 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Facial Retargeting Using Local Patches
Jan 13, 2026In the era of digital animation, the quest to produce lifelike facial animations for virtual characters has led to the development of various retargeting methods. While the retargeting facial motion between models of similar shapes has been very successful, challenges arise when the retargeting is performed on stylized or exaggerated 3D characters that deviate significantly from human facial structures. In this scenario, it is important to consider the target character's facial structure and possible range of motion to preserve the semantics assumed by the original facial motions after the retargeting. To achieve this, we propose a local patch-based retargeting method that transfers facial animations captured in a source performance video to a target stylized 3D character. Our method consists of three modules. The Automatic Patch Extraction Module extracts local patches from the source video frame. These patches are processed through the Reenactment Module to generate correspondingly re-enacted target local patches. The Weight Estimation Module calculates the animation parameters for the target character at every frame for the creation of a complete facial animation sequence. Extensive experiments demonstrate that our method can successfully transfer the semantic meaning of source facial expressions to stylized characters with considerable variations in facial feature proportion.
* Eurographics 25
Customs Import Declaration Datasets
Aug 04, 2022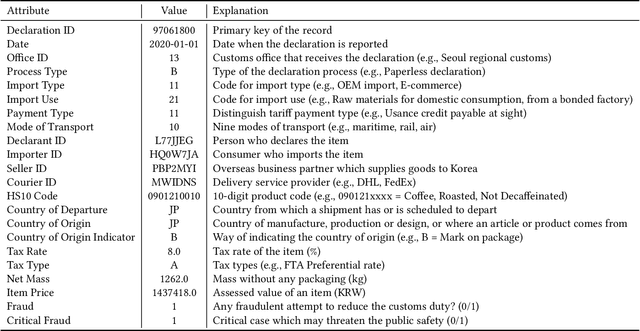

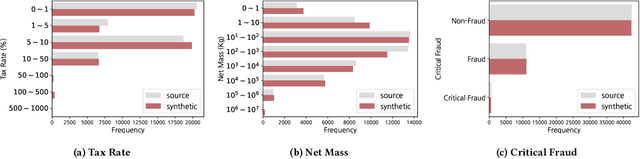
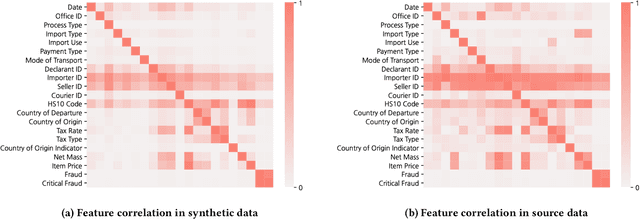
Given the huge volume of cross-border flows, effective and efficient control of trades becomes more crucial in protecting people and society from illicit trades while facilitating legitimate trades. However, limited accessibility of the transaction-level trade datasets hinders the progress of open research, and lots of customs administrations have not benefited from the recent progress in data-based risk management. In this paper, we introduce an import declarations dataset to facilitate the collaboration between the domain experts in customs administrations and data science researchers. The dataset contains 54,000 artificially generated trades with 22 key attributes, and it is synthesized with CTGAN while maintaining correlated features. Synthetic data has several advantages. First, releasing the dataset is free from restrictions that do not allow disclosing the original import data. Second, the fabrication step minimizes the possible identity risk which may exist in trade statistics. Lastly, the published data follow a similar distribution to the source data so that it can be used in various downstream tasks. With the provision of data and its generation process, we open baseline codes for fraud detection tasks, as we empirically show that more advanced algorithms can better detect frauds.
Classification of Goods Using Text Descriptions With Sentences Retrieval
Nov 02, 2021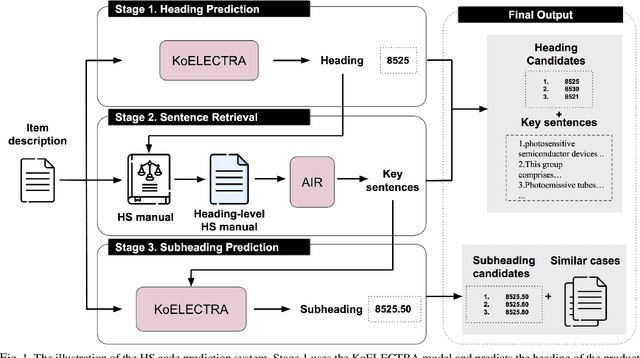
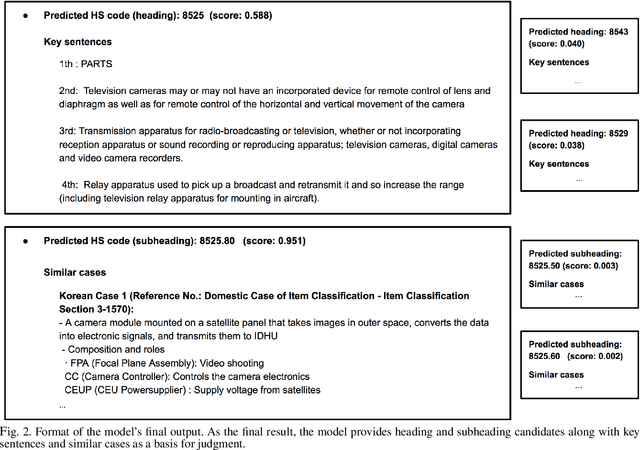
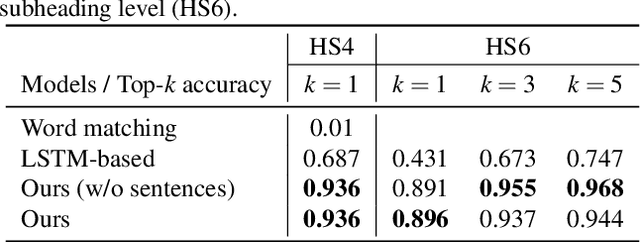

The task of assigning and validating internationally accepted commodity code (HS code) to traded goods is one of the critical functions at the customs office. This decision is crucial to importers and exporters, as it determines the tariff rate. However, similar to court decisions made by judges, the task can be non-trivial even for experienced customs officers. The current paper proposes a deep learning model to assist this seemingly challenging HS code classification. Together with Korea Customs Service, we built a decision model based on KoELECTRA that suggests the most likely heading and subheadings (i.e., the first four and six digits) of the HS code. Evaluation on 129,084 past cases shows that the top-3 suggestions made by our model have an accuracy of 95.5% in classifying 265 subheadings. This promising result implies algorithms may reduce the time and effort taken by customs officers substantially by assisting the HS code classification task.