 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance evaluation of predictive AI models to support medical decisions: Overview and guidance
Dec 13, 2024
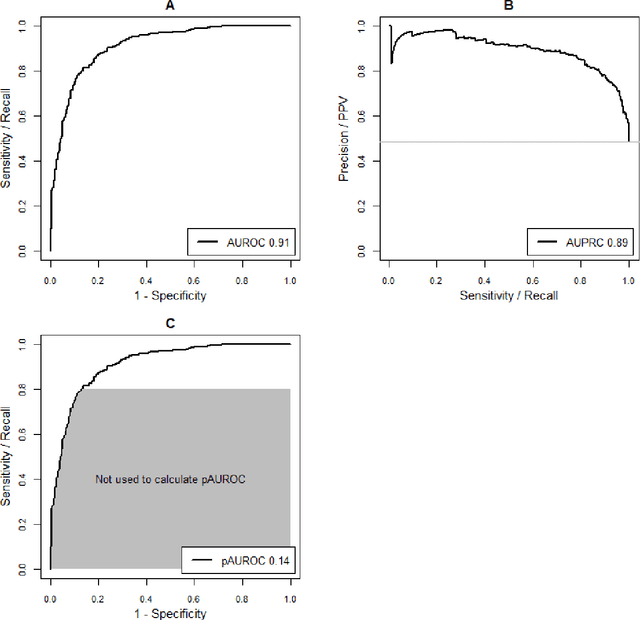
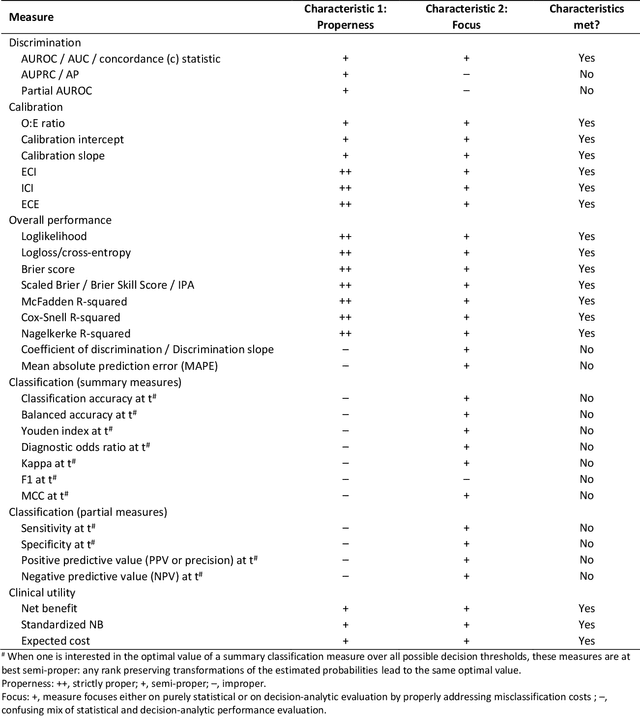
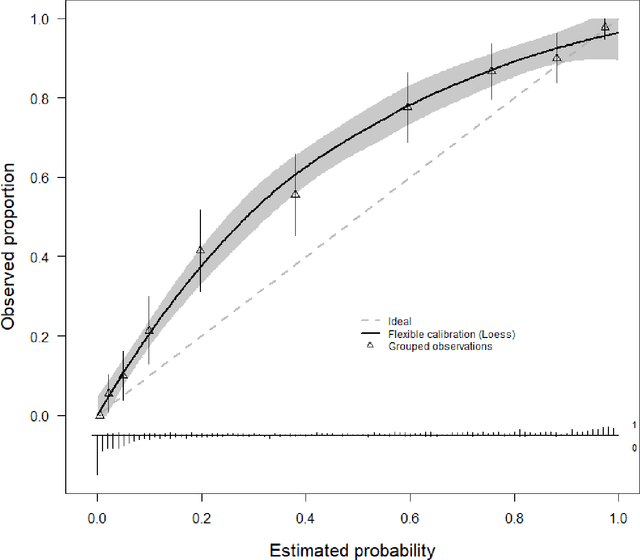
A myriad of measures to illustrate performance of predictive artificial intelligence (AI) models have been proposed in the literature. Selecting appropriate performance measures is essential for predictive AI models that are developed to be used in medical practice, because poorly performing models may harm patients and lead to increased costs. We aim to assess the merits of classic and contemporary performance measures when validating predictive AI models for use in medical practice. We focus on models with a binary outcome. We discuss 32 performance measures covering five performance domains (discrimination, calibration, overall, classification, and clinical utility) along with accompanying graphical assessments. The first four domains cover statistical performance, the fifth domain covers decision-analytic performance. We explain why two key characteristics are important when selecting which performance measures to assess: (1) whether the measure's expected value is optimized when it is calculated using the correct probabilities (i.e., a "proper" measure), and (2) whether they reflect either purely statistical performance or decision-analytic performance by properly considering misclassification costs. Seventeen measures exhibit both characteristics, fourteen measures exhibited one characteristic, and one measure possessed neither characteristic (the F1 measure). All classification measures (such as classification accuracy and F1) are improper for clinically relevant decision thresholds other than 0.5 or the prevalence. We recommend the following measures and plots as essential to report: AUROC, calibration plot, a clinical utility measure such as net benefit with decision curve analysis, and a plot with probability distributions per outcome category.
Self Supervised Vision for Climate Downscaling
Jan 09, 2024Climate change is one of the most critical challenges that our planet is facing today. Rising global temperatures are already bringing noticeable changes to Earth's weather and climate patterns with an increased frequency of unpredictable and extreme weather events. Future projections for climate change research are based on Earth System Models (ESMs), the computer models that simulate the Earth's climate system. ESMs provide a framework to integrate various physical systems, but their output is bound by the enormous computational resources required for running and archiving higher-resolution simulations. For a given resource budget, the ESMs are generally run on a coarser grid, followed by a computationally lighter $downscaling$ process to obtain a finer-resolution output. In this work, we present a deep-learning model for downscaling ESM simulation data that does not require high-resolution ground truth data for model optimization. This is realized by leveraging salient data distribution patterns and the hidden dependencies between weather variables for an $\textit{individual}$ data point at $\textit{runtime}$. Extensive evaluation with $2$x, $3$x, and $4$x scaling factors demonstrates that the proposed model consistently obtains superior performance over that of various baselines. The improved downscaling performance and no dependence on high-resolution ground truth data make the proposed method a valuable tool for climate research and mark it as a promising direction for future research.
Generating High-Resolution Regional Precipitation Using Conditional Diffusion Model
Dec 12, 2023



Climate downscaling is a crucial technique within climate research, serving to project low-resolution (LR) climate data to higher resolutions (HR). Previous research has demonstrated the effectiveness of deep learning for downscaling tasks. However, most deep learning models for climate downscaling may not perform optimally for high scaling factors (i.e., 4x, 8x) due to their limited ability to capture the intricate details required for generating HR climate data. Furthermore, climate data behaves differently from image data, necessitating a nuanced approach when employing deep generative models. In response to these challenges, this paper presents a deep generative model for downscaling climate data, specifically precipitation on a regional scale. We employ a denoising diffusion probabilistic model (DDPM) conditioned on multiple LR climate variables. The proposed model is evaluated using precipitation data from the Community Earth System Model (CESM) v1.2.2 simulation. Our results demonstrate significant improvements over existing baselines, underscoring the effectiveness of the conditional diffusion model in downscaling climate data.
An AI-Guided Data Centric Strategy to Detect and Mitigate Biases in Healthcare Datasets
Nov 06, 2023The adoption of diagnosis and prognostic algorithms in healthcare has led to concerns about the perpetuation of bias against disadvantaged groups of individuals. Deep learning methods to detect and mitigate bias have revolved around modifying models, optimization strategies, and threshold calibration with varying levels of success. Here, we generate a data-centric, model-agnostic, task-agnostic approach to evaluate dataset bias by investigating the relationship between how easily different groups are learned at small sample sizes (AEquity). We then apply a systematic analysis of AEq values across subpopulations to identify and mitigate manifestations of racial bias in two known cases in healthcare - Chest X-rays diagnosis with deep convolutional neural networks and healthcare utilization prediction with multivariate logistic regression. AEq is a novel and broadly applicable metric that can be applied to advance equity by diagnosing and remediating bias in healthcare datasets.
GraphFC: Customs Fraud Detection with Label Scarcity
May 19, 2023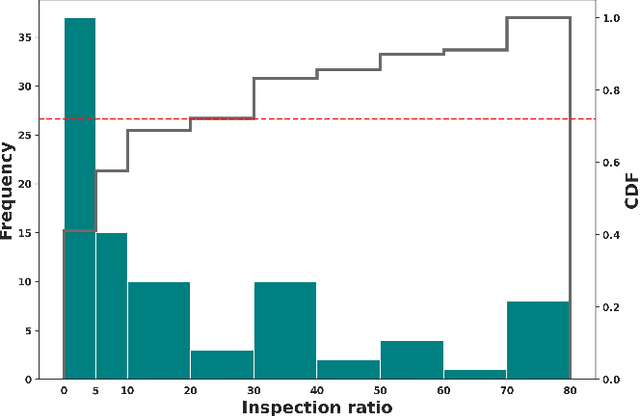



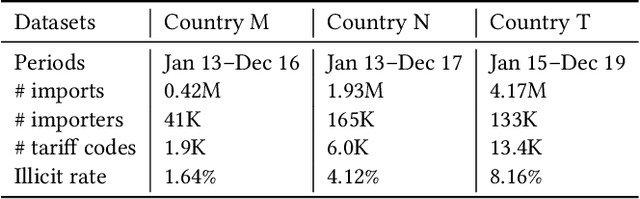
Custom officials across the world encounter huge volumes of transactions. With increased connectivity and globalization, the customs transactions continue to grow every year. Associated with customs transactions is the customs fraud - the intentional manipulation of goods declarations to avoid the taxes and duties. With limited manpower, the custom offices can only undertake manual inspection of a limited number of declarations. This necessitates the need for automating the customs fraud detection by machine learning (ML) techniques. Due the limited manual inspection for labeling the new-incoming declarations, the ML approach should have robust performance subject to the scarcity of labeled data. However, current approaches for customs fraud detection are not well suited and designed for this real-world setting. In this work, we propose $\textbf{GraphFC}$ ($\textbf{Graph}$ neural networks for $\textbf{C}$ustoms $\textbf{F}$raud), a model-agnostic, domain-specific, semi-supervised graph neural network based customs fraud detection algorithm that has strong semi-supervised and inductive capabilities. With upto 252% relative increase in recall over the present state-of-the-art, extensive experimentation on real customs data from customs administrations of three different countries demonstrate that GraphFC consistently outperforms various baselines and the present state-of-art by a large margin.
The Internet of Federated Things : A Vision for the Future and In-depth Survey of Data-driven Approaches for Federated Learning
Nov 09, 2021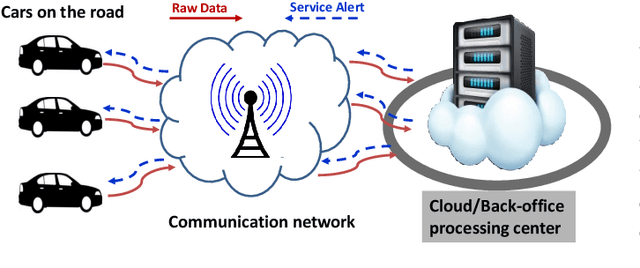
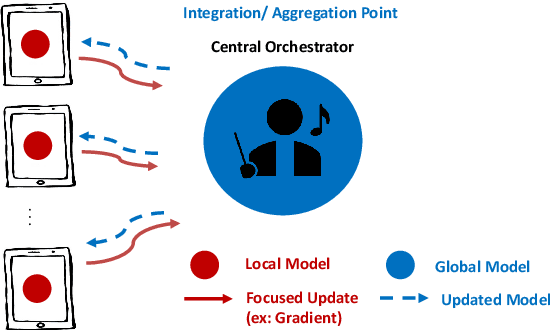
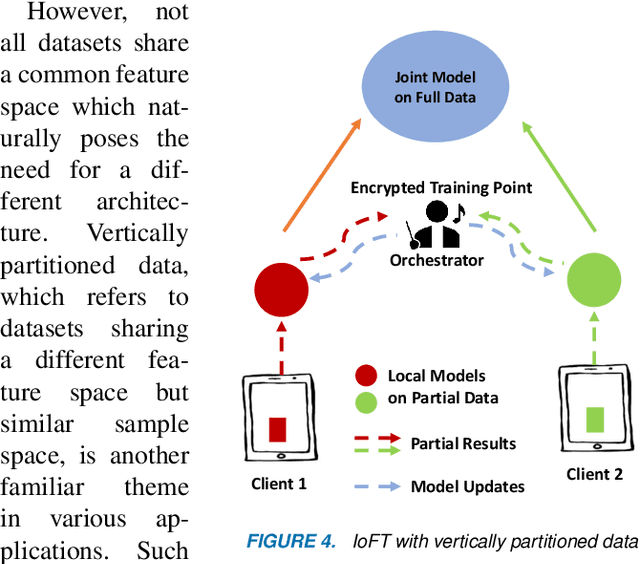
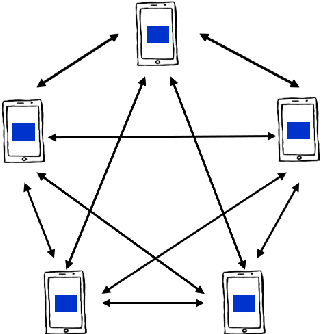
The Internet of Things (IoT) is on the verge of a major paradigm shift. In the IoT system of the future, IoFT, the cloud will be substituted by the crowd where model training is brought to the edge, allowing IoT devices to collaboratively extract knowledge and build smart analytics/models while keeping their personal data stored locally. This paradigm shift was set into motion by the tremendous increase in computational power on IoT devices and the recent advances in decentralized and privacy-preserving model training, coined as federated learning (FL). This article provides a vision for IoFT and a systematic overview of current efforts towards realizing this vision. Specifically, we first introduce the defining characteristics of IoFT and discuss FL data-driven approaches, opportunities, and challenges that allow decentralized inference within three dimensions: (i) a global model that maximizes utility across all IoT devices, (ii) a personalized model that borrows strengths across all devices yet retains its own model, (iii) a meta-learning model that quickly adapts to new devices or learning tasks. We end by describing the vision and challenges of IoFT in reshaping different industries through the lens of domain experts. Those industries include manufacturing, transportation, energy, healthcare, quality & reliability, business, and computing.
Take a Chance: Managing the Exploitation-Exploration Dilemma in Customs Fraud Detection via Online Active Learning
Oct 27, 2020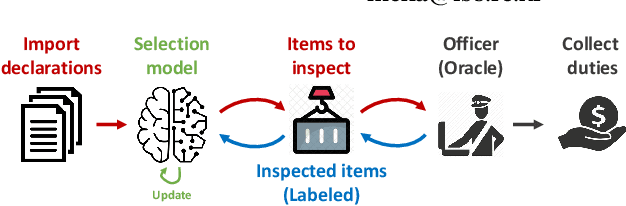

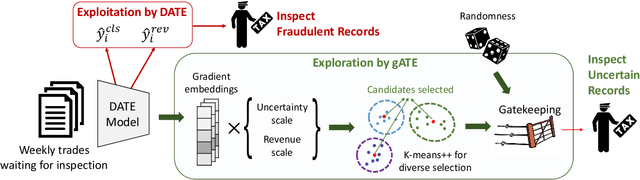
Continual labeling of training examples is a costly task in supervised learning. Active learning strategies mitigate this cost by identifying unlabeled data that are considered the most useful for training a predictive model. However, sample selection via active learning may lead to an exploitation-exploration dilemma. In online settings, profitable items can be neglected when uncertain items are annotated instead. To illustrate this dilemma, we study a human-in-the-loop customs selection scenario where an AI-based system supports customs officers by providing a set of imports to be inspected. If the inspected items are fraud, officers levy extra duties, and these items will be used as additional training data for the next iterations. Inspecting highly suspicious items will inevitably lead to additional customs revenue, yet they may not give any extra knowledge to customs officers. On the other hand, inspecting uncertain items will help customs officers to acquire new knowledge, which will be used as supplementary training resources to update their selection systems. Through years of customs selection simulation, we show that some exploration is needed to cope with the domain shift, and our hybrid strategy of selecting fraud and uncertain items will eventually outperform the performance of the exploitation strategy.