 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedMID: A Data-Free Method for Using Intermediate Outputs as a Defense Mechanism Against Poisoning Attacks in Federated Learning
Paper and Code
Apr 18, 2024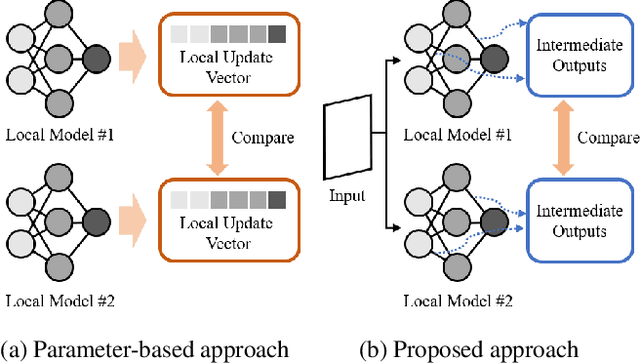
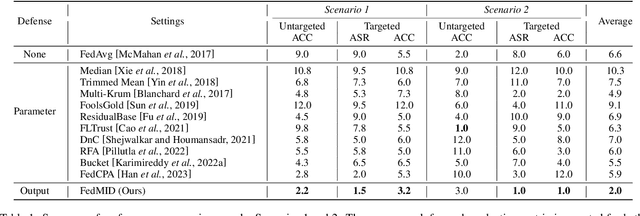
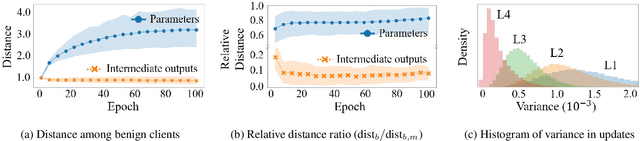
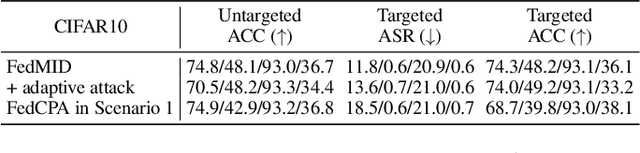
Federated learning combines local updates from clients to produce a global model, which is susceptible to poisoning attacks. Most previous defense strategies relied on vectors derived from projections of local updates on a Euclidean space; however, these methods fail to accurately represent the functionality and structure of local models, resulting in inconsistent performance. Here, we present a new paradigm to defend against poisoning attacks in federated learning using functional mappings of local models based on intermediate outputs. Experiments show that our mechanism is robust under a broad range of computing conditions and advanced attack scenarios, enabling safer collaboration among data-sensitive participants via federated learning.