 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDial HEALTHDIAL for Advice: A Multilingual and Multi-Parallel Spoken Dialogue Dataset for Knowledge-Grounded Information Seeking
May 28, 2026Creating spoken dialogue datasets is methodologically challenging, and these challenges are amplified when the goal is to build multilingual, multi-parallel datasets at scale. This work introduces HEALTHDIAL, a large-scale, multilingual, and multi-parallel dataset for developing and evaluating retrieval-augmented generation (RAG)-based spoken dialogue systems. The dataset comprises 6,000 information-seeking dialogues (1,500 per language) grounded in trusted content from the World Health Organization (WHO) and 163 hours of user speech recorded from native speakers of diverse dialects across four official WHO languages: Arabic, Chinese, English, and Spanish. Each speaker is annotated with demographic (e.g., gender, age) and sociolinguistic (e.g., primary language, region of origin) variables. We report benchmark results across key dialogue tasks, which reveal consistent performance disparities across languages, even among high-resource ones. To support future research, we release the dataset, a prototype system, and a toolkit for data collection and system evaluation.
Polyglot Teachers: Evaluating Language Models for Multilingual Synthetic Data Generation
Apr 13, 2026Synthesizing supervised finetuning (SFT) data from language models (LMs) to teach smaller models multilingual tasks has become increasingly common. However, teacher model selection is often ad hoc, typically defaulting to the largest available option, even though such models may have significant capability gaps in non-English languages. This practice can result in poor-quality synthetic data and suboptimal student downstream performance. In this work, we systematically characterize what makes an effective multilingual teacher. We measure intrinsic measures of data quality with extrinsic student model performance in a metric we call Polyglot Score; evaluating 10 LMs across 6 typologically diverse languages, generating over 1.4M SFT examples and training 240 student models. Among the models tested, Gemma 3 27B and Aya Expanse 32B emerge as consistently effective teachers across different student base model families. Further analyses reveal that model scale alone does not significantly predict teacher effectiveness; instead, data qualities such as prompt diversity, length, and response fluency capture over 93.3% of variance in intrinsic data quality and predict student performance. Finally, we provide practical recommendations, including matching the model families of teacher-student pairs and translating from or responding to existing prompts, which can yield improvements for less-resourced languages. We hope that our work advances data-centric research in multilingual synthetic data and LM development.
Artificial intelligence is creating a new global linguistic hierarchy
Feb 12, 2026Artificial intelligence (AI) has the potential to transform healthcare, education, governance and socioeconomic equity, but its benefits remain concentrated in a small number of languages (Bender, 2019; Blasi et al., 2022; Joshi et al., 2020; Ranathunga and de Silva, 2022; Young, 2015). Language AI - the technologies that underpin widely-used conversational systems such as ChatGPT - could provide major benefits if available in people's native languages, yet most of the world's 7,000+ linguistic communities currently lack access and face persistent digital marginalization. Here we present a global longitudinal analysis of social, economic and infrastructural conditions across languages to assess systemic inequalities in language AI. We first analyze the existence of AI resources for 6003 languages. We find that despite efforts of the community to broaden the reach of language technologies (Bapna et al., 2022; Costa-Jussà et al., 2022), the dominance of a handful of languages is exacerbating disparities on an unprecedented scale, with divides widening exponentially rather than narrowing. Further, we contrast the longitudinal diffusion of AI with that of earlier IT technologies, revealing a distinctive hype-driven pattern of spread. To translate our findings into practical insights and guide prioritization efforts, we introduce the Language AI Readiness Index (EQUATE), which maps the state of technological, socio-economic, and infrastructural prerequisites for AI deployment across languages. The index highlights communities where capacity exists but remains underutilized, and provides a framework for accelerating more equitable diffusion of language AI. Our work contributes to setting the baseline for a transition towards more sustainable and equitable language technologies.
Modular Multi-Task Learning for Chemical Reaction Prediction
Feb 11, 2026Adapting large language models (LLMs) trained on broad organic chemistry to smaller, domain-specific reaction datasets is a key challenge in chemical and pharmaceutical R&D. Effective specialisation requires learning new reaction knowledge while preserving general chemical understanding across related tasks. Here, we evaluate Low-Rank Adaptation (LoRA) as a parameter-efficient alternative to full fine-tuning for organic reaction prediction on limited, complex datasets. Using USPTO reaction classes and challenging C-H functionalisation reactions, we benchmark forward reaction prediction, retrosynthesis and reagent prediction. LoRA achieves accuracy comparable to full fine-tuning while effectively mitigating catastrophic forgetting and better preserving multi-task performance. Both fine-tuning approaches generalise beyond training distributions, producing plausible alternative solvent predictions. Notably, C-H functionalisation fine-tuning reveals that LoRA and full fine-tuning encode subtly different reactivity patterns, suggesting more effective reaction-specific adaptation with LoRA. As LLMs continue to scale, our results highlight the practicality of modular, parameter-efficient fine-tuning strategies for their flexible deployment for chemistry applications.
LoRA-Squeeze: Simple and Effective Post-Tuning and In-Tuning Compression of LoRA Modules
Feb 11, 2026Despite its huge number of variants, standard Low-Rank Adaptation (LoRA) is still a dominant technique for parameter-efficient fine-tuning (PEFT). Nonetheless, it faces persistent challenges, including the pre-selection of an optimal rank and rank-specific hyper-parameters, as well as the deployment complexity of heterogeneous-rank modules and more sophisticated LoRA derivatives. In this work, we introduce LoRA-Squeeze, a simple and efficient methodology that aims to improve standard LoRA learning by changing LoRA module ranks either post-hoc or dynamically during training}. Our approach posits that it is better to first learn an expressive, higher-rank solution and then compress it, rather than learning a constrained, low-rank solution directly. The method involves fine-tuning with a deliberately high(er) source rank, reconstructing or efficiently approximating the reconstruction of the full weight update matrix, and then using Randomized Singular Value Decomposition (RSVD) to create a new, compressed LoRA module at a lower target rank. Extensive experiments across 13 text and 10 vision-language tasks show that post-hoc compression often produces lower-rank adapters that outperform those trained directly at the target rank, especially if a small number of fine-tuning steps at the target rank is allowed. Moreover, a gradual, in-tuning rank annealing variant of LoRA-Squeeze consistently achieves the best LoRA size-performance trade-off.
Thinking in Frames: How Visual Context and Test-Time Scaling Empower Video Reasoning
Jan 28, 2026Vision-Language Models have excelled at textual reasoning, but they often struggle with fine-grained spatial understanding and continuous action planning, failing to simulate the dynamics required for complex visual reasoning. In this work, we formulate visual reasoning by means of video generation models, positing that generated frames can act as intermediate reasoning steps between initial states and solutions. We evaluate their capacity in two distinct regimes: Maze Navigation for sequential discrete planning with low visual change and Tangram Puzzle for continuous manipulation with high visual change. Our experiments reveal three critical insights: (1) Robust Zero-Shot Generalization: In both tasks, the model demonstrates strong performance on unseen data distributions without specific finetuning. (2) Visual Context: The model effectively uses visual context as explicit control, such as agent icons and tangram shapes, enabling it to maintain high visual consistency and adapt its planning capability robustly to unseen patterns. (3) Visual Test-Time Scaling: We observe a test-time scaling law in sequential planning; increasing the generated video length (visual inference budget) empowers better zero-shot generalization to spatially and temporally complex paths. These findings suggest that video generation is not merely a media tool, but a scalable, generalizable paradigm for visual reasoning.
Value of Information: A Framework for Human-Agent Communication
Jan 10, 2026Large Language Model (LLM) agents deployed for real-world tasks face a fundamental dilemma: user requests are underspecified, yet agents must decide whether to act on incomplete information or interrupt users for clarification. Existing approaches either rely on brittle confidence thresholds that require task-specific tuning, or fail to account for the varying stakes of different decisions. We introduce a decision-theoretic framework that resolves this trade-off through the Value of Information (VoI), enabling agents to dynamically weigh the expected utility gain from asking questions against the cognitive cost imposed on users. Our inference-time method requires no hyperparameter tuning and adapts seamlessly across contexts-from casual games to medical diagnosis. Experiments across four diverse domains (20 Questions, medical diagnosis, flight booking, and e-commerce) show that VoI consistently matches or exceeds the best manually-tuned baselines, achieving up to 1.36 utility points higher in high-cost settings. This work provides a parameter-free framework for adaptive agent communication that explicitly balances task risk, query ambiguity, and user effort.
ReCoVeR the Target Language: Language Steering without Sacrificing Task Performance
Sep 18, 2025


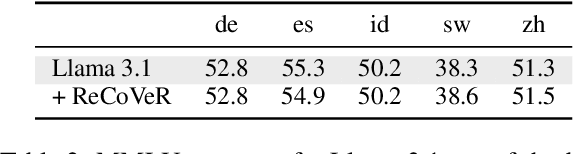
As they become increasingly multilingual, Large Language Models (LLMs) exhibit more language confusion, i.e., they tend to generate answers in a language different from the language of the prompt or the answer language explicitly requested by the user. In this work, we propose ReCoVeR (REducing language COnfusion in VEctor Representations), a novel lightweight approach for reducing language confusion based on language-specific steering vectors. We first isolate language vectors with the help of multi-parallel corpus and then effectively leverage those vectors for effective LLM steering via fixed (i.e., unsupervised) as well as trainable steering functions. Our extensive evaluation, encompassing three benchmarks and 18 languages, shows that ReCoVeR effectively mitigates language confusion in both monolingual and cross-lingual setups while at the same time -- and in contrast to prior language steering methods -- retaining task performance. Our data code is available at https://github.com/hSterz/recover.
11Plus-Bench: Demystifying Multimodal LLM Spatial Reasoning with Cognitive-Inspired Analysis
Aug 27, 2025For human cognitive process, spatial reasoning and perception are closely entangled, yet the nature of this interplay remains underexplored in the evaluation of multimodal large language models (MLLMs). While recent MLLM advancements show impressive performance on reasoning, their capacity for human-like spatial cognition remains an open question. In this work, we introduce a systematic evaluation framework to assess the spatial reasoning abilities of state-of-the-art MLLMs relative to human performance. Central to our work is 11Plus-Bench, a high-quality benchmark derived from realistic standardized spatial aptitude tests. 11Plus-Bench also features fine-grained expert annotations of both perceptual complexity and reasoning process, enabling detailed instance-level analysis of model behavior. Through extensive experiments across 14 MLLMs and human evaluation, we find that current MLLMs exhibit early signs of spatial cognition. Despite a large performance gap compared to humans, MLLMs' cognitive profiles resemble those of humans in that cognitive effort correlates strongly with reasoning-related complexity. However, instance-level performance in MLLMs remains largely random, whereas human correctness is highly predictable and shaped by abstract pattern complexity. These findings highlight both emerging capabilities and limitations in current MLLMs' spatial reasoning capabilities and provide actionable insights for advancing model design.
Quantifying Language Disparities in Multilingual Large Language Models
Aug 23, 2025Results reported in large-scale multilingual evaluations are often fragmented and confounded by factors such as target languages, differences in experimental setups, and model choices. We propose a framework that disentangles these confounding variables and introduces three interpretable metrics--the performance realisation ratio, its coefficient of variation, and language potential--enabling a finer-grained and more insightful quantification of actual performance disparities across both (i) models and (ii) languages. Through a case study of 13 model variants on 11 multilingual datasets, we demonstrate that our framework provides a more reliable measurement of model performance and language disparities, particularly for low-resource languages, which have so far proven challenging to evaluate. Importantly, our results reveal that higher overall model performance does not necessarily imply greater fairness across languages.