 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Reduced Accessibility to WASH Facilities in Rohingya Refugee Camps With Sub-Meter Imagery
Nov 18, 2025Access to Water, Sanitation, and Hygiene (WASH) services remains a major public health concern in refugee camps. This study introduces a remote sensing-driven framework to quantify WASH accessibility-specifically to water pumps, latrines, and bathing cubicles-in the Rohingya camps of Cox's Bazar, one of the world's most densely populated displacement settings. Detecting refugee shelters in such emergent camps presents substantial challenges, primarily due to their dense spatial configuration and irregular geometric patterns. Using sub-meter satellite images, we develop a semi-supervised segmentation framework that achieves an F1-score of 76.4% in detecting individual refugee shelters. Applying the framework across multi-year data reveals declining WASH accessibility, driven by rapid refugee population growth and reduced facility availability, rising from 25 people per facility in 2022 to 29.4 in 2025. Gender-disaggregated analysis further shows that women and girls experience reduced accessibility, in scenarios with inadequate safety-related segregation in WASH facilities. These findings suggest the importance of demand-responsive allocation strategies that can identify areas with under-served populations-such as women and girls-and ensure that limited infrastructure serves the greatest number of people in settings with fixed or shrinking budgets. We also discuss the value of high-resolution remote sensing and machine learning to detect inequality and inform equitable resource planning in complex humanitarian environments.
GeoReg: Weight-Constrained Few-Shot Regression for Socio-Economic Estimation using LLM
Jul 17, 2025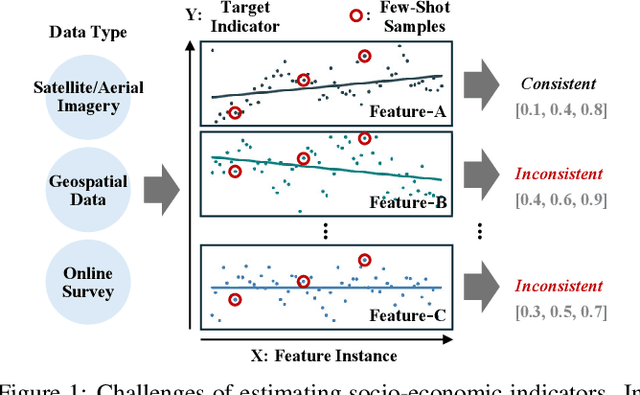


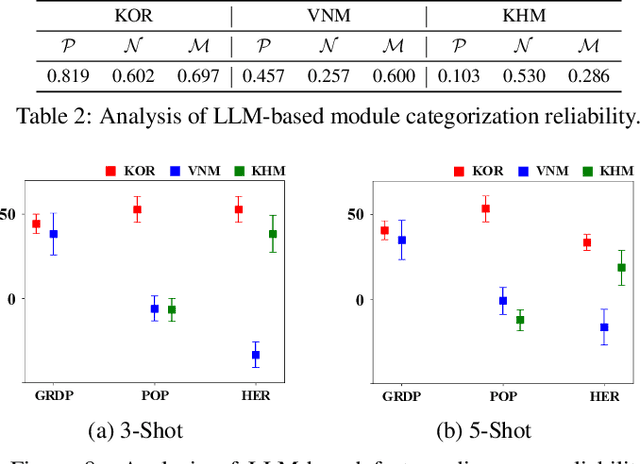
Socio-economic indicators like regional GDP, population, and education levels, are crucial to shaping policy decisions and fostering sustainable development. This research introduces GeoReg a regression model that integrates diverse data sources, including satellite imagery and web-based geospatial information, to estimate these indicators even for data-scarce regions such as developing countries. Our approach leverages the prior knowledge of large language model (LLM) to address the scarcity of labeled data, with the LLM functioning as a data engineer by extracting informative features to enable effective estimation in few-shot settings. Specifically, our model obtains contextual relationships between data features and the target indicator, categorizing their correlations as positive, negative, mixed, or irrelevant. These features are then fed into the linear estimator with tailored weight constraints for each category. To capture nonlinear patterns, the model also identifies meaningful feature interactions and integrates them, along with nonlinear transformations. Experiments across three countries at different stages of development demonstrate that our model outperforms baselines in estimating socio-economic indicators, even for low-income countries with limited data availability.
GIFARC: Synthetic Dataset for Leveraging Human-Intuitive Analogies to Elevate AI Reasoning
May 27, 2025The Abstraction and Reasoning Corpus (ARC) poses a stringent test of general AI capabilities, requiring solvers to infer abstract patterns from only a handful of examples. Despite substantial progress in deep learning, state-of-the-art models still achieve accuracy rates of merely 40-55% on 2024 ARC Competition, indicative of a significant gap between their performance and human-level reasoning. In this work, we seek to bridge that gap by introducing an analogy-inspired ARC dataset, GIFARC. Leveraging large language models (LLMs) and vision-language models (VLMs), we synthesize new ARC-style tasks from a variety of GIF images that include analogies. Each new task is paired with ground-truth analogy, providing an explicit mapping between visual transformations and everyday concepts. By embedding robust human-intuitive analogies into ARC-style tasks, GIFARC guides AI agents to evaluate the task analogically before engaging in brute-force pattern search, thus efficiently reducing problem complexity and build a more concise and human-understandable solution. We empirically validate that guiding LLM with analogic approach with GIFARC affects task-solving approaches of LLMs to align with analogic approach of human.
Adversarial Style Augmentation via Large Language Model for Robust Fake News Detection
Jun 17, 2024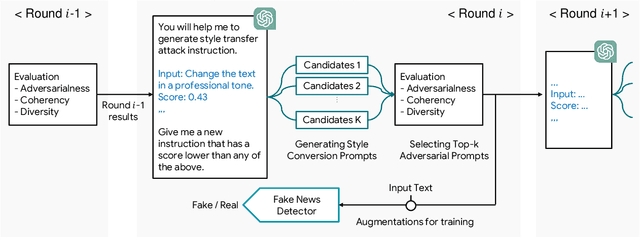
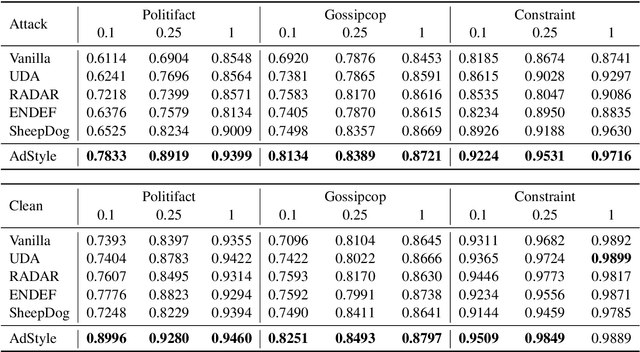

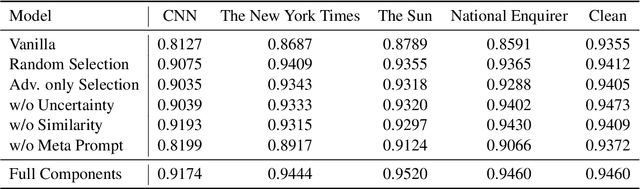
The spread of fake news negatively impacts individuals and is regarded as a significant social challenge that needs to be addressed. A number of algorithmic and insightful features have been identified for detecting fake news. However, with the recent LLMs and their advanced generation capabilities, many of the detectable features (e.g., style-conversion attacks) can be altered, making it more challenging to distinguish from real news. This study proposes adversarial style augmentation, AdStyle, to train a fake news detector that remains robust against various style-conversion attacks. Our model's key mechanism is the careful use of LLMs to automatically generate a diverse yet coherent range of style-conversion attack prompts. This improves the generation of prompts that are particularly difficult for the detector to handle. Experiments show that our augmentation strategy improves robustness and detection performance when tested on fake news benchmark datasets.
Generalizable Disaster Damage Assessment via Change Detection with Vision Foundation Model
Jun 12, 2024



The increasing frequency and intensity of natural disasters demand more sophisticated approaches for rapid and precise damage assessment. To tackle this issue, researchers have developed various methods on disaster benchmark datasets from satellite imagery to aid in detecting disaster damage. However, the diverse nature of geographical landscapes and disasters makes it challenging to apply existing methods to regions unseen during training. We present DAVI (Disaster Assessment with VIsion foundation model), which overcomes domain disparities and detects structural damage (e.g., building) without requiring ground-truth labels of the target region. DAVI integrates task-specific knowledge from a model trained on source regions with an image segmentation foundation model to generate pseudo labels of possible damage in the target region. It then employs a two-stage refinement process, targeting both the pixel and overall image, to more accurately pinpoint changes in disaster-struck areas based on before-and-after images. Comprehensive evaluations demonstrate that DAVI achieves exceptional performance across diverse terrains (e.g., USA and Mexico) and disaster types (e.g., wildfires, hurricanes, and earthquakes). This confirms its robustness in assessing disaster impact without dependence on ground-truth labels.
FedMID: A Data-Free Method for Using Intermediate Outputs as a Defense Mechanism Against Poisoning Attacks in Federated Learning
Apr 18, 2024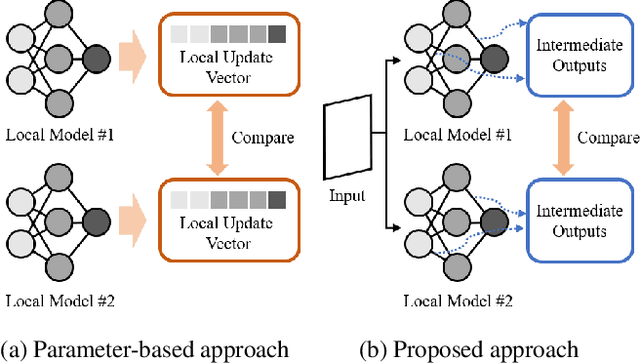
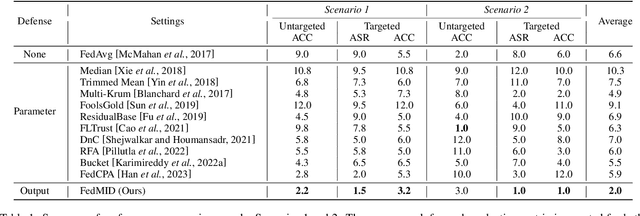
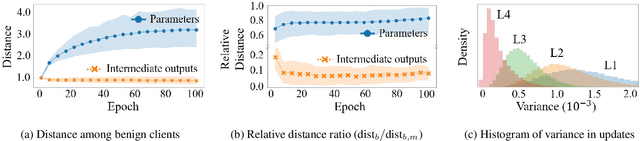
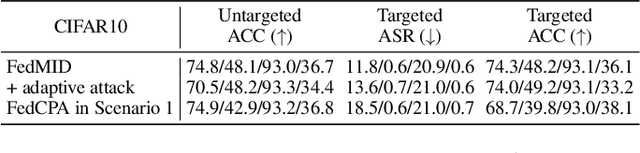
Federated learning combines local updates from clients to produce a global model, which is susceptible to poisoning attacks. Most previous defense strategies relied on vectors derived from projections of local updates on a Euclidean space; however, these methods fail to accurately represent the functionality and structure of local models, resulting in inconsistent performance. Here, we present a new paradigm to defend against poisoning attacks in federated learning using functional mappings of local models based on intermediate outputs. Experiments show that our mechanism is robust under a broad range of computing conditions and advanced attack scenarios, enabling safer collaboration among data-sensitive participants via federated learning.
Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning
Apr 15, 2024Large Language Models (LLMs), with their remarkable ability to tackle challenging and unseen reasoning problems, hold immense potential for tabular learning, that is vital for many real-world applications. In this paper, we propose a novel in-context learning framework, FeatLLM, which employs LLMs as feature engineers to produce an input data set that is optimally suited for tabular predictions. The generated features are used to infer class likelihood with a simple downstream machine learning model, such as linear regression and yields high performance few-shot learning. The proposed FeatLLM framework only uses this simple predictive model with the discovered features at inference time. Compared to existing LLM-based approaches, FeatLLM eliminates the need to send queries to the LLM for each sample at inference time. Moreover, it merely requires API-level access to LLMs, and overcomes prompt size limitations. As demonstrated across numerous tabular datasets from a wide range of domains, FeatLLM generates high-quality rules, significantly (10% on average) outperforming alternatives such as TabLLM and STUNT.
Towards Attack-tolerant Federated Learning via Critical Parameter Analysis
Aug 18, 2023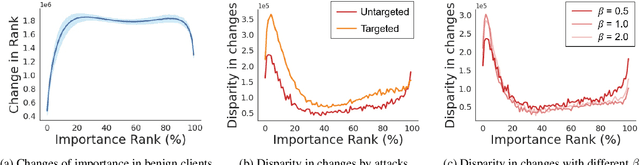
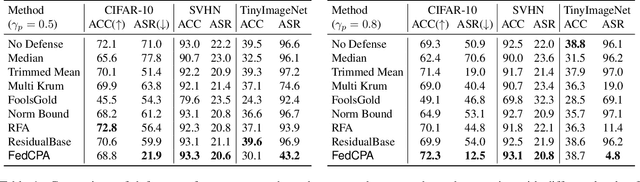
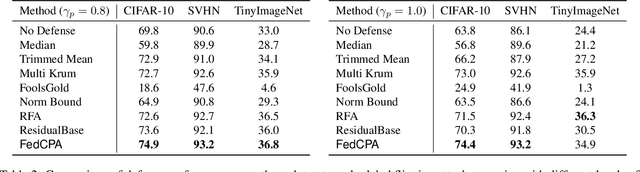
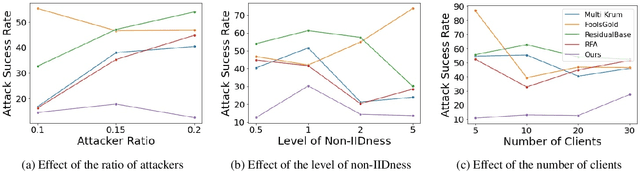
Federated learning is used to train a shared model in a decentralized way without clients sharing private data with each other. Federated learning systems are susceptible to poisoning attacks when malicious clients send false updates to the central server. Existing defense strategies are ineffective under non-IID data settings. This paper proposes a new defense strategy, FedCPA (Federated learning with Critical Parameter Analysis). Our attack-tolerant aggregation method is based on the observation that benign local models have similar sets of top-k and bottom-k critical parameters, whereas poisoned local models do not. Experiments with different attack scenarios on multiple datasets demonstrate that our model outperforms existing defense strategies in defending against poisoning attacks.
FedDefender: Client-Side Attack-Tolerant Federated Learning
Jul 18, 2023Federated learning enables learning from decentralized data sources without compromising privacy, which makes it a crucial technique. However, it is vulnerable to model poisoning attacks, where malicious clients interfere with the training process. Previous defense mechanisms have focused on the server-side by using careful model aggregation, but this may not be effective when the data is not identically distributed or when attackers can access the information of benign clients. In this paper, we propose a new defense mechanism that focuses on the client-side, called FedDefender, to help benign clients train robust local models and avoid the adverse impact of malicious model updates from attackers, even when a server-side defense cannot identify or remove adversaries. Our method consists of two main components: (1) attack-tolerant local meta update and (2) attack-tolerant global knowledge distillation. These components are used to find noise-resilient model parameters while accurately extracting knowledge from a potentially corrupted global model. Our client-side defense strategy has a flexible structure and can work in conjunction with any existing server-side strategies. Evaluations of real-world scenarios across multiple datasets show that the proposed method enhances the robustness of federated learning against model poisoning attacks.
DualFair: Fair Representation Learning at Both Group and Individual Levels via Contrastive Self-supervision
Mar 15, 2023Algorithmic fairness has become an important machine learning problem, especially for mission-critical Web applications. This work presents a self-supervised model, called DualFair, that can debias sensitive attributes like gender and race from learned representations. Unlike existing models that target a single type of fairness, our model jointly optimizes for two fairness criteria - group fairness and counterfactual fairness - and hence makes fairer predictions at both the group and individual levels. Our model uses contrastive loss to generate embeddings that are indistinguishable for each protected group, while forcing the embeddings of counterfactual pairs to be similar. It then uses a self-knowledge distillation method to maintain the quality of representation for the downstream tasks. Extensive analysis over multiple datasets confirms the model's validity and further shows the synergy of jointly addressing two fairness criteria, suggesting the model's potential value in fair intelligent Web applications.