 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved and Efficient Conversational Slot Labeling through Question Answering
Apr 05, 2022
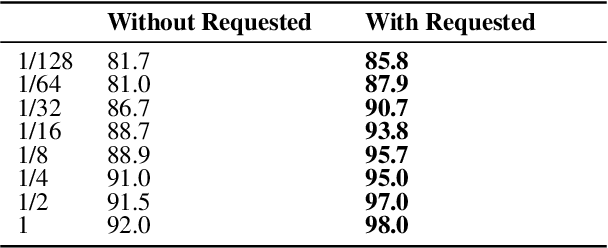
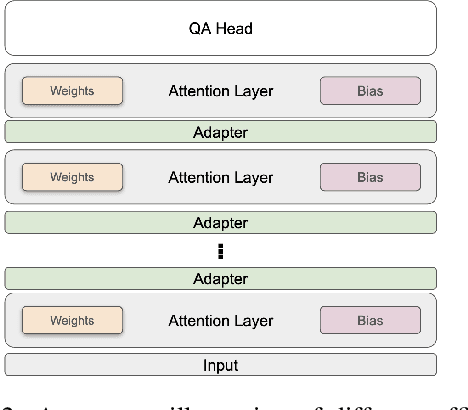
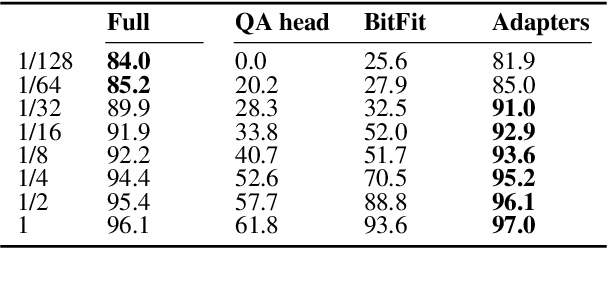
Transformer-based pretrained language models (PLMs) offer unmatched performance across the majority of natural language understanding (NLU) tasks, including a body of question answering (QA) tasks. We hypothesize that improvements in QA methodology can also be directly exploited in dialog NLU; however, dialog tasks must be \textit{reformatted} into QA tasks. In particular, we focus on modeling and studying \textit{slot labeling} (SL), a crucial component of NLU for dialog, through the QA optics, aiming to improve both its performance and efficiency, and make it more effective and resilient to working with limited task data. To this end, we make a series of contributions: 1) We demonstrate how QA-tuned PLMs can be applied to the SL task, reaching new state-of-the-art performance, with large gains especially pronounced in such low-data regimes. 2) We propose to leverage contextual information, required to tackle ambiguous values, simply through natural language. 3) Efficiency and compactness of QA-oriented fine-tuning are boosted through the use of lightweight yet effective adapter modules. 4) Trading-off some of the quality of QA datasets for their size, we experiment with larger automatically generated QA datasets for QA-tuning, arriving at even higher performance. Finally, our analysis suggests that our novel QA-based slot labeling models, supported by the PLMs, reach a performance ceiling in high-data regimes, calling for more challenging and more nuanced benchmarks in future work.
Variational Cross-domain Natural Language Generation for Spoken Dialogue Systems
Dec 20, 2018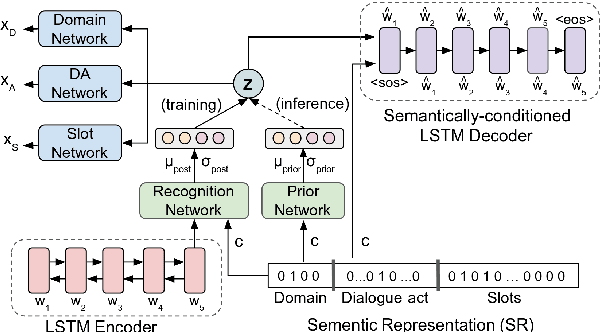

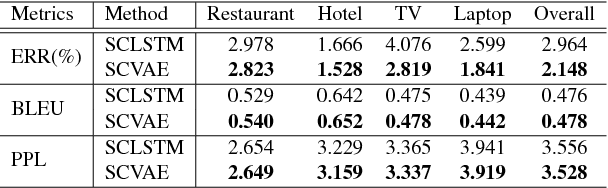
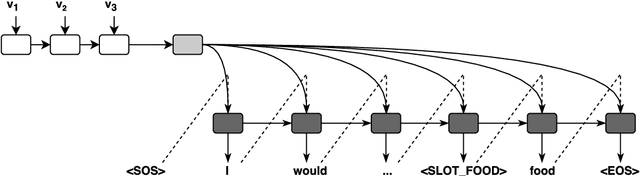
Cross-domain natural language generation (NLG) is still a difficult task within spoken dialogue modelling. Given a semantic representation provided by the dialogue manager, the language generator should generate sentences that convey desired information. Traditional template-based generators can produce sentences with all necessary information, but these sentences are not sufficiently diverse. With RNN-based models, the diversity of the generated sentences can be high, however, in the process some information is lost. In this work, we improve an RNN-based generator by considering latent information at the sentence level during generation using the conditional variational autoencoder architecture. We demonstrate that our model outperforms the original RNN-based generator, while yielding highly diverse sentences. In addition, our model performs better when the training data is limited.
Neural User Simulation for Corpus-based Policy Optimisation for Spoken Dialogue Systems
May 17, 2018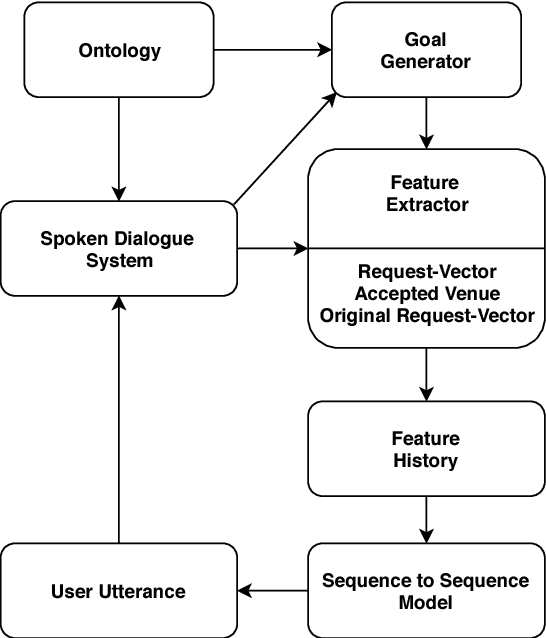

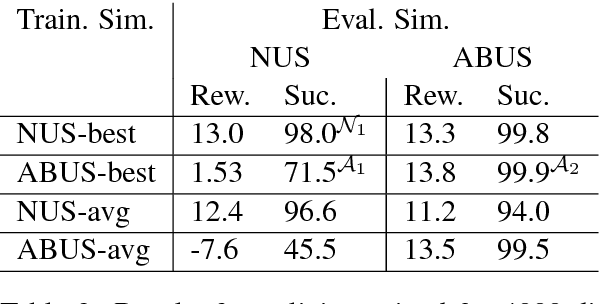
User Simulators are one of the major tools that enable offline training of task-oriented dialogue systems. For this task the Agenda-Based User Simulator (ABUS) is often used. The ABUS is based on hand-crafted rules and its output is in semantic form. Issues arise from both properties such as limited diversity and the inability to interface a text-level belief tracker. This paper introduces the Neural User Simulator (NUS) whose behaviour is learned from a corpus and which generates natural language, hence needing a less labelled dataset than simulators generating a semantic output. In comparison to much of the past work on this topic, which evaluates user simulators on corpus-based metrics, we use the NUS to train the policy of a reinforcement learning based Spoken Dialogue System. The NUS is compared to the ABUS by evaluating the policies that were trained using the simulators. Cross-model evaluation is performed i.e. training on one simulator and testing on the other. Furthermore, the trained policies are tested on real users. In both evaluation tasks the NUS outperformed the ABUS.