 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Conversational Inertia in Multi-Turn Agents
Feb 03, 2026Large language models excel as few-shot learners when provided with appropriate demonstrations, yet this strength becomes problematic in multiturn agent scenarios, where LLMs erroneously mimic their own previous responses as few-shot examples. Through attention analysis, we identify conversational inertia, a phenomenon where models exhibit strong diagonal attention to previous responses, which is associated with imitation bias that constrains exploration. This reveals a tension when transforming few-shot LLMs into agents: longer context enriches environmental feedback for exploitation, yet also amplifies conversational inertia that undermines exploration. Our key insight is that for identical states, actions generated with longer contexts exhibit stronger inertia than those with shorter contexts, enabling construction of preference pairs without environment rewards. Based on this, we propose Context Preference Learning to calibrate model preferences to favor low-inertia responses over highinertia ones. We further provide context management strategies at inference time to balance exploration and exploitation. Experimental results across eight agentic environments and one deep research scenario validate that our framework reduces conversational inertia and achieves performance improvements.
A Technical Study into Small Reasoning Language Models
Jun 16, 2025The ongoing evolution of language models has led to the development of large-scale architectures that demonstrate exceptional performance across a wide range of tasks. However, these models come with significant computational and energy demands, as well as potential privacy implications. In this context, Small Reasoning Language Models (SRLMs) with approximately 0.5 billion parameters present a compelling alternative due to their remarkable computational efficiency and cost effectiveness, particularly in resource-constrained environments. Despite these advantages, the limited capacity of 0.5 billion parameter models poses challenges in handling complex tasks such as mathematical reasoning and code generation. This research investigates various training strategies, including supervised fine-tuning (SFT), knowledge distillation (KD), and reinforcement learning (RL), as well as their hybrid implementations, to enhance the performance of 0.5B SRLMs. We analyze effective methodologies to bridge the performance gap between SRLMS and larger models and present insights into optimal training pipelines tailored for these smaller architectures. Through extensive experimental validation and analysis, our work aims to provide actionable recommendations for maximizing the reasoning capabilities of 0.5B models.
HeteroSpec: Leveraging Contextual Heterogeneity for Efficient Speculative Decoding
May 19, 2025Autoregressive decoding, the standard approach for Large Language Model (LLM) inference, remains a significant bottleneck due to its sequential nature. While speculative decoding algorithms mitigate this inefficiency through parallel verification, they fail to exploit the inherent heterogeneity in linguistic complexity, a key factor leading to suboptimal resource allocation. We address this by proposing HeteroSpec, a heterogeneity-adaptive speculative decoding framework that dynamically optimizes computational resource allocation based on linguistic context complexity. HeteroSpec introduces two key mechanisms: (1) A novel cumulative meta-path Top-$K$ entropy metric for efficiently identifying predictable contexts. (2) A dynamic resource allocation strategy based on data-driven entropy partitioning, enabling adaptive speculative expansion and pruning tailored to local context difficulty. Evaluated on five public benchmarks and four models, HeteroSpec achieves an average speedup of 4.26$\times$. It consistently outperforms state-of-the-art EAGLE-3 across speedup rates, average acceptance length, and verification cost. Notably, HeteroSpec requires no draft model retraining, incurs minimal overhead, and is orthogonal to other acceleration techniques. It demonstrates enhanced acceleration with stronger draft models, establishing a new paradigm for context-aware LLM inference acceleration.
Mask-Enhanced Autoregressive Prediction: Pay Less Attention to Learn More
Feb 11, 2025



Large Language Models (LLMs) are discovered to suffer from accurately retrieving key information. To address this, we propose Mask-Enhanced Autoregressive Prediction (MEAP), a simple yet effective training paradigm that seamlessly integrates Masked Language Modeling (MLM) into Next-Token Prediction (NTP) to enhance the latter's in-context retrieval capabilities. Specifically, MEAP first randomly masks a small fraction of input tokens and then directly performs the standard next-token prediction autoregressive using a decoder-only Transformer. MEAP eliminates the need for bidirectional attention or encoder-decoder architectures for MLM, incurring no additional computational overhead during pre-training or inference. Intensive experiments demonstrate that MEAP substantially outperforms NTP on key information retrieval and long-context reasoning tasks, while performing on par or better on commonsense reasoning tasks. The benefits of MEAP also extend to supervised fine-tuning, where it shows remarkable advantages in lost-in-the-middle scenarios, outperforming NTP by 11.77 percentage points. Our analysis indicates that MEAP's effectiveness arises from its ability to promote more distinguishable attention scores by concentrating on a reduced set of non-masked tokens. This mechanism improves the model's focus on task-relevant signals while mitigating the influence of peripheral context. These findings position MEAP as a promising training paradigm for large language models.
Hype-Adjusted Probability Measure for NLP Volatility Forecasting
Dec 10, 2024



This manuscript introduces the hype-adjusted probability measure developed in the context of a new Natural Language Processing (NLP) approach for market forecasting. A novel sentiment score equation is presented to capture component and memory effects and assign dynamic parameters, enhancing the impact of intraday news data on forecasting next-period volatility for selected U.S. semiconductor stocks. This approach integrates machine learning techniques to analyze and improve the predictive value of news. Building on the research of Geman's, this work improves forecast accuracy by assigning specific weights to each component of news sources and individual stocks in the portfolio, evaluating time-memory effects on market reactions, and incorporating shifts in sentiment direction. Finally, we propose the Hype-Adjusted Probability Measure, proving its existence and uniqueness, and discuss its theoretical applications in finance for NLP-based volatility forecasting, outlining future research pathways inspired by its concepts.
DynamicTrack: Advancing Gigapixel Tracking in Crowded Scenes
Jul 26, 2024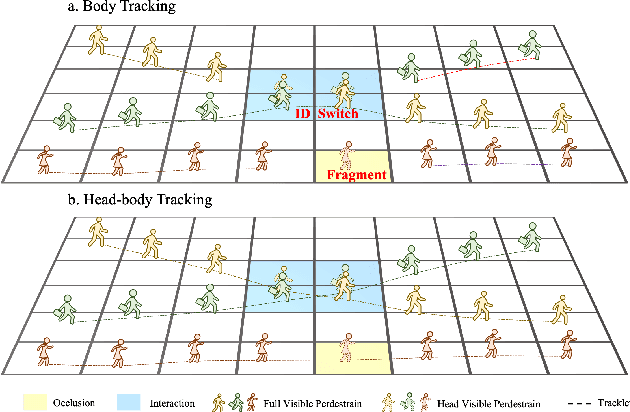
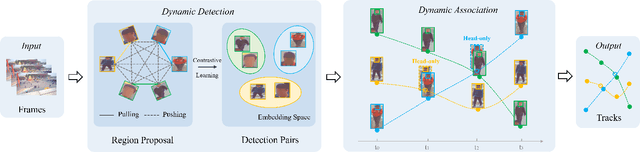
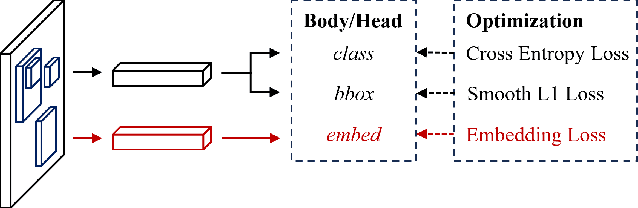

Tracking in gigapixel scenarios holds numerous potential applications in video surveillance and pedestrian analysis. Existing algorithms attempt to perform tracking in crowded scenes by utilizing multiple cameras or group relationships. However, their performance significantly degrades when confronted with complex interaction and occlusion inherent in gigapixel images. In this paper, we introduce DynamicTrack, a dynamic tracking framework designed to address gigapixel tracking challenges in crowded scenes. In particular, we propose a dynamic detector that utilizes contrastive learning to jointly detect the head and body of pedestrians. Building upon this, we design a dynamic association algorithm that effectively utilizes head and body information for matching purposes. Extensive experiments show that our tracker achieves state-of-the-art performance on widely used tracking benchmarks specifically designed for gigapixel crowded scenes.
URLBERT:A Contrastive and Adversarial Pre-trained Model for URL Classification
Feb 18, 2024URLs play a crucial role in understanding and categorizing web content, particularly in tasks related to security control and online recommendations. While pre-trained models are currently dominating various fields, the domain of URL analysis still lacks specialized pre-trained models. To address this gap, this paper introduces URLBERT, the first pre-trained representation learning model applied to a variety of URL classification or detection tasks. We first train a URL tokenizer on a corpus of billions of URLs to address URL data tokenization. Additionally, we propose two novel pre-training tasks: (1) self-supervised contrastive learning tasks, which strengthen the model's understanding of URL structure and the capture of category differences by distinguishing different variants of the same URL; (2) virtual adversarial training, aimed at improving the model's robustness in extracting semantic features from URLs. Finally, our proposed methods are evaluated on tasks including phishing URL detection, web page classification, and ad filtering, achieving state-of-the-art performance. Importantly, we also explore multi-task learning with URLBERT, and experimental results demonstrate that multi-task learning model based on URLBERT exhibit equivalent effectiveness compared to independently fine-tuned models, showing the simplicity of URLBERT in handling complex task requirements. The code for our work is available at https://github.com/Davidup1/URLBERT.
Optimizing Stock Option Forecasting with the Assembly of Machine Learning Models and Improved Trading Strategies
Nov 29, 2022This paper introduced key aspects of applying Machine Learning (ML) models, improved trading strategies, and the Quasi-Reversibility Method (QRM) to optimize stock option forecasting and trading results. It presented the findings of the follow-up project of the research "Application of Convolutional Neural Networks with Quasi-Reversibility Method Results for Option Forecasting". First, the project included an application of Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM) networks to provide a novel way of predicting stock option trends. Additionally, it examined the dependence of the ML models by evaluating the experimental method of combining multiple ML models to improve prediction results and decision-making. Lastly, two improved trading strategies and simulated investing results were presented. The Binomial Asset Pricing Model with discrete time stochastic process analysis and portfolio hedging was applied and suggested an optimized investment expectation. These results can be utilized in real-life trading strategies to optimize stock option investment results based on historical data.
CGoDial: A Large-Scale Benchmark for Chinese Goal-oriented Dialog Evaluation
Nov 21, 2022Practical dialog systems need to deal with various knowledge sources, noisy user expressions, and the shortage of annotated data. To better solve the above problems, we propose CGoDial, new challenging and comprehensive Chinese benchmark for multi-domain Goal-oriented Dialog evaluation. It contains 96,763 dialog sessions and 574,949 dialog turns totally, covering three datasets with different knowledge sources: 1) a slot-based dialog (SBD) dataset with table-formed knowledge, 2) a flow-based dialog (FBD) dataset with tree-formed knowledge, and a retrieval-based dialog (RBD) dataset with candidate-formed knowledge. To bridge the gap between academic benchmarks and spoken dialog scenarios, we either collect data from real conversations or add spoken features to existing datasets via crowd-sourcing. The proposed experimental settings include the combinations of training with either the entire training set or a few-shot training set, and testing with either the standard test set or a hard test subset, which can assess model capabilities in terms of general prediction, fast adaptability and reliable robustness.
Lightweight Neural Network with Knowledge Distillation for CSI Feedback
Oct 31, 2022



Deep learning-based autoencoder has shown considerable potential in channel state information (CSI) feedback. However, the excellent feedback performance achieved by autoencoder is at the expense of a high computational complexity. In this paper, a knowledge distillation-based neural network lightweight strategy is introduced to deep learning-based CSI feedback to reduce the computational requirement. The key idea is to transfer the dark knowledge learned by a complicated teacher network to a lightweight student network, thereby improving the performance of the student network. First, an autoencoder distillation method is proposed by forcing the student autoencoder to mimic the output of the teacher autoencoder. Then, given the more limited computational power at the user equipment, an encoder distillation method is proposed where distillation is only performed to student encoder at the user equipment and the teacher decoder is directly used at the base stataion. The numerical simulation results show that the performance of student autoencoder can be considerably improved after knowledge distillation and encoder distillation can further improve the feedback performance and reduce the complexity.