 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustoms Import Declaration Datasets
Paper and Code
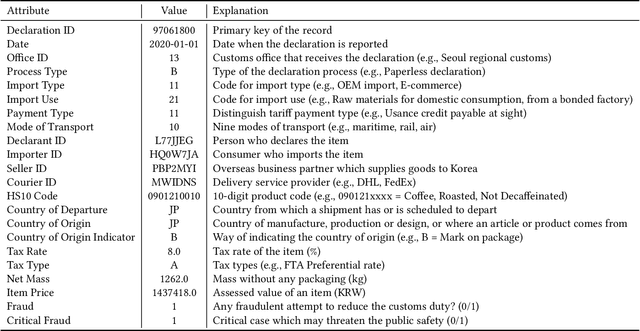

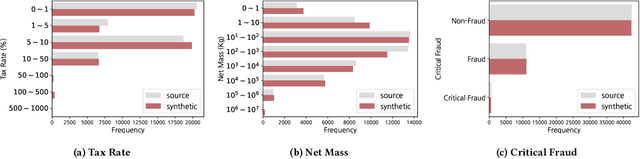
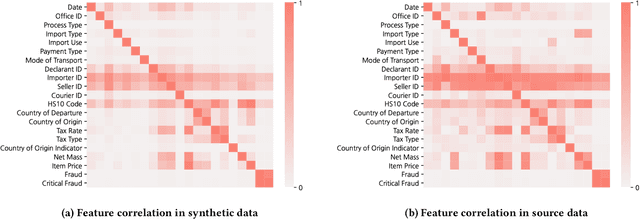
Given the huge volume of cross-border flows, effective and efficient control of trades becomes more crucial in protecting people and society from illicit trades while facilitating legitimate trades. However, limited accessibility of the transaction-level trade datasets hinders the progress of open research, and lots of customs administrations have not benefited from the recent progress in data-based risk management. In this paper, we introduce an import declarations dataset to facilitate the collaboration between the domain experts in customs administrations and data science researchers. The dataset contains 54,000 artificially generated trades with 22 key attributes, and it is synthesized with CTGAN while maintaining correlated features. Synthetic data has several advantages. First, releasing the dataset is free from restrictions that do not allow disclosing the original import data. Second, the fabrication step minimizes the possible identity risk which may exist in trade statistics. Lastly, the published data follow a similar distribution to the source data so that it can be used in various downstream tasks. With the provision of data and its generation process, we open baseline codes for fraud detection tasks, as we empirically show that more advanced algorithms can better detect frauds.