 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Dialogue Systems and User Simulators
Jul 25, 2021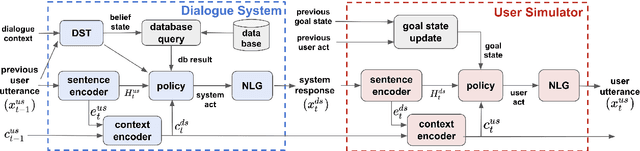
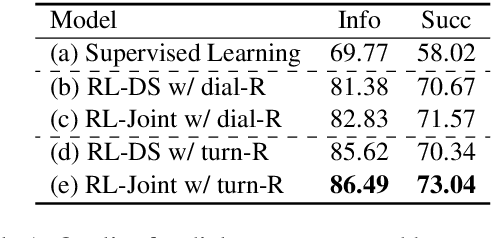
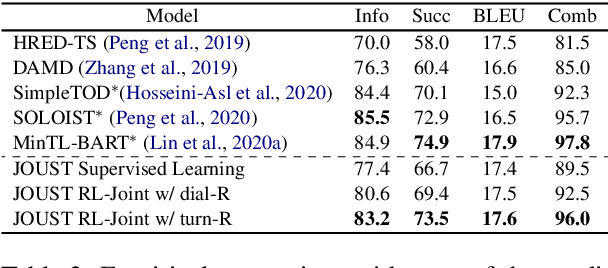
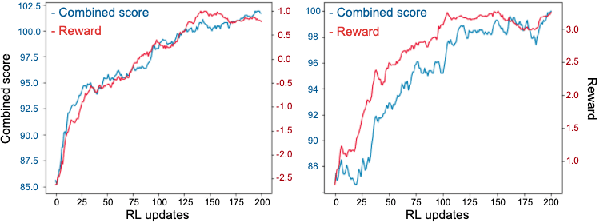
One of the difficulties in training dialogue systems is the lack of training data. We explore the possibility of creating dialogue data through the interaction between a dialogue system and a user simulator. Our goal is to develop a modelling framework that can incorporate new dialogue scenarios through self-play between the two agents. In this framework, we first pre-train the two agents on a collection of source domain dialogues, which equips the agents to converse with each other via natural language. With further fine-tuning on a small amount of target domain data, the agents continue to interact with the aim of improving their behaviors using reinforcement learning with structured reward functions. In experiments on the MultiWOZ dataset, two practical transfer learning problems are investigated: 1) domain adaptation and 2) single-to-multiple domain transfer. We demonstrate that the proposed framework is highly effective in bootstrapping the performance of the two agents in transfer learning. We also show that our method leads to improvements in dialogue system performance on complete datasets.
Variational Cross-domain Natural Language Generation for Spoken Dialogue Systems
Dec 20, 2018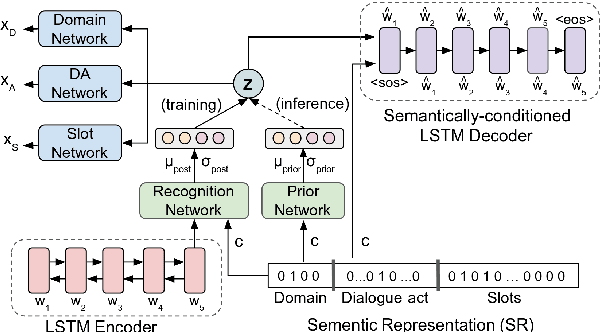

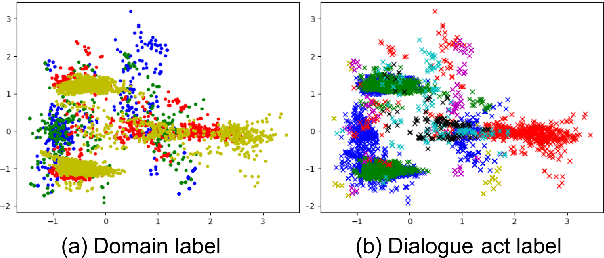
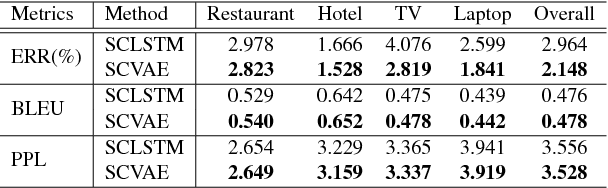
Cross-domain natural language generation (NLG) is still a difficult task within spoken dialogue modelling. Given a semantic representation provided by the dialogue manager, the language generator should generate sentences that convey desired information. Traditional template-based generators can produce sentences with all necessary information, but these sentences are not sufficiently diverse. With RNN-based models, the diversity of the generated sentences can be high, however, in the process some information is lost. In this work, we improve an RNN-based generator by considering latent information at the sentence level during generation using the conditional variational autoencoder architecture. We demonstrate that our model outperforms the original RNN-based generator, while yielding highly diverse sentences. In addition, our model performs better when the training data is limited.
Neural User Simulation for Corpus-based Policy Optimisation for Spoken Dialogue Systems
May 17, 2018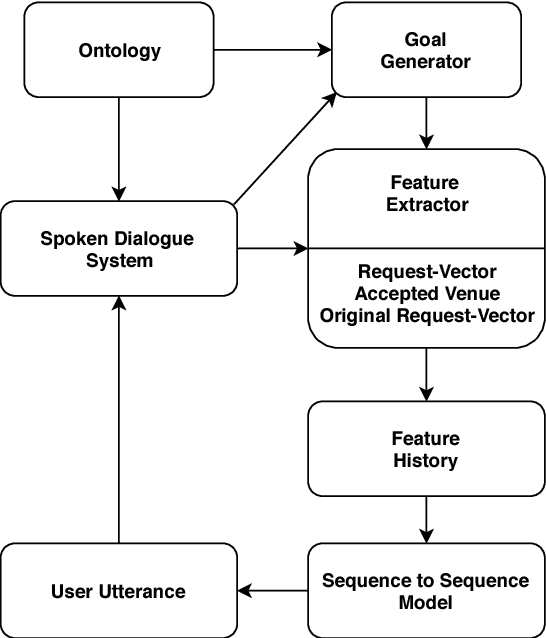

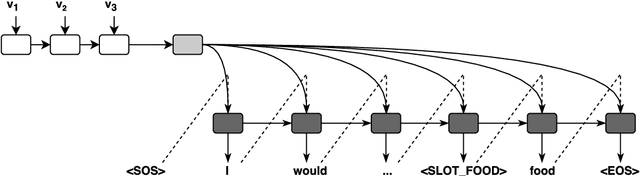
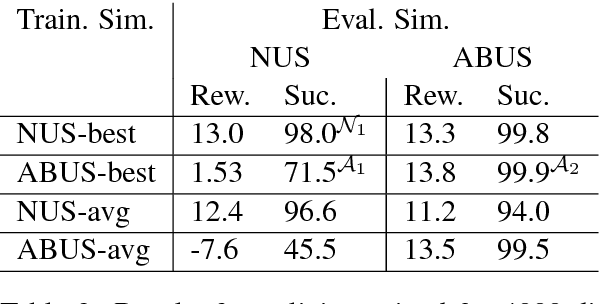
User Simulators are one of the major tools that enable offline training of task-oriented dialogue systems. For this task the Agenda-Based User Simulator (ABUS) is often used. The ABUS is based on hand-crafted rules and its output is in semantic form. Issues arise from both properties such as limited diversity and the inability to interface a text-level belief tracker. This paper introduces the Neural User Simulator (NUS) whose behaviour is learned from a corpus and which generates natural language, hence needing a less labelled dataset than simulators generating a semantic output. In comparison to much of the past work on this topic, which evaluates user simulators on corpus-based metrics, we use the NUS to train the policy of a reinforcement learning based Spoken Dialogue System. The NUS is compared to the ABUS by evaluating the policies that were trained using the simulators. Cross-model evaluation is performed i.e. training on one simulator and testing on the other. Furthermore, the trained policies are tested on real users. In both evaluation tasks the NUS outperformed the ABUS.
Improved TDNNs using Deep Kernels and Frequency Dependent Grid-RNNs
Feb 20, 2018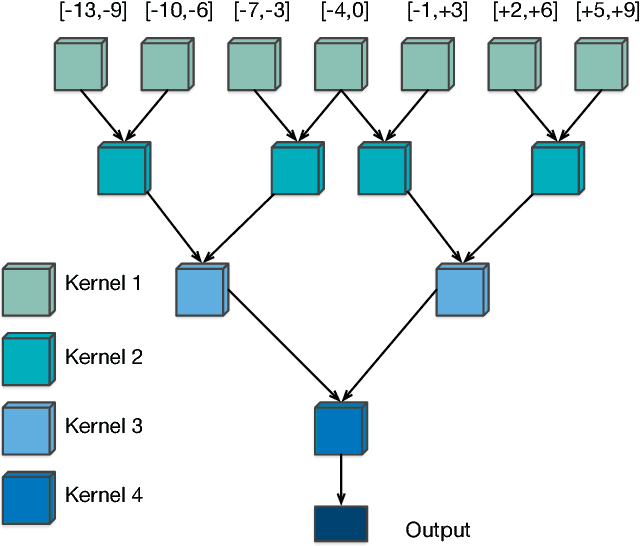
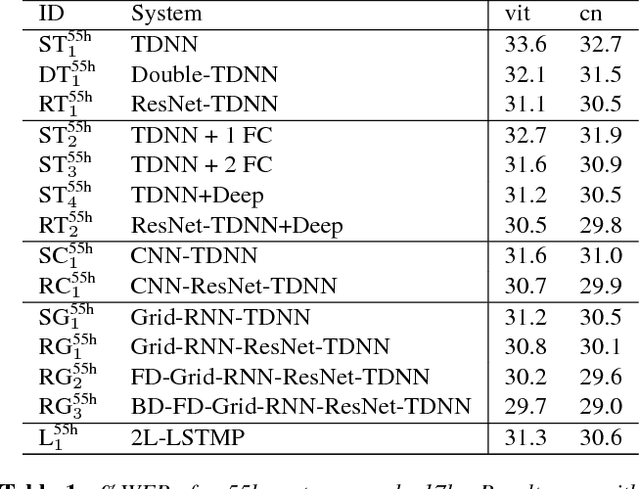


Time delay neural networks (TDNNs) are an effective acoustic model for large vocabulary speech recognition. The strength of the model can be attributed to its ability to effectively model long temporal contexts. However, current TDNN models are relatively shallow, which limits the modelling capability. This paper proposes a method of increasing the network depth by deepening the kernel used in the TDNN temporal convolutions. The best performing kernel consists of three fully connected layers with a residual (ResNet) connection from the output of the first to the output of the third. The addition of spectro-temporal processing as the input to the TDNN in the form of a convolutional neural network (CNN) and a newly designed Grid-RNN was investigated. The Grid-RNN strongly outperforms a CNN if different sets of parameters for different frequency bands are used and can be further enhanced by using a bi-directional Grid-RNN. Experiments using the multi-genre broadcast (MGB3) English data (275h) show that deep kernel TDNNs reduces the word error rate (WER) by 6% relative and when combined with the frequency dependent Grid-RNN gives a relative WER reduction of 9%.