 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanGEN: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories for Complex Problem Solving
Feb 22, 2025Recent agent frameworks and inference-time algorithms often struggle with complex planning problems due to limitations in verifying generated plans or reasoning and varying complexity of instances within a single task. Many existing methods for these tasks either perform task-level verification without considering constraints or apply inference-time algorithms without adapting to instance-level complexity. To address these limitations, we propose PlanGEN, a model-agnostic and easily scalable agent framework with three key components: constraint, verification, and selection agents. Specifically, our approach proposes constraint-guided iterative verification to enhance performance of inference-time algorithms--Best of N, Tree-of-Thought, and REBASE. In PlanGEN framework, the selection agent optimizes algorithm choice based on instance complexity, ensuring better adaptability to complex planning problems. Experimental results demonstrate significant improvements over the strongest baseline across multiple benchmarks, achieving state-of-the-art results on NATURAL PLAN ($\sim$8%$\uparrow$), OlympiadBench ($\sim$4%$\uparrow$), DocFinQA ($\sim$7%$\uparrow$), and GPQA ($\sim$1%$\uparrow$). Our key finding highlights that constraint-guided iterative verification improves inference-time algorithms, and adaptive selection further boosts performance on complex planning and reasoning problems.
Teach Better or Show Smarter? On Instructions and Exemplars in Automatic Prompt Optimization
Jun 22, 2024



Large language models have demonstrated remarkable capabilities, but their performance is heavily reliant on effective prompt engineering. Automatic prompt optimization (APO) methods are designed to automate this and can be broadly categorized into those targeting instructions (instruction optimization, IO) vs. those targeting exemplars (exemplar selection, ES). Despite their shared objective, these have evolved rather independently, with IO recently receiving more research attention. This paper seeks to bridge this gap by comprehensively comparing the performance of representative IO and ES techniques, both isolation and combination, on a diverse set of challenging tasks. Our findings reveal that intelligently reusing model-generated input-output pairs obtained from evaluating prompts on the validation set as exemplars consistently improves performance over IO methods but is currently under-investigated. We also find that despite the recent focus on IO, how we select exemplars can outweigh how we optimize instructions, with ES strategies as simple as random search outperforming state-of-the-art IO methods with seed instructions without any optimization. Moreover, we observe synergy between ES and IO, with optimal combinations surpassing individual contributions. We conclude that studying exemplar selection as a standalone method and its optimal combination with instruction optimization remains a crucial aspect of APO and deserves greater consideration in future research, even in the era of highly capable instruction-following models.
TextGenSHAP: Scalable Post-hoc Explanations in Text Generation with Long Documents
Dec 03, 2023



Large language models (LLMs) have attracted huge interest in practical applications given their increasingly accurate responses and coherent reasoning abilities. Given their nature as black-boxes using complex reasoning processes on their inputs, it is inevitable that the demand for scalable and faithful explanations for LLMs' generated content will continue to grow. There have been major developments in the explainability of neural network models over the past decade. Among them, post-hoc explainability methods, especially Shapley values, have proven effective for interpreting deep learning models. However, there are major challenges in scaling up Shapley values for LLMs, particularly when dealing with long input contexts containing thousands of tokens and autoregressively generated output sequences. Furthermore, it is often unclear how to effectively utilize generated explanations to improve the performance of LLMs. In this paper, we introduce TextGenSHAP, an efficient post-hoc explanation method incorporating LM-specific techniques. We demonstrate that this leads to significant increases in speed compared to conventional Shapley value computations, reducing processing times from hours to minutes for token-level explanations, and to just seconds for document-level explanations. In addition, we demonstrate how real-time Shapley values can be utilized in two important scenarios, providing better understanding of long-document question answering by localizing important words and sentences; and improving existing document retrieval systems through enhancing the accuracy of selected passages and ultimately the final responses.
SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data
Nov 06, 2023



Text-to-SQL aims to automate the process of generating SQL queries on a database from natural language text. In this work, we propose "SQLPrompt", tailored to improve the few-shot prompting capabilities of Text-to-SQL for Large Language Models (LLMs). Our methods include innovative prompt design, execution-based consistency decoding strategy which selects the SQL with the most consistent execution outcome among other SQL proposals, and a method that aims to improve performance by diversifying the SQL proposals during consistency selection with different prompt designs ("MixPrompt") and foundation models ("MixLLMs"). We show that \emph{SQLPrompt} outperforms previous approaches for in-context learning with few labeled data by a large margin, closing the gap with finetuning state-of-the-art with thousands of labeled data.
SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL
Jun 07, 2023



One impressive emergent capability of large language models (LLMs) is generation of code, including Structured Query Language (SQL) for databases. For the task of converting natural language text to SQL queries, Text-to-SQL, adaptation of LLMs is of paramount importance, both in in-context learning and fine-tuning settings, depending on the amount of adaptation data used. In this paper, we propose an LLM-based Text-to-SQL model SQL-PaLM, leveraging on PaLM-2, that pushes the state-of-the-art in both settings. Few-shot SQL-PaLM is based on an execution-based self-consistency prompting approach designed for Text-to-SQL, and achieves 77.3% in test-suite accuracy on Spider, which to our best knowledge is the first to outperform previous state-of-the-art with fine-tuning by a significant margin, 4%. Furthermore, we demonstrate that the fine-tuned SQL-PALM outperforms it further by another 1%. Towards applying SQL-PaLM to real-world scenarios we further evaluate its robustness on other challenging variants of Spider and demonstrate the superior generalization capability of SQL-PaLM. In addition, via extensive case studies, we demonstrate the impressive intelligent capabilities and various success enablers of LLM-based Text-to-SQL.
Universal Self-adaptive Prompting
May 24, 2023



A hallmark of modern large language models (LLMs) is their impressive general zero-shot and few-shot abilities, often elicited through prompt-based and/or in-context learning. However, while highly coveted and being the most general, zero-shot performances in LLMs are still typically weaker due to the lack of guidance and the difficulty of applying existing automatic prompt design methods in general tasks when ground-truth labels are unavailable. In this study, we address this by presenting Universal Self-adaptive Prompting (USP), an automatic prompt design approach specifically tailored for zero-shot learning (while compatible with few-shot). Requiring only a small amount of unlabeled data & an inference-only LLM, USP is highly versatile: to achieve universal prompting, USP categorizes a possible NLP task into one of the three possible task types, and then uses a corresponding selector to select the most suitable queries & zero-shot model-generated responses as pseudo-demonstrations, thereby generalizing ICL to the zero-shot setup in a fully automated way. We evaluate zero-shot USP with two PaLM models, and demonstrate performances that are considerably stronger than standard zero-shot baselines and are comparable to or even superior than few-shot baselines across more than 20 natural language understanding (NLU) and natural language generation (NLG) tasks.
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
May 03, 2023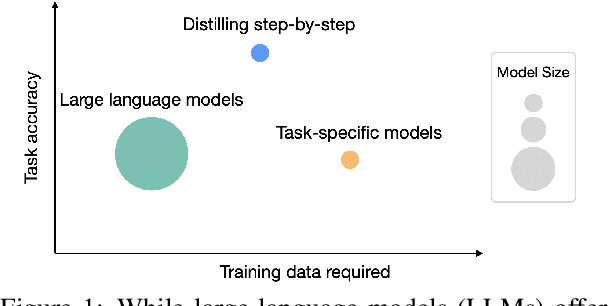
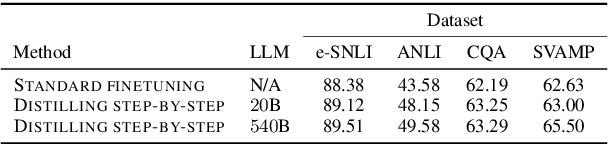
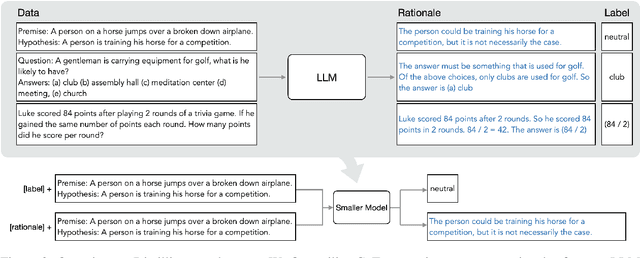

Deploying large language models (LLMs) is challenging because they are memory inefficient and compute-intensive for practical applications. In reaction, researchers train smaller task-specific models by either finetuning with human labels or distilling using LLM-generated labels. However, finetuning and distillation require large amounts of training data to achieve comparable performance to LLMs. We introduce Distilling step-by-step, a new mechanism that (a) trains smaller models that outperform LLMs, and (b) achieves so by leveraging less training data needed by finetuning or distillation. Our method extracts LLM rationales as additional supervision for small models within a multi-task training framework. We present three findings across 4 NLP benchmarks: First, compared to both finetuning and distillation, our mechanism achieves better performance with much fewer labeled/unlabeled training examples. Second, compared to LLMs, we achieve better performance using substantially smaller model sizes. Third, we reduce both the model size and the amount of data required to outperform LLMs; our 770M T5 model outperforms the 540B PaLM model using only 80% of available data on a benchmark task.
Controlling Commercial Cooling Systems Using Reinforcement Learning
Nov 11, 2022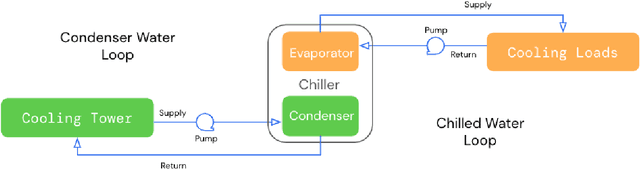
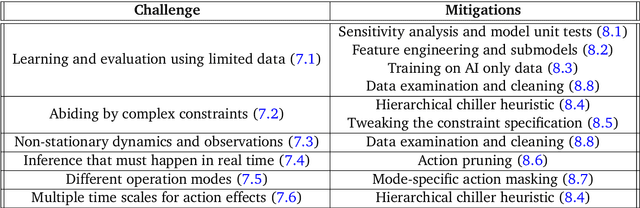
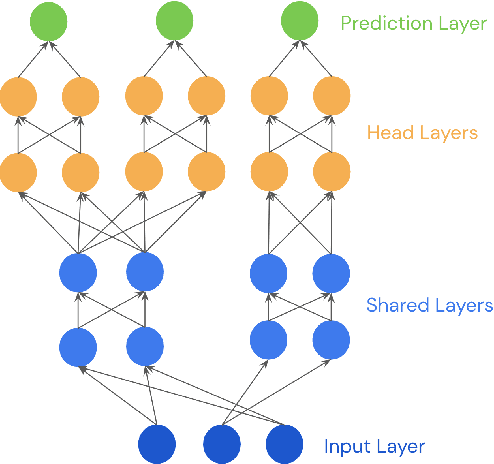
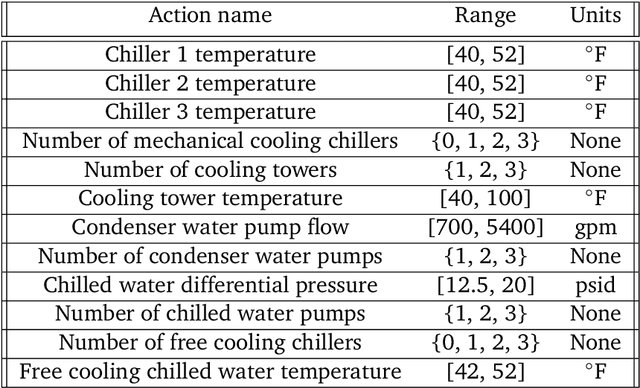
This paper is a technical overview of DeepMind and Google's recent work on reinforcement learning for controlling commercial cooling systems. Building on expertise that began with cooling Google's data centers more efficiently, we recently conducted live experiments on two real-world facilities in partnership with Trane Technologies, a building management system provider. These live experiments had a variety of challenges in areas such as evaluation, learning from offline data, and constraint satisfaction. Our paper describes these challenges in the hope that awareness of them will benefit future applied RL work. We also describe the way we adapted our RL system to deal with these challenges, resulting in energy savings of approximately 9% and 13% respectively at the two live experiment sites.
Interpretable Sequence Learning for COVID-19 Forecasting
Aug 03, 2020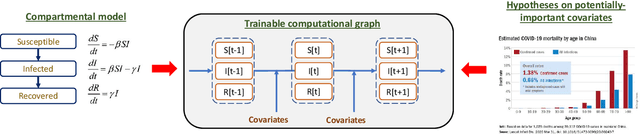
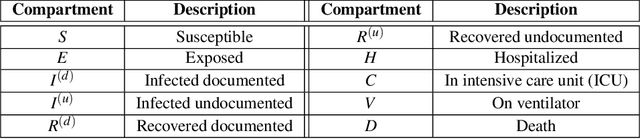
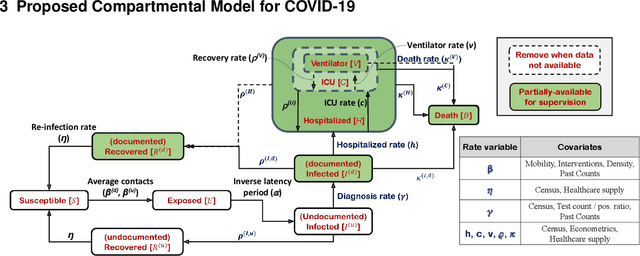
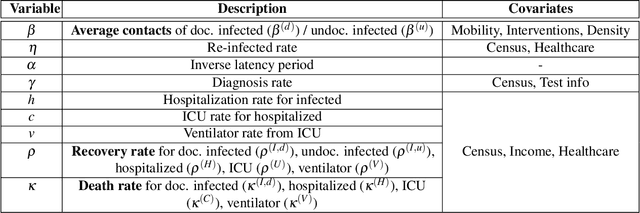
We propose a novel approach that integrates machine learning into compartmental disease modeling to predict the progression of COVID-19. Our model is explainable by design as it explicitly shows how different compartments evolve and it uses interpretable encoders to incorporate covariates and improve performance. Explainability is valuable to ensure that the model's forecasts are credible to epidemiologists and to instill confidence in end-users such as policy makers and healthcare institutions. Our model can be applied at different geographic resolutions, and here we demonstrate it for states and counties in the United States. We show that our model provides more accurate forecasts, in metrics averaged across the entire US, than state-of-the-art alternatives, and that it provides qualitatively meaningful explanatory insights. Lastly, we analyze the performance of our model for different subgroups based on the subgroup distributions within the counties.