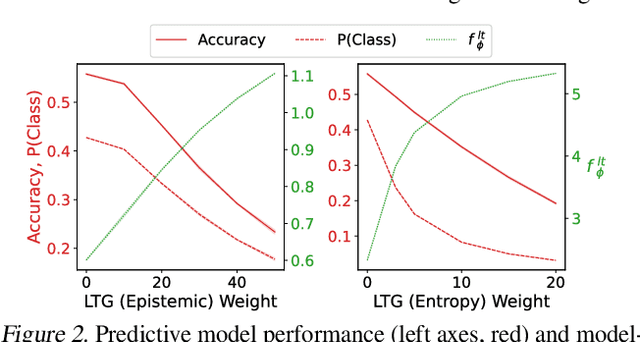
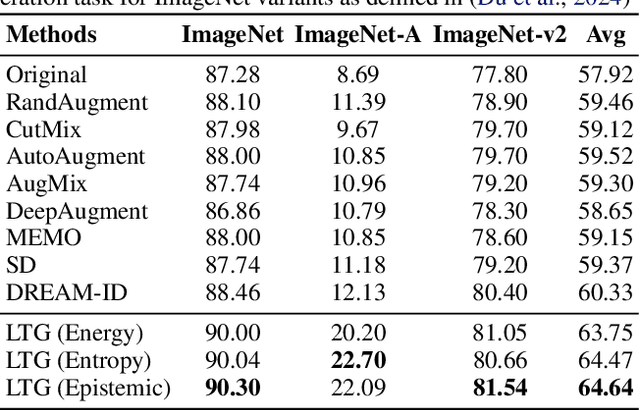
It is difficult to anticipate the myriad challenges that a predictive model will encounter once deployed. Common practice entails a reactive, cyclical approach: model deployment, data mining, and retraining. We instead develop a proactive longtail discovery process by imagining additional data during training. In particular, we develop general model-based longtail signals, including a differentiable, single forward pass formulation of epistemic uncertainty that does not impact model parameters or predictive performance but can flag rare or hard inputs. We leverage these signals as guidance to generate additional training data from a latent diffusion model in a process we call Longtail Guidance (LTG). Crucially, we can perform LTG without retraining the diffusion model or the predictive model, and we do not need to expose the predictive model to intermediate diffusion states. Data generated by LTG exhibit semantically meaningful variation, yield significant generalization improvements on image classification benchmarks, and can be analyzed to proactively discover, explain, and address conceptual gaps in a predictive model.
MRAG: A Modular Retrieval Framework for Time-Sensitive Question Answering
Dec 20, 2024



Understanding temporal relations and answering time-sensitive questions is crucial yet a challenging task for question-answering systems powered by large language models (LLMs). Existing approaches either update the parametric knowledge of LLMs with new facts, which is resource-intensive and often impractical, or integrate LLMs with external knowledge retrieval (i.e., retrieval-augmented generation). However, off-the-shelf retrievers often struggle to identify relevant documents that require intensive temporal reasoning. To systematically study time-sensitive question answering, we introduce the TempRAGEval benchmark, which repurposes existing datasets by incorporating temporal perturbations and gold evidence labels. As anticipated, all existing retrieval methods struggle with these temporal reasoning-intensive questions. We further propose Modular Retrieval (MRAG), a trainless framework that includes three modules: (1) Question Processing that decomposes question into a main content and a temporal constraint; (2) Retrieval and Summarization that retrieves evidence and uses LLMs to summarize according to the main content; (3) Semantic-Temporal Hybrid Ranking that scores each evidence summarization based on both semantic and temporal relevance. On TempRAGEval, MRAG significantly outperforms baseline retrievers in retrieval performance, leading to further improvements in final answer accuracy.
PROFIT: A Specialized Optimizer for Deep Fine Tuning
Dec 09, 2024

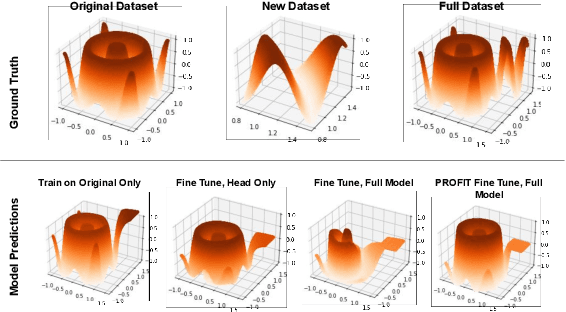
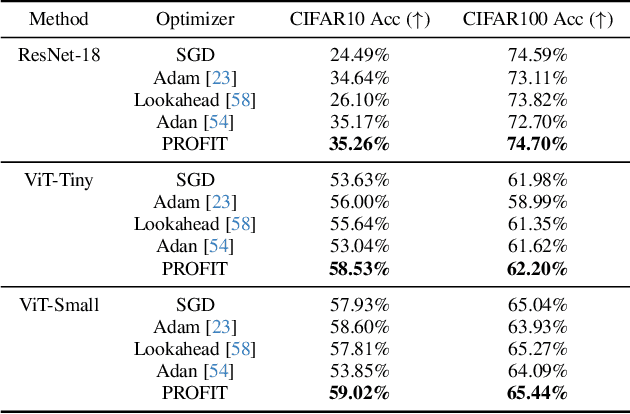
Fine-tuning pre-trained models has become invaluable in computer vision and robotics. Recent fine-tuning approaches focus on improving efficiency rather than accuracy by using a mixture of smaller learning rates or frozen backbones. To return the spotlight to model accuracy, we present PROFIT (Proximally Restricted Optimizer For Iterative Training), one of the first optimizers specifically designed for incrementally fine-tuning converged models on new tasks or datasets. Unlike traditional optimizers such as SGD or Adam, which make minimal assumptions due to random initialization, PROFIT leverages the structure of a converged model to regularize the optimization process, leading to improved results. By employing a simple temporal gradient orthogonalization process, PROFIT outperforms traditional fine-tuning methods across various tasks: image classification, representation learning, and large-scale motion prediction. Moreover, PROFIT is encapsulated within the optimizer logic, making it easily integrated into any training pipeline with minimal engineering effort. A new class of fine-tuning optimizers like PROFIT can drive advancements as fine-tuning and incremental training become increasingly prevalent, reducing reliance on costly model training from scratch.
PROFIT: A PROximal FIne Tuning Optimizer for Multi-Task Learning
Dec 02, 2024Fine-tuning pre-trained models has become invaluable in computer vision and robotics. Recent fine-tuning approaches focus on improving efficiency rather than accuracy by using a mixture of smaller learning rates or frozen backbones. To return the spotlight to model accuracy, we present PROFIT, one of the first optimizers specifically designed for incrementally fine-tuning converged models on new tasks or datasets. Unlike traditional optimizers such as SGD or Adam, which make minimal assumptions due to random initialization, PROFIT leverages the structure of a converged model to regularize the optimization process, leading to improved results. By employing a simple temporal gradient orthogonalization process, PROFIT outperforms traditional fine-tuning methods across various tasks: image classification, representation learning, and large-scale motion prediction. Moreover, PROFIT is encapsulated within the optimizer logic, making it easily integrated into any training pipeline with minimal engineering effort. A new class of fine-tuning optimizers like PROFIT can drive advancements as fine-tuning and incremental training become increasingly prevalent, reducing reliance on costly model training from scratch.
LightWeather: Harnessing Absolute Positional Encoding to Efficient and Scalable Global Weather Forecasting
Aug 19, 2024



Recently, Transformers have gained traction in weather forecasting for their capability to capture long-term spatial-temporal correlations. However, their complex architectures result in large parameter counts and extended training times, limiting their practical application and scalability to global-scale forecasting. This paper aims to explore the key factor for accurate weather forecasting and design more efficient solutions. Interestingly, our empirical findings reveal that absolute positional encoding is what really works in Transformer-based weather forecasting models, which can explicitly model the spatial-temporal correlations even without attention mechanisms. We theoretically prove that its effectiveness stems from the integration of geographical coordinates and real-world time features, which are intrinsically related to the dynamics of weather. Based on this, we propose LightWeather, a lightweight and effective model for station-based global weather forecasting. We employ absolute positional encoding and a simple MLP in place of other components of Transformer. With under 30k parameters and less than one hour of training time, LightWeather achieves state-of-the-art performance on global weather datasets compared to other advanced DL methods. The results underscore the superiority of integrating spatial-temporal knowledge over complex architectures, providing novel insights for DL in weather forecasting.
HDR Imaging for Dynamic Scenes with Events
Apr 04, 2024


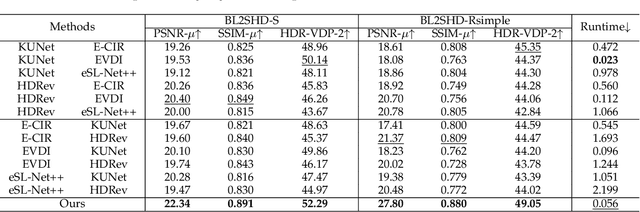
High dynamic range imaging (HDRI) for real-world dynamic scenes is challenging because moving objects may lead to hybrid degradation of low dynamic range and motion blur. Existing event-based approaches only focus on a separate task, while cascading HDRI and motion deblurring would lead to sub-optimal solutions, and unavailable ground-truth sharp HDR images aggravate the predicament. To address these challenges, we propose an Event-based HDRI framework within a Self-supervised learning paradigm, i.e., Self-EHDRI, which generalizes HDRI performance in real-world dynamic scenarios. Specifically, a self-supervised learning strategy is carried out by learning cross-domain conversions from blurry LDR images to sharp LDR images, which enables sharp HDR images to be accessible in the intermediate process even though ground-truth sharp HDR images are missing. Then, we formulate the event-based HDRI and motion deblurring model and conduct a unified network to recover the intermediate sharp HDR results, where both the high dynamic range and high temporal resolution of events are leveraged simultaneously for compensation. We construct large-scale synthetic and real-world datasets to evaluate the effectiveness of our method. Comprehensive experiments demonstrate that the proposed Self-EHDRI outperforms state-of-the-art approaches by a large margin. The codes, datasets, and results are available at https://lxp-whu.github.io/Self-EHDRI.
SHIFT3D: Synthesizing Hard Inputs For Tricking 3D Detectors
Sep 11, 2023



We present SHIFT3D, a differentiable pipeline for generating 3D shapes that are structurally plausible yet challenging to 3D object detectors. In safety-critical applications like autonomous driving, discovering such novel challenging objects can offer insight into unknown vulnerabilities of 3D detectors. By representing objects with a signed distanced function (SDF), we show that gradient error signals allow us to smoothly deform the shape or pose of a 3D object in order to confuse a downstream 3D detector. Importantly, the objects generated by SHIFT3D physically differ from the baseline object yet retain a semantically recognizable shape. Our approach provides interpretable failure modes for modern 3D object detectors, and can aid in preemptive discovery of potential safety risks within 3D perception systems before these risks become critical failures.