 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafetyALFRED: Evaluating Safety-Conscious Planning of Multimodal Large Language Models
Apr 21, 2026Multimodal Large Language Models are increasingly adopted as autonomous agents in interactive environments, yet their ability to proactively address safety hazards remains insufficient. We introduce SafetyALFRED, built upon the embodied agent benchmark ALFRED, augmented with six categories of real-world kitchen hazards. While existing safety evaluations focus on hazard recognition through disembodied question answering (QA) settings, we evaluate eleven state-of-the-art models from the Qwen, Gemma, and Gemini families on not only hazard recognition, but also active risk mitigation through embodied planning. Our experimental results reveal a significant alignment gap: while models can accurately recognize hazards in QA settings, average mitigation success rates for these hazards are low in comparison. Our findings demonstrate that static evaluations through QA are insufficient for physical safety, thus we advocate for a paradigm shift toward benchmarks that prioritize corrective actions in embodied contexts. We open-source our code and dataset under https://github.com/sled-group/SafetyALFRED.git
RoboMME: Benchmarking and Understanding Memory for Robotic Generalist Policies
Mar 04, 2026Memory is critical for long-horizon and history-dependent robotic manipulation. Such tasks often involve counting repeated actions or manipulating objects that become temporarily occluded. Recent vision-language-action (VLA) models have begun to incorporate memory mechanisms; however, their evaluations remain confined to narrow, non-standardized settings. This limits their systematic understanding, comparison, and progress measurement. To address these challenges, we introduce RoboMME: a large-scale standardized benchmark for evaluating and advancing VLA models in long-horizon, history-dependent scenarios. Our benchmark comprises 16 manipulation tasks constructed under a carefully designed taxonomy that evaluates temporal, spatial, object, and procedural memory. We further develop a suite of 14 memory-augmented VLA variants built on the π0.5 backbone to systematically explore different memory representations across multiple integration strategies. Experimental results show that the effectiveness of memory representations is highly task-dependent, with each design offering distinct advantages and limitations across different tasks. Videos and code can be found at our website https://robomme.github.io.
AimBot: A Simple Auxiliary Visual Cue to Enhance Spatial Awareness of Visuomotor Policies
Aug 11, 2025In this paper, we propose AimBot, a lightweight visual augmentation technique that provides explicit spatial cues to improve visuomotor policy learning in robotic manipulation. AimBot overlays shooting lines and scope reticles onto multi-view RGB images, offering auxiliary visual guidance that encodes the end-effector's state. The overlays are computed from depth images, camera extrinsics, and the current end-effector pose, explicitly conveying spatial relationships between the gripper and objects in the scene. AimBot incurs minimal computational overhead (less than 1 ms) and requires no changes to model architectures, as it simply replaces original RGB images with augmented counterparts. Despite its simplicity, our results show that AimBot consistently improves the performance of various visuomotor policies in both simulation and real-world settings, highlighting the benefits of spatially grounded visual feedback.
Training Turn-by-Turn Verifiers for Dialogue Tutoring Agents: The Curious Case of LLMs as Your Coding Tutors
Feb 18, 2025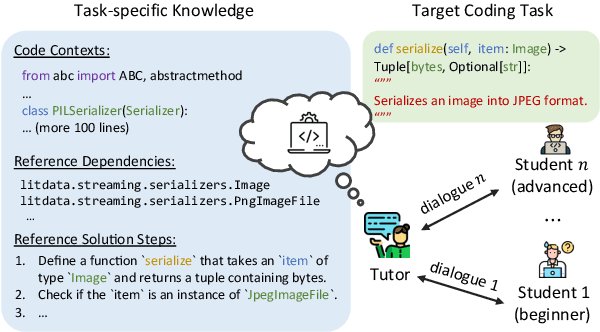
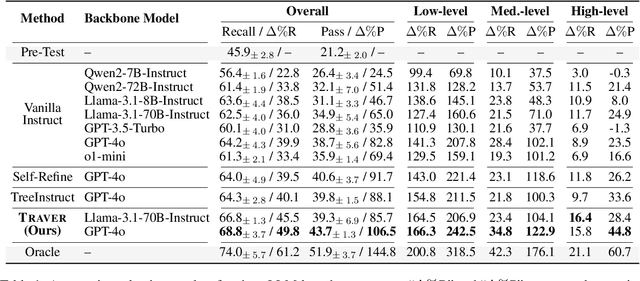
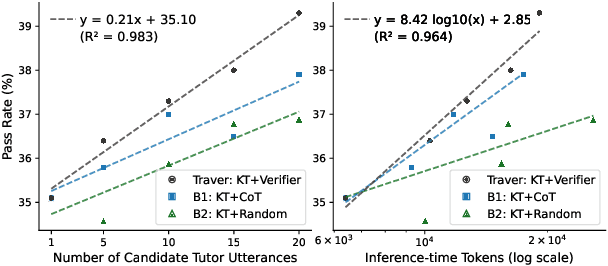

Intelligent tutoring agents powered by large language models (LLMs) have been increasingly explored to deliver personalized guidance in areas such as language learning and science education. However, their capabilities in guiding users to solve complex real-world tasks remain underexplored. To address this limitation, in this work, we focus on coding tutoring, a challenging problem that requires tutors to proactively guide students toward completing predefined coding tasks. We propose a novel agent workflow, Trace-and-Verify (TRAVER), which combines knowledge tracing to estimate a student's knowledge state and turn-by-turn verification to ensure effective guidance toward task completion. We introduce DICT, an automatic evaluation protocol that assesses tutor agents holistically using controlled student simulation and code generation tests. Extensive experiments reveal the challenges of coding tutoring and demonstrate that TRAVER achieves a significantly higher success rate. Although we use code tutoring as an example in this paper, our results and findings can be extended beyond coding, providing valuable insights into advancing tutoring agents for a variety of tasks.
Teaching Embodied Reinforcement Learning Agents: Informativeness and Diversity of Language Use
Oct 31, 2024In real-world scenarios, it is desirable for embodied agents to have the ability to leverage human language to gain explicit or implicit knowledge for learning tasks. Despite recent progress, most previous approaches adopt simple low-level instructions as language inputs, which may not reflect natural human communication. It's not clear how to incorporate rich language use to facilitate task learning. To address this question, this paper studies different types of language inputs in facilitating reinforcement learning (RL) embodied agents. More specifically, we examine how different levels of language informativeness (i.e., feedback on past behaviors and future guidance) and diversity (i.e., variation of language expressions) impact agent learning and inference. Our empirical results based on four RL benchmarks demonstrate that agents trained with diverse and informative language feedback can achieve enhanced generalization and fast adaptation to new tasks. These findings highlight the pivotal role of language use in teaching embodied agents new tasks in an open world. Project website: https://github.com/sled-group/Teachable_RL
Think, Act, and Ask: Open-World Interactive Personalized Robot Navigation
Oct 12, 2023Zero-Shot Object Navigation (ZSON) enables agents to navigate towards open-vocabulary objects in unknown environments. The existing works of ZSON mainly focus on following individual instructions to find generic object classes, neglecting the utilization of natural language interaction and the complexities of identifying user-specific objects. To address these limitations, we introduce Zero-shot Interactive Personalized Object Navigation (ZIPON), where robots need to navigate to personalized goal objects while engaging in conversations with users. To solve ZIPON, we propose a new framework termed Open-woRld Interactive persOnalized Navigation (ORION), which uses Large Language Models (LLMs) to make sequential decisions to manipulate different modules for perception, navigation and communication. Experimental results show that the performance of interactive agents that can leverage user feedback exhibits significant improvement. However, obtaining a good balance between task completion and the efficiency of navigation and interaction remains challenging for all methods. We further provide more findings on the impact of diverse user feedback forms on the agents' performance.
SpokenWOZ: A Large-Scale Speech-Text Benchmark for Spoken Task-Oriented Dialogue in Multiple Domains
May 22, 2023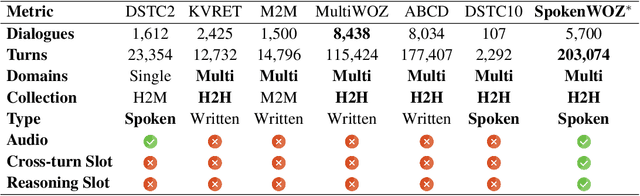
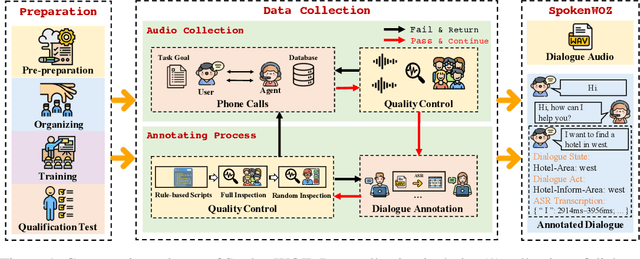

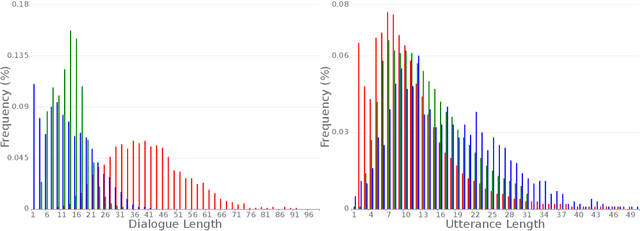
Task-oriented dialogue (TOD) models have great progress in the past few years. However, these studies primarily focus on datasets written by annotators, which has resulted in a gap between academic research and more realistic spoken conversation scenarios. While a few small-scale spoken TOD datasets are proposed to address robustness issues, e.g., ASR errors, they fail to identify the unique challenges in spoken conversation. To tackle the limitations, we introduce SpokenWOZ, a large-scale speech-text dataset for spoken TOD, which consists of 8 domains, 203k turns, 5.7k dialogues and 249 hours of audios from human-to-human spoken conversations. SpokenWOZ incorporates common spoken characteristics such as word-by-word processing and commonsense reasoning. We also present cross-turn slot and reasoning slot detection as new challenges based on the spoken linguistic phenomena. We conduct comprehensive experiments on various models, including text-modal baselines, newly proposed dual-modal baselines and LLMs. The results show the current models still has substantial areas for improvement in spoken conversation, including fine-tuned models and LLMs, i.e., ChatGPT.
CGoDial: A Large-Scale Benchmark for Chinese Goal-oriented Dialog Evaluation
Nov 21, 2022Practical dialog systems need to deal with various knowledge sources, noisy user expressions, and the shortage of annotated data. To better solve the above problems, we propose CGoDial, new challenging and comprehensive Chinese benchmark for multi-domain Goal-oriented Dialog evaluation. It contains 96,763 dialog sessions and 574,949 dialog turns totally, covering three datasets with different knowledge sources: 1) a slot-based dialog (SBD) dataset with table-formed knowledge, 2) a flow-based dialog (FBD) dataset with tree-formed knowledge, and a retrieval-based dialog (RBD) dataset with candidate-formed knowledge. To bridge the gap between academic benchmarks and spoken dialog scenarios, we either collect data from real conversations or add spoken features to existing datasets via crowd-sourcing. The proposed experimental settings include the combinations of training with either the entire training set or a few-shot training set, and testing with either the standard test set or a hard test subset, which can assess model capabilities in terms of general prediction, fast adaptability and reliable robustness.
SPACE-3: Unified Dialog Model Pre-training for Task-Oriented Dialog Understanding and Generation
Sep 14, 2022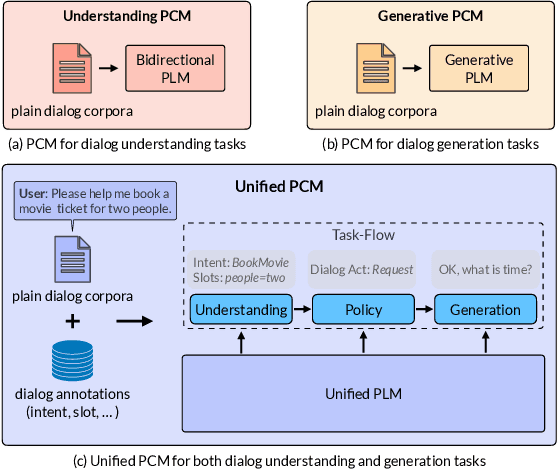
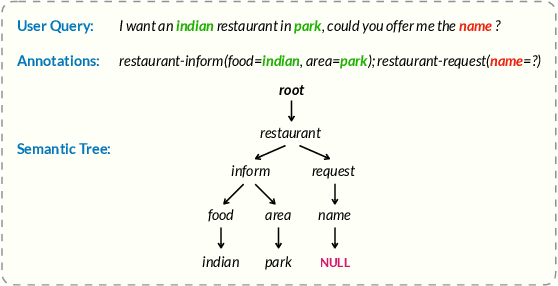
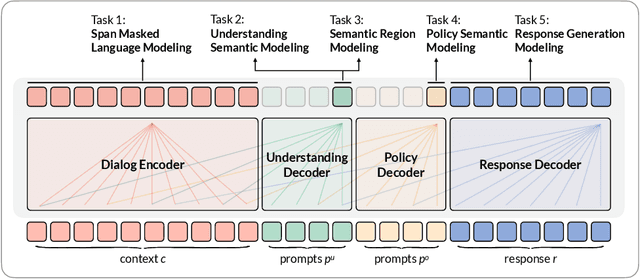
Recently, pre-training methods have shown remarkable success in task-oriented dialog (TOD) systems. However, most existing pre-trained models for TOD focus on either dialog understanding or dialog generation, but not both. In this paper, we propose SPACE-3, a novel unified semi-supervised pre-trained conversation model learning from large-scale dialog corpora with limited annotations, which can be effectively fine-tuned on a wide range of downstream dialog tasks. Specifically, SPACE-3 consists of four successive components in a single transformer to maintain a task-flow in TOD systems: (i) a dialog encoding module to encode dialog history, (ii) a dialog understanding module to extract semantic vectors from either user queries or system responses, (iii) a dialog policy module to generate a policy vector that contains high-level semantics of the response, and (iv) a dialog generation module to produce appropriate responses. We design a dedicated pre-training objective for each component. Concretely, we pre-train the dialog encoding module with span mask language modeling to learn contextualized dialog information. To capture the structured dialog semantics, we pre-train the dialog understanding module via a novel tree-induced semi-supervised contrastive learning objective with the help of extra dialog annotations. In addition, we pre-train the dialog policy module by minimizing the L2 distance between its output policy vector and the semantic vector of the response for policy optimization. Finally, the dialog generation model is pre-trained by language modeling. Results show that SPACE-3 achieves state-of-the-art performance on eight downstream dialog benchmarks, including intent prediction, dialog state tracking, and end-to-end dialog modeling. We also show that SPACE-3 has a stronger few-shot ability than existing models under the low-resource setting.
SPACE-2: Tree-Structured Semi-Supervised Contrastive Pre-training for Task-Oriented Dialog Understanding
Sep 14, 2022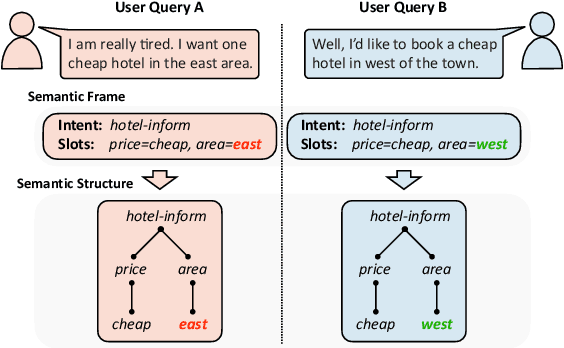
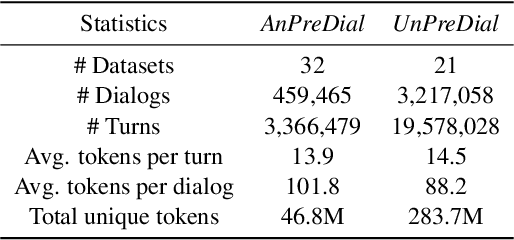
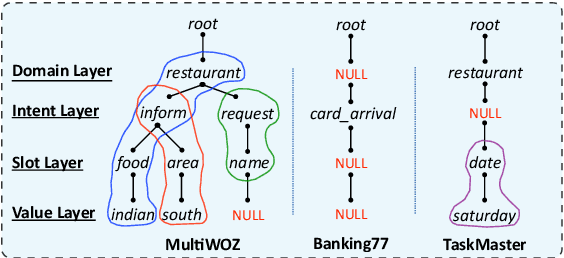
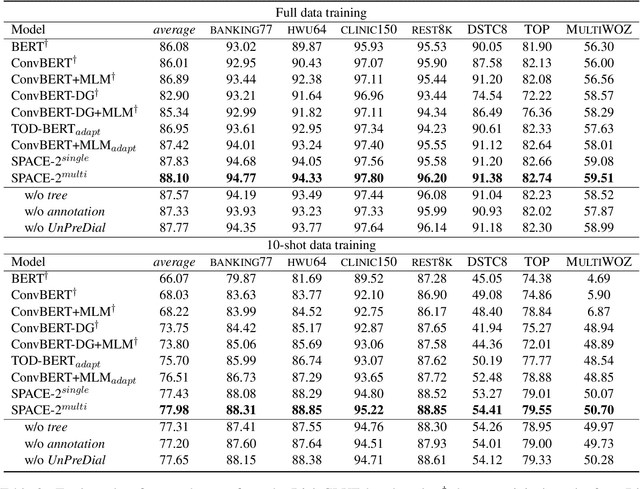
Pre-training methods with contrastive learning objectives have shown remarkable success in dialog understanding tasks. However, current contrastive learning solely considers the self-augmented dialog samples as positive samples and treats all other dialog samples as negative ones, which enforces dissimilar representations even for dialogs that are semantically related. In this paper, we propose SPACE-2, a tree-structured pre-trained conversation model, which learns dialog representations from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised contrastive pre-training. Concretely, we first define a general semantic tree structure (STS) to unify the inconsistent annotation schema across different dialog datasets, so that the rich structural information stored in all labeled data can be exploited. Then we propose a novel multi-view score function to increase the relevance of all possible dialogs that share similar STSs and only push away other completely different dialogs during supervised contrastive pre-training. To fully exploit unlabeled dialogs, a basic self-supervised contrastive loss is also added to refine the learned representations. Experiments show that our method can achieve new state-of-the-art results on the DialoGLUE benchmark consisting of seven datasets and four popular dialog understanding tasks. For reproducibility, we release the code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/space-2.