 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning for Multi-Center Sepsis Early Prediction with Privacy-Preserving
Jun 03, 2026Privacy-sensitive and distributed characteristics of multi-center medical data bring severe obstacles to centralized modeling for accurate early prediction of sepsis. Federated learning (FL) has attracted growing attention as a promising framework for collaborative model development, as it allows multiple institutions to jointly train predictive models without directly sharing or centralizing raw data. Nevertheless, its practical performance, robustness, and privacy-preserving benefits remain insufficiently evaluated using real-world clinical datasets. To bridge this gap, this study systematically examines the application of federated learning to multi-center sepsis prediction. The experimental dataset consists of 648 clinically screened samples collected from three tertiary hospitals in China, with rigorous inclusion and exclusion criteria. We establish a centralized training paradigm as the performance baseline, and then implement a horizontal federated learning framework for distributed collaborative modeling. Extensive experimental results demonstrate that the federated learning-based model achieves highly comparable prediction accuracy to the centralized counterpart, while fundamentally avoiding privacy leakage. Further privacy security analysis verifies that malicious attackers cannot reconstruct the original patient data from the transmitted model parameters, indicating strong resistance against data reconstruction attacks. This work not only validates the practicality and security of federated learning in clinical sepsis prediction, but also provides a reliable and feasible solution for privacy-preserving multi-center medical collaboration.
Graph-RHO: Critical-path-aware Heterogeneous Graph Network for Long-Horizon Flexible Job-Shop Scheduling
Apr 11, 2026Long-horizon Flexible Job-Shop Scheduling~(FJSP) presents a formidable combinatorial challenge due to complex, interdependent decisions spanning extended time horizons. While learning-based Rolling Horizon Optimization~(RHO) has emerged as a promising paradigm to accelerate solving by identifying and fixing invariant operations, its effectiveness is hindered by the structural complexity of FJSP. Existing methods often fail to capture intricate graph-structured dependencies and ignore the asymmetric costs of prediction errors, in which misclassifying critical-path operations is significantly more detrimental than misclassifying non-critical ones. Furthermore, dynamic shifts in predictive confidence during the rolling process make static pruning thresholds inadequate. To address these limitations, we propose Graph-RHO, a novel critical-path-aware graph-based RHO framework. First, we introduce a topology-aware heterogeneous graph network that encodes subproblems as operation-machine graphs with multi-relational edges, leveraging edge-feature-aware message passing to predict operation stability. Second, we incorporate a critical-path-aware mechanism that injects inductive biases during training to distinguish highly sensitive bottleneck operations from robust ones. Third, we devise an adaptive thresholding strategy that dynamically calibrates decision boundaries based on online uncertainty estimation to align model predictions with the solver's search space. Extensive experiments on standard benchmarks demonstrate that \mbox{Graph-RHO} establishes a new state of the art in solution quality and computational efficiency. Remarkably, it exhibits exceptional zero-shot generalization, reducing solve time by over 30\% on large-scale instances (2000 operations) while achieving superior solution quality. Our code is available \href{https://github.com/IntelliSensing/Graph-RHO}{here}.
Prior-guided Fusion of Multimodal Features for Change Detection from Optical-SAR Images
Apr 07, 2026Multimodal change detection (MMCD) identifies changed areas in multimodal remote sensing (RS) data, demonstrating significant application value in land use monitoring, disaster assessment, and urban sustainable development. However, literature MMCD approaches exhibit limitations in cross-modal interaction and exploiting modality-specific characteristics. This leads to insufficient modeling of fine-grained change information, thus hindering the precise detection of semantic changes in multimodal data. To address the above problems, we propose STSF-Net, a framework designed for MMCD between optical and SAR images. STSF-Net jointly models modality-specific and spatio-temporal common features to enhance change representations. Specifically, modality-specific features are exploited to capture genuine semantic change signals, while spatio-temporal common features are embedded to suppress pseudo-changes caused by differences in imaging mechanisms. Furthermore, we introduce an optical and SAR feature fusion strategy that adaptively adjusts feature importance based on semantic priors obtained from pre-trained foundational models, enabling semantic-guided adaptive fusion of multi-modal information. In addition, we introduce the Delta-SN6 dataset, the first openly-accessible multiclass MMCD benchmark consisting of very-high-resolution (VHR) fully polarimetric SAR and optical images. Experimental results on Delta-SN6, BRIGHT, and Wuhan-Het datasets demonstrate that our method outperforms the state-of-the-art (SOTA) by 3.21%, 1.08%, and 1.32% in mIoU, respectively. The associated code and Delta-SN6 dataset will be released at: https://github.com/liuxuanguang/STSF-Net.
Nighttime Hazy Image Enhancement via Progressively and Mutually Reinforcing Night-Haze Priors
Jan 05, 2026Enhancing the visibility of nighttime hazy images is challenging due to the complex degradation distributions. Existing methods mainly address a single type of degradation (e.g., haze or low-light) at a time, ignoring the interplay of different degradation types and resulting in limited visibility improvement. We observe that the domain knowledge shared between low-light and haze priors can be reinforced mutually for better visibility. Based on this key insight, in this paper, we propose a novel framework that enhances visibility in nighttime hazy images by reinforcing the intrinsic consistency between haze and low-light priors mutually and progressively. In particular, our model utilizes image-, patch-, and pixel-level experts that operate across visual and frequency domains to recover global scene structure, regional patterns, and fine-grained details progressively. A frequency-aware router is further introduced to adaptively guide the contribution of each expert, ensuring robust image restoration. Extensive experiments demonstrate the superior performance of our model on nighttime dehazing benchmarks both quantitatively and qualitatively. Moreover, we showcase the generalizability of our model in daytime dehazing and low-light enhancement tasks.
API: Empowering Generalizable Real-World Image Dehazing via Adaptive Patch Importance Learning
Jan 05, 2026Real-world image dehazing is a fundamental yet challenging task in low-level vision. Existing learning-based methods often suffer from significant performance degradation when applied to complex real-world hazy scenes, primarily due to limited training data and the intrinsic complexity of haze density distributions.To address these challenges, we introduce a novel Adaptive Patch Importance-aware (API) framework for generalizable real-world image dehazing. Specifically, our framework consists of an Automatic Haze Generation (AHG) module and a Density-aware Haze Removal (DHR) module. AHG provides a hybrid data augmentation strategy by generating realistic and diverse hazy images as additional high-quality training data. DHR considers hazy regions with varying haze density distributions for generalizable real-world image dehazing in an adaptive patch importance-aware manner. To alleviate the ambiguity of the dehazed image details, we further introduce a new Multi-Negative Contrastive Dehazing (MNCD) loss, which fully utilizes information from multiple negative samples across both spatial and frequency domains. Extensive experiments demonstrate that our framework achieves state-of-the-art performance across multiple real-world benchmarks, delivering strong results in both quantitative metrics and qualitative visual quality, and exhibiting robust generalization across diverse haze distributions.
APT: Affine Prototype-Timestamp For Time Series Forecasting Under Distribution Shift
Nov 17, 2025Time series forecasting under distribution shift remains challenging, as existing deep learning models often rely on local statistical normalization (e.g., mean and variance) that fails to capture global distribution shift. Methods like RevIN and its variants attempt to decouple distribution and pattern but still struggle with missing values, noisy observations, and invalid channel-wise affine transformation. To address these limitations, we propose Affine Prototype Timestamp (APT), a lightweight and flexible plug-in module that injects global distribution features into the normalization-forecasting pipeline. By leveraging timestamp conditioned prototype learning, APT dynamically generates affine parameters that modulate both input and output series, enabling the backbone to learn from self-supervised, distribution-aware clustered instances. APT is compatible with arbitrary forecasting backbones and normalization strategies while introducing minimal computational overhead. Extensive experiments across six benchmark datasets and multiple backbone-normalization combinations demonstrate that APT significantly improves forecasting performance under distribution shift.
End to End Autoencoder MLP Framework for Sepsis Prediction
Aug 26, 2025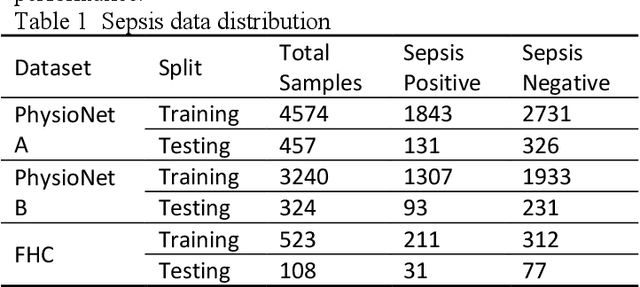
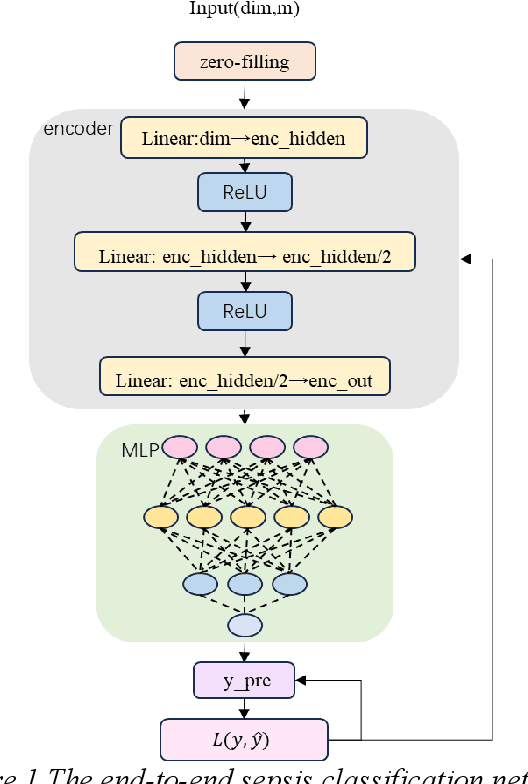
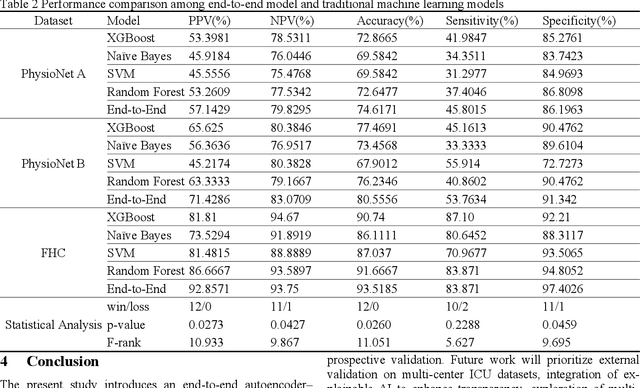
Sepsis is a life threatening condition that requires timely detection in intensive care settings. Traditional machine learning approaches, including Naive Bayes, Support Vector Machine (SVM), Random Forest, and XGBoost, often rely on manual feature engineering and struggle with irregular, incomplete time-series data commonly present in electronic health records. We introduce an end-to-end deep learning framework integrating an unsupervised autoencoder for automatic feature extraction with a multilayer perceptron classifier for binary sepsis risk prediction. To enhance clinical applicability, we implement a customized down sampling strategy that extracts high information density segments during training and a non-overlapping dynamic sliding window mechanism for real-time inference. Preprocessed time series data are represented as fixed dimension vectors with explicit missingness indicators, mitigating bias and noise. We validate our approach on three ICU cohorts. Our end-to-end model achieves accuracies of 74.6 percent, 80.6 percent, and 93.5 percent, respectively, consistently outperforming traditional machine learning baselines. These results demonstrate the framework's superior robustness, generalizability, and clinical utility for early sepsis detection across heterogeneous ICU environments.
BLAST: Balanced Sampling Time Series Corpus for Universal Forecasting Models
May 23, 2025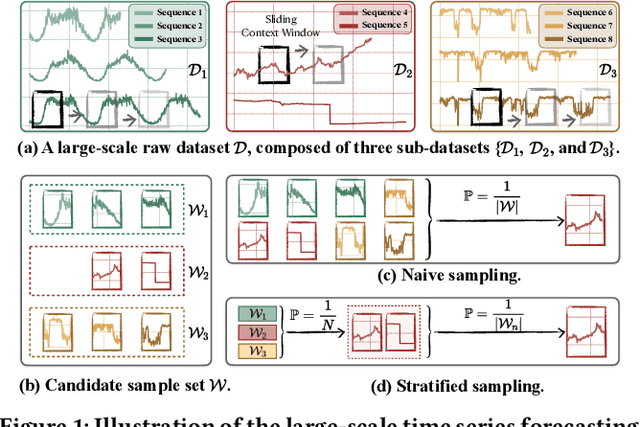
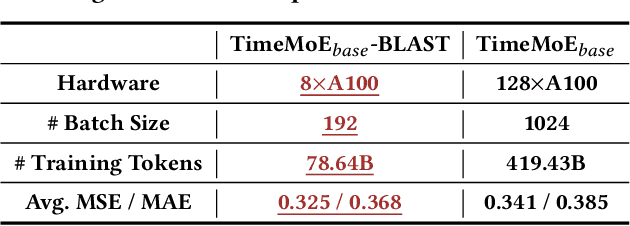
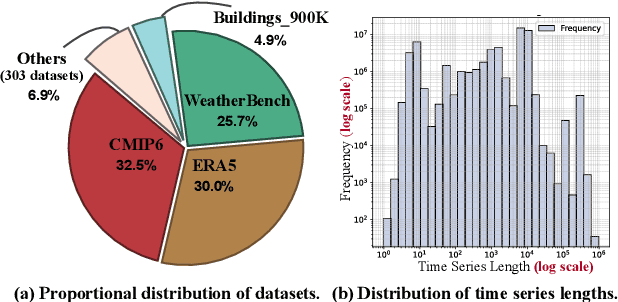
The advent of universal time series forecasting models has revolutionized zero-shot forecasting across diverse domains, yet the critical role of data diversity in training these models remains underexplored. Existing large-scale time series datasets often suffer from inherent biases and imbalanced distributions, leading to suboptimal model performance and generalization. To address this gap, we introduce BLAST, a novel pre-training corpus designed to enhance data diversity through a balanced sampling strategy. First, BLAST incorporates 321 billion observations from publicly available datasets and employs a comprehensive suite of statistical metrics to characterize time series patterns. Then, to facilitate pattern-oriented sampling, the data is implicitly clustered using grid-based partitioning. Furthermore, by integrating grid sampling and grid mixup techniques, BLAST ensures a balanced and representative coverage of diverse patterns. Experimental results demonstrate that models pre-trained on BLAST achieve state-of-the-art performance with a fraction of the computational resources and training tokens required by existing methods. Our findings highlight the pivotal role of data diversity in improving both training efficiency and model performance for the universal forecasting task.
Improving Open-world Continual Learning under the Constraints of Scarce Labeled Data
Feb 28, 2025
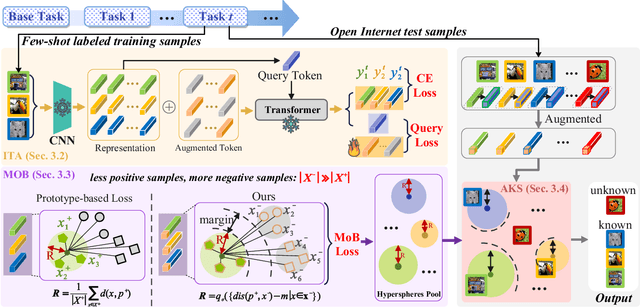
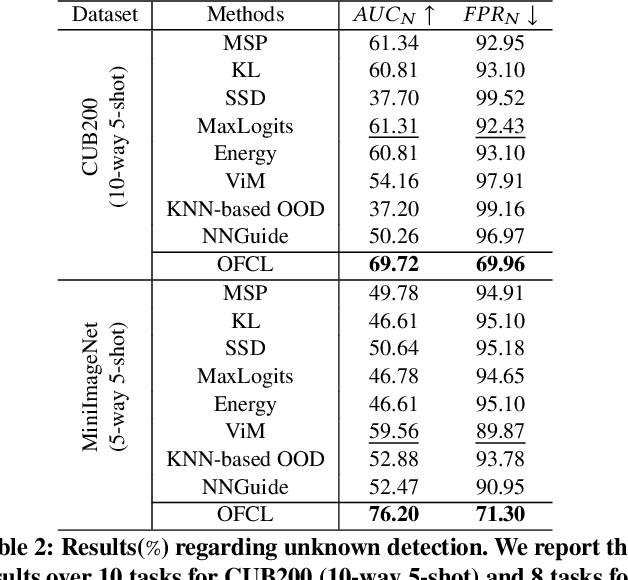
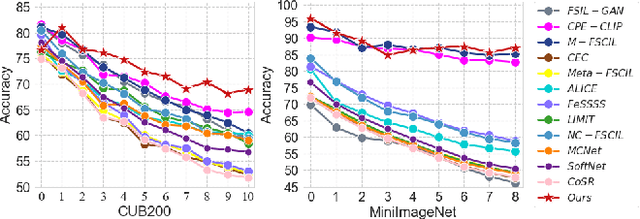
Open-world continual learning (OWCL) adapts to sequential tasks with open samples, learning knowledge incrementally while preventing forgetting. However, existing OWCL still requires a large amount of labeled data for training, which is often impractical in real-world applications. Given that new categories/entities typically come with limited annotations and are in small quantities, a more realistic situation is OWCL with scarce labeled data, i.e., few-shot training samples. Hence, this paper investigates the problem of open-world few-shot continual learning (OFCL), challenging in (i) learning unbounded tasks without forgetting previous knowledge and avoiding overfitting, (ii) constructing compact decision boundaries for open detection with limited labeled data, and (iii) transferring knowledge about knowns and unknowns and even update the unknowns to knowns once the labels of open samples are learned. In response, we propose a novel OFCL framework that integrates three key components: (1) an instance-wise token augmentation (ITA) that represents and enriches sample representations with additional knowledge, (2) a margin-based open boundary (MOB) that supports open detection with new tasks emerge over time, and (3) an adaptive knowledge space (AKS) that endows unknowns with knowledge for the updating from unknowns to knowns. Finally, extensive experiments show the proposed OFCL framework outperforms all baselines remarkably with practical importance and reproducibility. The source code is released at https://github.com/liyj1201/OFCL.
Order-Robust Class Incremental Learning: Graph-Driven Dynamic Similarity Grouping
Feb 27, 2025Class Incremental Learning (CIL) requires a model to continuously learn new classes without forgetting previously learned ones. While recent studies have significantly alleviated the problem of catastrophic forgetting (CF), more and more research reveals that the order in which classes appear have significant influences on CIL models. Specifically, prioritizing the learning of classes with lower similarity will enhance the model's generalization performance and its ability to mitigate forgetting. Hence, it is imperative to develop an order-robust class incremental learning model that maintains stable performance even when faced with varying levels of class similarity in different orders. In response, we first provide additional theoretical analysis, which reveals that when the similarity among a group of classes is lower, the model demonstrates increased robustness to the class order. Then, we introduce a novel \textbf{G}raph-\textbf{D}riven \textbf{D}ynamic \textbf{S}imilarity \textbf{G}rouping (\textbf{GDDSG}) method, which leverages a graph coloring algorithm for class-based similarity grouping. The proposed approach trains independent CIL models for each group of classes, ultimately combining these models to facilitate joint prediction. Experimental results demonstrate that our method effectively addresses the issue of class order sensitivity while achieving optimal performance in both model accuracy and anti-forgetting capability. Our code is available at https://github.com/AIGNLAI/GDDSG.