 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning
Apr 15, 2024Large Language Models (LLMs), with their remarkable ability to tackle challenging and unseen reasoning problems, hold immense potential for tabular learning, that is vital for many real-world applications. In this paper, we propose a novel in-context learning framework, FeatLLM, which employs LLMs as feature engineers to produce an input data set that is optimally suited for tabular predictions. The generated features are used to infer class likelihood with a simple downstream machine learning model, such as linear regression and yields high performance few-shot learning. The proposed FeatLLM framework only uses this simple predictive model with the discovered features at inference time. Compared to existing LLM-based approaches, FeatLLM eliminates the need to send queries to the LLM for each sample at inference time. Moreover, it merely requires API-level access to LLMs, and overcomes prompt size limitations. As demonstrated across numerous tabular datasets from a wide range of domains, FeatLLM generates high-quality rules, significantly (10% on average) outperforming alternatives such as TabLLM and STUNT.
TextGenSHAP: Scalable Post-hoc Explanations in Text Generation with Long Documents
Dec 03, 2023



Large language models (LLMs) have attracted huge interest in practical applications given their increasingly accurate responses and coherent reasoning abilities. Given their nature as black-boxes using complex reasoning processes on their inputs, it is inevitable that the demand for scalable and faithful explanations for LLMs' generated content will continue to grow. There have been major developments in the explainability of neural network models over the past decade. Among them, post-hoc explainability methods, especially Shapley values, have proven effective for interpreting deep learning models. However, there are major challenges in scaling up Shapley values for LLMs, particularly when dealing with long input contexts containing thousands of tokens and autoregressively generated output sequences. Furthermore, it is often unclear how to effectively utilize generated explanations to improve the performance of LLMs. In this paper, we introduce TextGenSHAP, an efficient post-hoc explanation method incorporating LM-specific techniques. We demonstrate that this leads to significant increases in speed compared to conventional Shapley value computations, reducing processing times from hours to minutes for token-level explanations, and to just seconds for document-level explanations. In addition, we demonstrate how real-time Shapley values can be utilized in two important scenarios, providing better understanding of long-document question answering by localizing important words and sentences; and improving existing document retrieval systems through enhancing the accuracy of selected passages and ultimately the final responses.
Adaptation with Self-Evaluation to Improve Selective Prediction in LLMs
Oct 18, 2023Large language models (LLMs) have recently shown great advances in a variety of tasks, including natural language understanding and generation. However, their use in high-stakes decision-making scenarios is still limited due to the potential for errors. Selective prediction is a technique that can be used to improve the reliability of the LLMs by allowing them to abstain from making predictions when they are unsure of the answer. In this work, we propose a novel framework for adaptation with self-evaluation to improve the selective prediction performance of LLMs. Our framework is based on the idea of using parameter-efficient tuning to adapt the LLM to the specific task at hand while improving its ability to perform self-evaluation. We evaluate our method on a variety of question-answering (QA) datasets and show that it outperforms state-of-the-art selective prediction methods. For example, on the CoQA benchmark, our method improves the AUACC from 91.23% to 92.63% and improves the AUROC from 74.61% to 80.25%.
TEMPO: Prompt-based Generative Pre-trained Transformer for Time Series Forecasting
Oct 12, 2023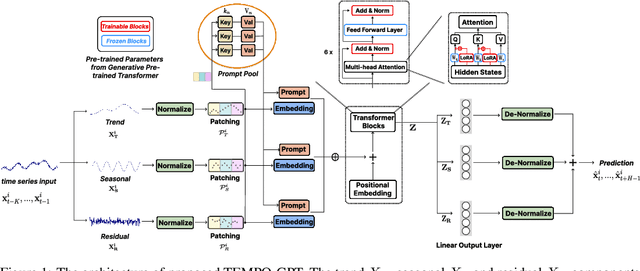
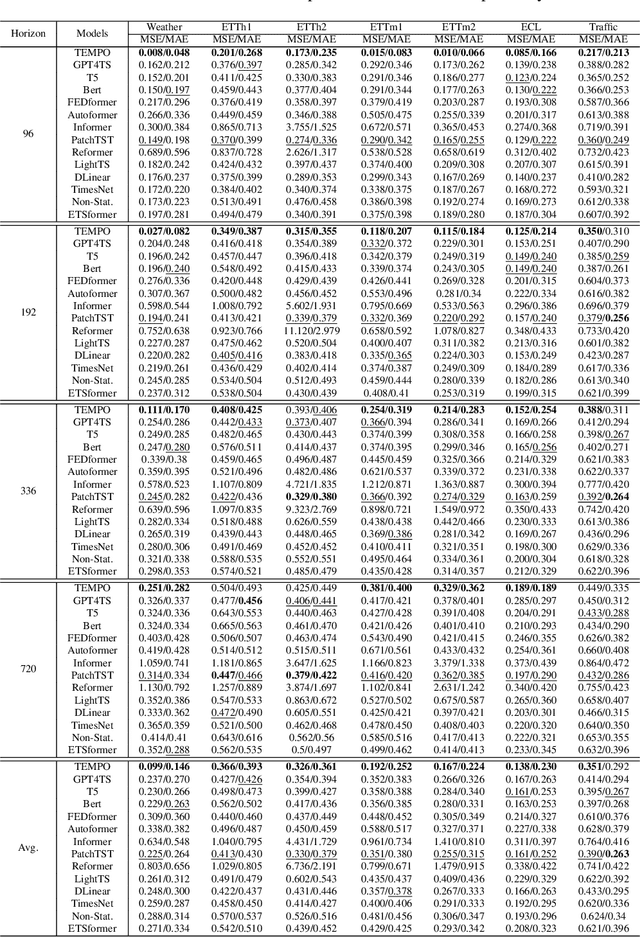


The past decade has witnessed significant advances in time series modeling with deep learning. While achieving state-of-the-art results, the best-performing architectures vary highly across applications and domains. Meanwhile, for natural language processing, the Generative Pre-trained Transformer (GPT) has demonstrated impressive performance via training one general-purpose model across various textual datasets. It is intriguing to explore whether GPT-type architectures can be effective for time series, capturing the intrinsic dynamic attributes and leading to significant accuracy improvements. In this paper, we propose a novel framework, TEMPO, that can effectively learn time series representations. We focus on utilizing two essential inductive biases of the time series task for pre-trained models: (i) decomposition of the complex interaction between trend, seasonal and residual components; and (ii) introducing the selection-based prompts to facilitate distribution adaptation in non-stationary time series. TEMPO expands the capability for dynamically modeling real-world temporal phenomena from data within diverse domains. Our experiments demonstrate the superior performance of TEMPO over state-of-the-art methods on a number of time series benchmark datasets. This performance gain is observed not only in standard supervised learning settings but also in scenarios involving previously unseen datasets as well as in scenarios with multi-modal inputs. This compelling finding highlights TEMPO's potential to constitute a foundational model-building framework.
Search-Adaptor: Text Embedding Customization for Information Retrieval
Oct 12, 2023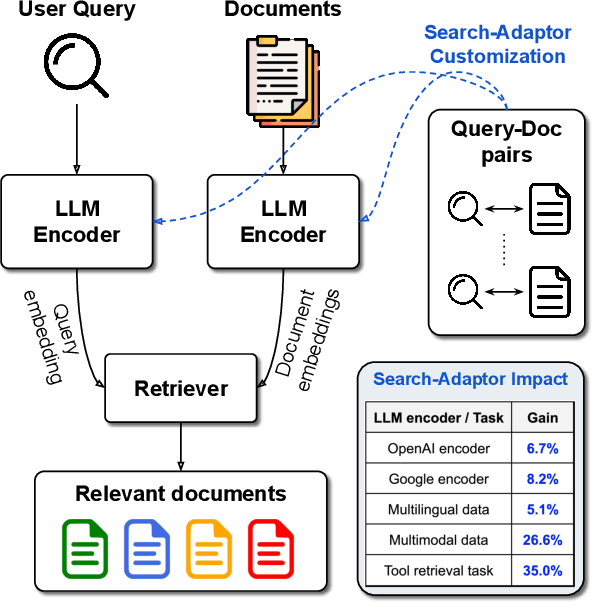
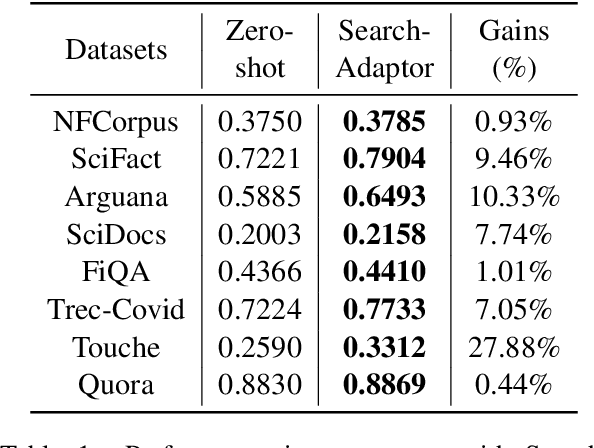


Text embeddings extracted by pre-trained Large Language Models (LLMs) have significant potential to improve information retrieval and search. Beyond the zero-shot setup in which they are being conventionally used, being able to take advantage of the information from the relevant query-corpus paired data has the power to further boost the LLM capabilities. In this paper, we propose a novel method, Search-Adaptor, for customizing LLMs for information retrieval in an efficient and robust way. Search-Adaptor modifies the original text embedding generated by pre-trained LLMs, and can be integrated with any LLM, including those only available via APIs. On multiple real-world English and multilingual retrieval datasets, we show consistent and significant performance benefits for Search-Adaptor -- e.g., more than 5.2% improvements over the Google Embedding APIs in nDCG@10 averaged over 13 BEIR datasets.