 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Large Language Models Generalize Procedures Across Representations?
Feb 03, 2026Large language models (LLMs) are trained and tested extensively on symbolic representations such as code and graphs, yet real-world user tasks are often specified in natural language. To what extent can LLMs generalize across these representations? Here, we approach this question by studying isomorphic tasks involving procedures represented in code, graphs, and natural language (e.g., scheduling steps in planning). We find that training LLMs with popular post-training methods on graphs or code data alone does not reliably generalize to corresponding natural language tasks, while training solely on natural language can lead to inefficient performance gains. To address this gap, we propose a two-stage data curriculum that first trains on symbolic, then natural language data. The curriculum substantially improves model performance across model families and tasks. Remarkably, a 1.5B Qwen model trained by our method can closely match zero-shot GPT-4o in naturalistic planning. Finally, our analysis suggests that successful cross-representation generalization can be interpreted as a form of generative analogy, which our curriculum effectively encourages.
Visual Planning: Let's Think Only with Images
May 16, 2025Recent advancements in Large Language Models (LLMs) and their multimodal extensions (MLLMs) have substantially enhanced machine reasoning across diverse tasks. However, these models predominantly rely on pure text as the medium for both expressing and structuring reasoning, even when visual information is present. In this work, we argue that language may not always be the most natural or effective modality for reasoning, particularly in tasks involving spatial and geometrical information. Motivated by this, we propose a new paradigm, Visual Planning, which enables planning through purely visual representations, independent of text. In this paradigm, planning is executed via sequences of images that encode step-by-step inference in the visual domain, akin to how humans sketch or visualize future actions. We introduce a novel reinforcement learning framework, Visual Planning via Reinforcement Learning (VPRL), empowered by GRPO for post-training large vision models, leading to substantial improvements in planning in a selection of representative visual navigation tasks, FrozenLake, Maze, and MiniBehavior. Our visual planning paradigm outperforms all other planning variants that conduct reasoning in the text-only space. Our results establish Visual Planning as a viable and promising alternative to language-based reasoning, opening new avenues for tasks that benefit from intuitive, image-based inference.
Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL
Apr 01, 2025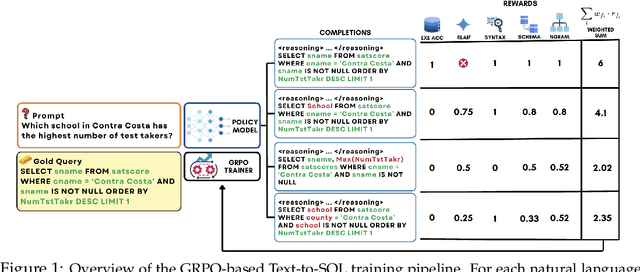
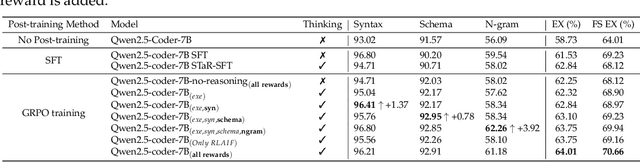
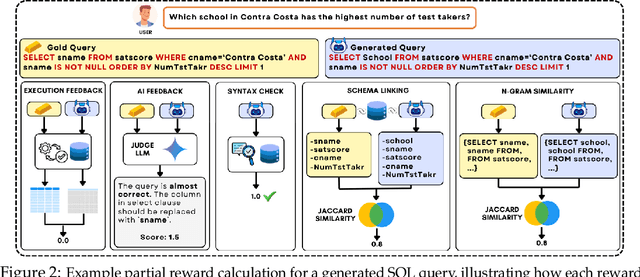
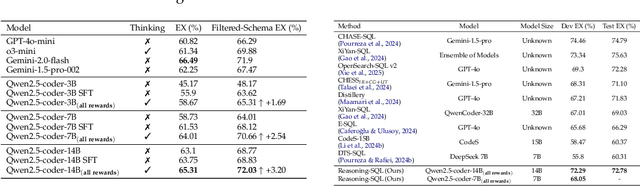
Text-to-SQL is a challenging task involving multiple reasoning-intensive subtasks, including natural language understanding, database schema comprehension, and precise SQL query formulation. Existing approaches often rely on handcrafted reasoning paths with inductive biases that can limit their overall effectiveness. Motivated by the recent success of reasoning-enhanced models such as DeepSeek R1 and OpenAI o1, which effectively leverage reward-driven self-exploration to enhance reasoning capabilities and generalization, we propose a novel set of partial rewards tailored specifically for the Text-to-SQL task. Our reward set includes schema-linking, AI feedback, n-gram similarity, and syntax check, explicitly designed to address the reward sparsity issue prevalent in reinforcement learning (RL). Leveraging group relative policy optimization (GRPO), our approach explicitly encourages large language models (LLMs) to develop intrinsic reasoning skills necessary for accurate SQL query generation. With models of different sizes, we demonstrate that RL-only training with our proposed rewards consistently achieves higher accuracy and superior generalization compared to supervised fine-tuning (SFT). Remarkably, our RL-trained 14B-parameter model significantly outperforms larger proprietary models, e.g. o3-mini by 4% and Gemini-1.5-Pro-002 by 3% on the BIRD benchmark. These highlight the efficacy of our proposed RL-training framework with partial rewards for enhancing both accuracy and reasoning capabilities in Text-to-SQL tasks.
Multi-Agent Design: Optimizing Agents with Better Prompts and Topologies
Feb 04, 2025Large language models, employed as multiple agents that interact and collaborate with each other, have excelled at solving complex tasks. The agents are programmed with prompts that declare their functionality, along with the topologies that orchestrate interactions across agents. Designing prompts and topologies for multi-agent systems (MAS) is inherently complex. To automate the entire design process, we first conduct an in-depth analysis of the design space aiming to understand the factors behind building effective MAS. We reveal that prompts together with topologies play critical roles in enabling more effective MAS design. Based on the insights, we propose Multi-Agent System Search (MASS), a MAS optimization framework that efficiently exploits the complex MAS design space by interleaving its optimization stages, from local to global, from prompts to topologies, over three stages: 1) block-level (local) prompt optimization; 2) workflow topology optimization; 3) workflow-level (global) prompt optimization, where each stage is conditioned on the iteratively optimized prompts/topologies from former stages. We show that MASS-optimized multi-agent systems outperform a spectrum of existing alternatives by a substantial margin. Based on the MASS-found systems, we finally propose design principles behind building effective multi-agent systems.
Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models
Oct 09, 2024



Retrieval-Augmented Generation (RAG), while effective in integrating external knowledge to address the limitations of large language models (LLMs), can be undermined by imperfect retrieval, which may introduce irrelevant, misleading, or even malicious information. Despite its importance, previous studies have rarely explored the behavior of RAG through joint analysis on how errors from imperfect retrieval attribute and propagate, and how potential conflicts arise between the LLMs' internal knowledge and external sources. We find that imperfect retrieval augmentation might be inevitable and quite harmful, through controlled analysis under realistic conditions. We identify the knowledge conflicts between LLM-internal and external knowledge from retrieval as a bottleneck to overcome in the post-retrieval stage of RAG. To render LLMs resilient to imperfect retrieval, we propose Astute RAG, a novel RAG approach that adaptively elicits essential information from LLMs' internal knowledge, iteratively consolidates internal and external knowledge with source-awareness, and finalizes the answer according to information reliability. Our experiments using Gemini and Claude demonstrate that Astute RAG significantly outperforms previous robustness-enhanced RAG methods. Notably, Astute RAG is the only approach that matches or exceeds the performance of LLMs without RAG under worst-case scenarios. Further analysis reveals that Astute RAG effectively resolves knowledge conflicts, improving the reliability and trustworthiness of RAG systems.
Teach Better or Show Smarter? On Instructions and Exemplars in Automatic Prompt Optimization
Jun 22, 2024



Large language models have demonstrated remarkable capabilities, but their performance is heavily reliant on effective prompt engineering. Automatic prompt optimization (APO) methods are designed to automate this and can be broadly categorized into those targeting instructions (instruction optimization, IO) vs. those targeting exemplars (exemplar selection, ES). Despite their shared objective, these have evolved rather independently, with IO recently receiving more research attention. This paper seeks to bridge this gap by comprehensively comparing the performance of representative IO and ES techniques, both isolation and combination, on a diverse set of challenging tasks. Our findings reveal that intelligently reusing model-generated input-output pairs obtained from evaluating prompts on the validation set as exemplars consistently improves performance over IO methods but is currently under-investigated. We also find that despite the recent focus on IO, how we select exemplars can outweigh how we optimize instructions, with ES strategies as simple as random search outperforming state-of-the-art IO methods with seed instructions without any optimization. Moreover, we observe synergy between ES and IO, with optimal combinations surpassing individual contributions. We conclude that studying exemplar selection as a standalone method and its optimal combination with instruction optimization remains a crucial aspect of APO and deserves greater consideration in future research, even in the era of highly capable instruction-following models.
Fairer Preferences Elicit Improved Human-Aligned Large Language Model Judgments
Jun 17, 2024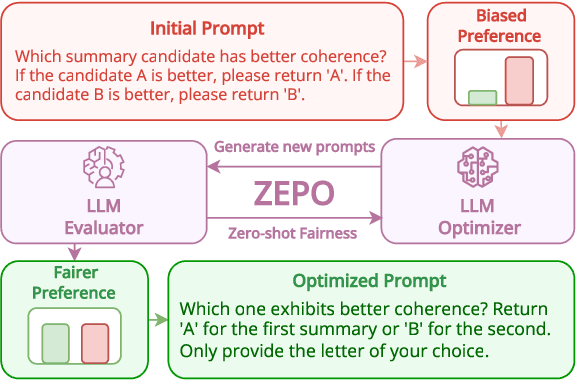


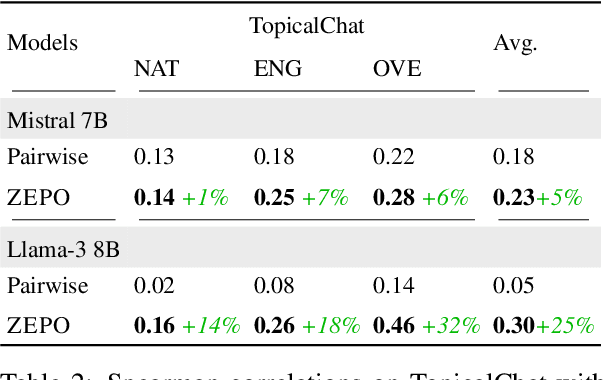
Large language models (LLMs) have shown promising abilities as cost-effective and reference-free evaluators for assessing language generation quality. In particular, pairwise LLM evaluators, which compare two generated texts and determine the preferred one, have been employed in a wide range of applications. However, LLMs exhibit preference biases and worrying sensitivity to prompt designs. In this work, we first reveal that the predictive preference of LLMs can be highly brittle and skewed, even with semantically equivalent instructions. We find that fairer predictive preferences from LLMs consistently lead to judgments that are better aligned with humans. Motivated by this phenomenon, we propose an automatic Zero-shot Evaluation-oriented Prompt Optimization framework, ZEPO, which aims to produce fairer preference decisions and improve the alignment of LLM evaluators with human judgments. To this end, we propose a zero-shot learning objective based on the preference decision fairness. ZEPO demonstrates substantial performance improvements over state-of-the-art LLM evaluators, without requiring labeled data, on representative meta-evaluation benchmarks. Our findings underscore the critical correlation between preference fairness and human alignment, positioning ZEPO as an efficient prompt optimizer for bridging the gap between LLM evaluators and human judgments.
Bayesian Optimization of Functions over Node Subsets in Graphs
May 24, 2024



We address the problem of optimizing over functions defined on node subsets in a graph. The optimization of such functions is often a non-trivial task given their combinatorial, black-box and expensive-to-evaluate nature. Although various algorithms have been introduced in the literature, most are either task-specific or computationally inefficient and only utilize information about the graph structure without considering the characteristics of the function. To address these limitations, we utilize Bayesian Optimization (BO), a sample-efficient black-box solver, and propose a novel framework for combinatorial optimization on graphs. More specifically, we map each $k$-node subset in the original graph to a node in a new combinatorial graph and adopt a local modeling approach to efficiently traverse the latter graph by progressively sampling its subgraphs using a recursive algorithm. Extensive experiments under both synthetic and real-world setups demonstrate the effectiveness of the proposed BO framework on various types of graphs and optimization tasks, where its behavior is analyzed in detail with ablation studies.
Survival of the Most Influential Prompts: Efficient Black-Box Prompt Search via Clustering and Pruning
Oct 19, 2023Prompt-based learning has been an effective paradigm for large pretrained language models (LLM), enabling few-shot or even zero-shot learning. Black-box prompt search has received growing interest recently for its distinctive properties of gradient-free optimization, proven particularly useful and powerful for model-as-a-service usage. However, the discrete nature and the complexity of combinatorial optimization hinder the efficiency of modern black-box approaches. Despite extensive research on search algorithms, the crucial aspect of search space design and optimization has been largely overlooked. In this paper, we first conduct a sensitivity analysis by prompting LLM, revealing that only a small number of tokens exert a disproportionate amount of influence on LLM predictions. Leveraging this insight, we propose the Clustering and Pruning for Efficient Black-box Prompt Search (ClaPS), a simple black-box search method that first clusters and prunes the search space to focus exclusively on influential prompt tokens. By employing even simple search methods within the pruned search space, ClaPS achieves state-of-the-art performance across various tasks and LLMs, surpassing the performance of complex approaches while significantly reducing search costs. Our findings underscore the critical role of search space design and optimization in enhancing both the usefulness and the efficiency of black-box prompt-based learning.
Batch Calibration: Rethinking Calibration for In-Context Learning and Prompt Engineering
Sep 29, 2023



Prompting and in-context learning (ICL) have become efficient learning paradigms for large language models (LLMs). However, LLMs suffer from prompt brittleness and various bias factors in the prompt, including but not limited to the formatting, the choice verbalizers, and the ICL examples. To address this problem that results in unexpected performance degradation, calibration methods have been developed to mitigate the effects of these biases while recovering LLM performance. In this work, we first conduct a systematic analysis of the existing calibration methods, where we both provide a unified view and reveal the failure cases. Inspired by these analyses, we propose Batch Calibration (BC), a simple yet intuitive method that controls the contextual bias from the batched input, unifies various prior approaches, and effectively addresses the aforementioned issues. BC is zero-shot, inference-only, and incurs negligible additional costs. In the few-shot setup, we further extend BC to allow it to learn the contextual bias from labeled data. We validate the effectiveness of BC with PaLM 2-(S, M, L) and CLIP models and demonstrate state-of-the-art performance over previous calibration baselines across more than 10 natural language understanding and image classification tasks.