 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdeological Bias in LLMs' Economic Causal Reasoning
Apr 23, 2026Do large language models (LLMs) exhibit systematic ideological bias when reasoning about economic causal effects? As LLMs are increasingly used in policy analysis and economic reporting, where directionally correct causal judgments are essential, this question has direct practical stakes. We present a systematic evaluation by extending the EconCausal benchmark with ideology-contested cases - instances where intervention-oriented (pro-government) and market-oriented (pro-market) perspectives predict divergent causal signs. From 10,490 causal triplets (treatment-outcome pairs with empirically verified effect directions) derived from top-tier economics and finance journals, we identify 1,056 ideology-contested instances and evaluate 20 state-of-the-art LLMs on their ability to predict empirically supported causal directions. We find that ideology-contested items are consistently harder than non-contested ones, and that across 18 of 20 models, accuracy is systematically higher when the empirically verified causal sign aligns with intervention-oriented expectations than with market-oriented ones. Moreover, when models err, their incorrect predictions disproportionately lean intervention-oriented, and this directional skew is not eliminated by one-shot in-context prompting. These results highlight that LLMs are not only less accurate on ideologically contested economic questions, but systematically less reliable in one ideological direction than the other, underscoring the need for direction-aware evaluation in high-stakes economic and policy settings.
Generative Neural Operators through Diffusion Last Layer
Feb 04, 2026Neural operators have emerged as a powerful paradigm for learning discretization-invariant function-to-function mappings in scientific computing. However, many practical systems are inherently stochastic, making principled uncertainty quantification essential for reliable deployment. To address this, we introduce a simple add-on, the diffusion last layer (DLL), a lightweight probabilistic head that can be attached to arbitrary neural operator backbones to model predictive uncertainty. Motivated by the relative smoothness and low-dimensional structure often exhibited by PDE solution distributions, DLL parameterizes the conditional output distribution directly in function space through a low-rank Karhunen-Loève expansion, enabling efficient and expressive uncertainty modeling. Across stochastic PDE operator learning benchmarks, DLL improves generalization and uncertainty-aware prediction. Moreover, even in deterministic long-horizon rollout settings, DLL enhances rollout stability and provides meaningful estimates of epistemic uncertainty for backbone neural operators.
Dropouts in Confidence: Moral Uncertainty in Human-LLM Alignment
Nov 17, 2025Humans display significant uncertainty when confronted with moral dilemmas, yet the extent of such uncertainty in machines and AI agents remains underexplored. Recent studies have confirmed the overly confident tendencies of machine-generated responses, particularly in large language models (LLMs). As these systems are increasingly embedded in ethical decision-making scenarios, it is important to understand their moral reasoning and the inherent uncertainties in building reliable AI systems. This work examines how uncertainty influences moral decisions in the classical trolley problem, analyzing responses from 32 open-source models and 9 distinct moral dimensions. We first find that variance in model confidence is greater across models than within moral dimensions, suggesting that moral uncertainty is predominantly shaped by model architecture and training method. To quantify uncertainty, we measure binary entropy as a linear combination of total entropy, conditional entropy, and mutual information. To examine its effects, we introduce stochasticity into models via "dropout" at inference time. Our findings show that our mechanism increases total entropy, mainly through a rise in mutual information, while conditional entropy remains largely unchanged. Moreover, this mechanism significantly improves human-LLM moral alignment, with correlations in mutual information and alignment score shifts. Our results highlight the potential to better align model-generated decisions and human preferences by deliberately modulating uncertainty and reducing LLMs' confidence in morally complex scenarios.
Generalizable Slum Detection from Satellite Imagery with Mixture-of-Experts
Nov 13, 2025Satellite-based slum segmentation holds significant promise in generating global estimates of urban poverty. However, the morphological heterogeneity of informal settlements presents a major challenge, hindering the ability of models trained on specific regions to generalize effectively to unseen locations. To address this, we introduce a large-scale high-resolution dataset and propose GRAM (Generalized Region-Aware Mixture-of-Experts), a two-phase test-time adaptation framework that enables robust slum segmentation without requiring labeled data from target regions. We compile a million-scale satellite imagery dataset from 12 cities across four continents for source training. Using this dataset, the model employs a Mixture-of-Experts architecture to capture region-specific slum characteristics while learning universal features through a shared backbone. During adaptation, prediction consistency across experts filters out unreliable pseudo-labels, allowing the model to generalize effectively to previously unseen regions. GRAM outperforms state-of-the-art baselines in low-resource settings such as African cities, offering a scalable and label-efficient solution for global slum mapping and data-driven urban planning.
Benchmarking LLM Causal Reasoning with Scientifically Validated Relationships
Oct 08, 2025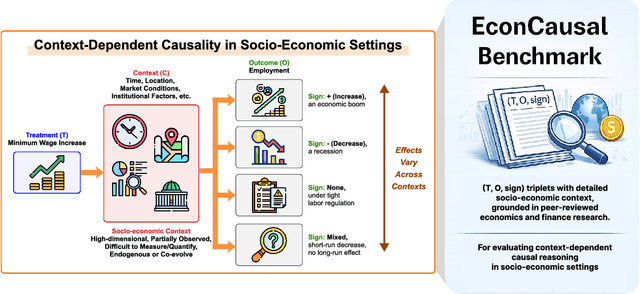



Causal reasoning is fundamental for Large Language Models (LLMs) to understand genuine cause-and-effect relationships beyond pattern matching. Existing benchmarks suffer from critical limitations such as reliance on synthetic data and narrow domain coverage. We introduce a novel benchmark constructed from casually identified relationships extracted from top-tier economics and finance journals, drawing on rigorous methodologies including instrumental variables, difference-in-differences, and regression discontinuity designs. Our benchmark comprises 40,379 evaluation items covering five task types across domains such as health, environment, technology, law, and culture. Experimental results on eight state-of-the-art LLMs reveal substantial limitations, with the best model achieving only 57.6\% accuracy. Moreover, model scale does not consistently translate to superior performance, and even advanced reasoning models struggle with fundamental causal relationship identification. These findings underscore a critical gap between current LLM capabilities and demands of reliable causal reasoning in high-stakes applications.
Adversarial Style Augmentation via Large Language Model for Robust Fake News Detection
Jun 17, 2024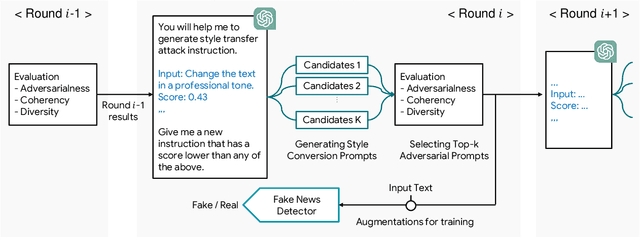
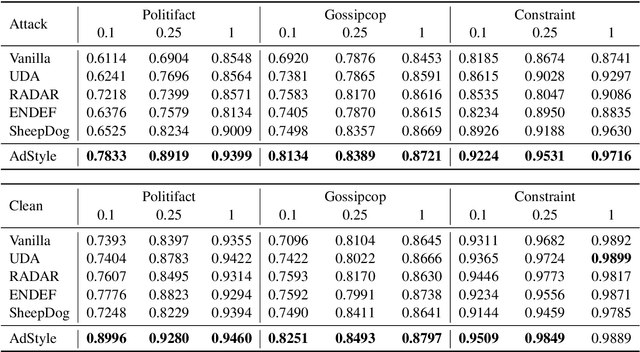

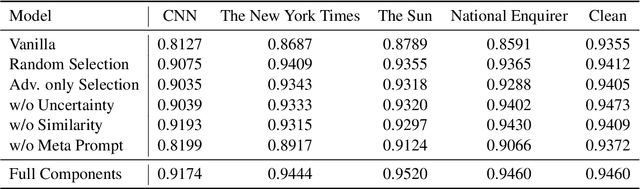
The spread of fake news negatively impacts individuals and is regarded as a significant social challenge that needs to be addressed. A number of algorithmic and insightful features have been identified for detecting fake news. However, with the recent LLMs and their advanced generation capabilities, many of the detectable features (e.g., style-conversion attacks) can be altered, making it more challenging to distinguish from real news. This study proposes adversarial style augmentation, AdStyle, to train a fake news detector that remains robust against various style-conversion attacks. Our model's key mechanism is the careful use of LLMs to automatically generate a diverse yet coherent range of style-conversion attack prompts. This improves the generation of prompts that are particularly difficult for the detector to handle. Experiments show that our augmentation strategy improves robustness and detection performance when tested on fake news benchmark datasets.
Generalizable Disaster Damage Assessment via Change Detection with Vision Foundation Model
Jun 12, 2024



The increasing frequency and intensity of natural disasters demand more sophisticated approaches for rapid and precise damage assessment. To tackle this issue, researchers have developed various methods on disaster benchmark datasets from satellite imagery to aid in detecting disaster damage. However, the diverse nature of geographical landscapes and disasters makes it challenging to apply existing methods to regions unseen during training. We present DAVI (Disaster Assessment with VIsion foundation model), which overcomes domain disparities and detects structural damage (e.g., building) without requiring ground-truth labels of the target region. DAVI integrates task-specific knowledge from a model trained on source regions with an image segmentation foundation model to generate pseudo labels of possible damage in the target region. It then employs a two-stage refinement process, targeting both the pixel and overall image, to more accurately pinpoint changes in disaster-struck areas based on before-and-after images. Comprehensive evaluations demonstrate that DAVI achieves exceptional performance across diverse terrains (e.g., USA and Mexico) and disaster types (e.g., wildfires, hurricanes, and earthquakes). This confirms its robustness in assessing disaster impact without dependence on ground-truth labels.
FedMID: A Data-Free Method for Using Intermediate Outputs as a Defense Mechanism Against Poisoning Attacks in Federated Learning
Apr 18, 2024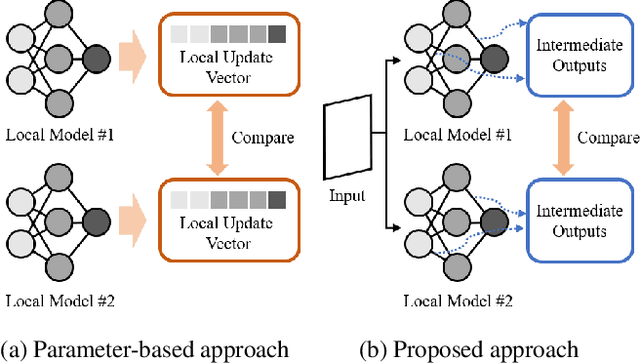
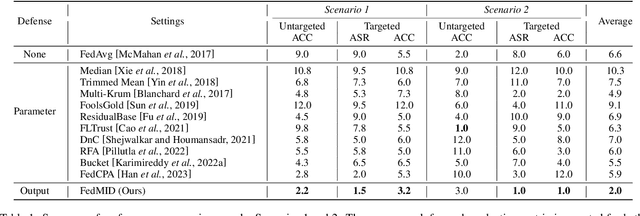
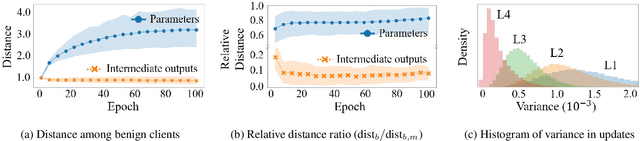
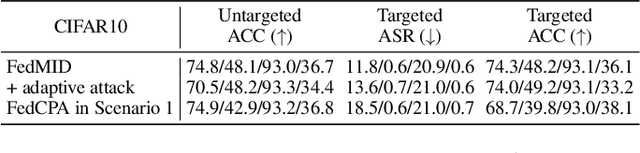
Federated learning combines local updates from clients to produce a global model, which is susceptible to poisoning attacks. Most previous defense strategies relied on vectors derived from projections of local updates on a Euclidean space; however, these methods fail to accurately represent the functionality and structure of local models, resulting in inconsistent performance. Here, we present a new paradigm to defend against poisoning attacks in federated learning using functional mappings of local models based on intermediate outputs. Experiments show that our mechanism is robust under a broad range of computing conditions and advanced attack scenarios, enabling safer collaboration among data-sensitive participants via federated learning.
Self Supervised Vision for Climate Downscaling
Jan 09, 2024Climate change is one of the most critical challenges that our planet is facing today. Rising global temperatures are already bringing noticeable changes to Earth's weather and climate patterns with an increased frequency of unpredictable and extreme weather events. Future projections for climate change research are based on Earth System Models (ESMs), the computer models that simulate the Earth's climate system. ESMs provide a framework to integrate various physical systems, but their output is bound by the enormous computational resources required for running and archiving higher-resolution simulations. For a given resource budget, the ESMs are generally run on a coarser grid, followed by a computationally lighter $downscaling$ process to obtain a finer-resolution output. In this work, we present a deep-learning model for downscaling ESM simulation data that does not require high-resolution ground truth data for model optimization. This is realized by leveraging salient data distribution patterns and the hidden dependencies between weather variables for an $\textit{individual}$ data point at $\textit{runtime}$. Extensive evaluation with $2$x, $3$x, and $4$x scaling factors demonstrates that the proposed model consistently obtains superior performance over that of various baselines. The improved downscaling performance and no dependence on high-resolution ground truth data make the proposed method a valuable tool for climate research and mark it as a promising direction for future research.
Generating High-Resolution Regional Precipitation Using Conditional Diffusion Model
Dec 12, 2023



Climate downscaling is a crucial technique within climate research, serving to project low-resolution (LR) climate data to higher resolutions (HR). Previous research has demonstrated the effectiveness of deep learning for downscaling tasks. However, most deep learning models for climate downscaling may not perform optimally for high scaling factors (i.e., 4x, 8x) due to their limited ability to capture the intricate details required for generating HR climate data. Furthermore, climate data behaves differently from image data, necessitating a nuanced approach when employing deep generative models. In response to these challenges, this paper presents a deep generative model for downscaling climate data, specifically precipitation on a regional scale. We employ a denoising diffusion probabilistic model (DDPM) conditioned on multiple LR climate variables. The proposed model is evaluated using precipitation data from the Community Earth System Model (CESM) v1.2.2 simulation. Our results demonstrate significant improvements over existing baselines, underscoring the effectiveness of the conditional diffusion model in downscaling climate data.