 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptEmbedder:: Efficient and Transferable Text Embedding via Dual-LLM Soft Prompting
May 27, 2026Large Language Models (LLMs) have demonstrated remarkable efficacy in text embedding, yet current adaptation methods like LoRA face significant bottlenecks in computational efficiency and cross-architecture transferability. Whenever a new backbone emerges, existing approaches require costly retraining from scratch. To address this, we propose PromptEmbedder, a novel dual-LLM framework that decouples embedding knowledge from specific backbone weights. PromptEmbedder utilizes a Prompting LLM to generate instruction-aware soft prompts for a frozen Embedding LLM via a differentiable generation process with continuous relaxation, ensuring full gradient flow during contrastive training. By localizing task-specific knowledge within the Prompting LLM, adapting to new architectures requires only retraining a lightweight linear alignment matrix. Evaluations on the MTEB benchmark show that PromptEmbedder achieves comparable performance with LoRA finetuning while reducing GPU memory by 40% and accelerating training by 3.7x. Our approach establishes a scalable, architecture-agnostic paradigm for efficient LLM-based representation learning.
Concept-Aware Privacy Mechanisms for Defending Embedding Inversion Attacks
Feb 06, 2026Text embeddings enable numerous NLP applications but face severe privacy risks from embedding inversion attacks, which can expose sensitive attributes or reconstruct raw text. Existing differential privacy defenses assume uniform sensitivity across embedding dimensions, leading to excessive noise and degraded utility. We propose SPARSE, a user-centric framework for concept-specific privacy protection in text embeddings. SPARSE combines (1) differentiable mask learning to identify privacy-sensitive dimensions for user-defined concepts, and (2) the Mahalanobis mechanism that applies elliptical noise calibrated by dimension sensitivity. Unlike traditional spherical noise injection, SPARSE selectively perturbs privacy-sensitive dimensions while preserving non-sensitive semantics. Evaluated across six datasets with three embedding models and attack scenarios, SPARSE consistently reduces privacy leakage while achieving superior downstream performance compared to state-of-the-art DP methods.
Uncertainty Profiles for LLMs: Uncertainty Source Decomposition and Adaptive Model-Metric Selection
May 12, 2025Large language models (LLMs) often generate fluent but factually incorrect outputs, known as hallucinations, which undermine their reliability in real-world applications. While uncertainty estimation has emerged as a promising strategy for detecting such errors, current metrics offer limited interpretability and lack clarity about the types of uncertainty they capture. In this paper, we present a systematic framework for decomposing LLM uncertainty into four distinct sources, inspired by previous research. We develop a source-specific estimation pipeline to quantify these uncertainty types and evaluate how existing metrics relate to each source across tasks and models. Our results show that metrics, task, and model exhibit systematic variation in uncertainty characteristic. Building on this, we propose a method for task specific metric/model selection guided by the alignment or divergence between their uncertainty characteristics and that of a given task. Our experiments across datasets and models demonstrate that our uncertainty-aware selection strategy consistently outperforms baseline strategies, helping us select appropriate models or uncertainty metrics, and contributing to more reliable and efficient deployment in uncertainty estimation.
PLHF: Prompt Optimization with Few-Shot Human Feedback
May 11, 2025Automatic prompt optimization frameworks are developed to obtain suitable prompts for large language models (LLMs) with respect to desired output quality metrics. Although existing approaches can handle conventional tasks such as fixed-solution question answering, defining the metric becomes complicated when the output quality cannot be easily assessed by comparisons with standard golden samples. Consequently, optimizing the prompts effectively and efficiently without a clear metric becomes a critical challenge. To address the issue, we present PLHF (which stands for "P"rompt "L"earning with "H"uman "F"eedback), a few-shot prompt optimization framework inspired by the well-known RLHF technique. Different from naive strategies, PLHF employs a specific evaluator module acting as the metric to estimate the output quality. PLHF requires only a single round of human feedback to complete the entire prompt optimization process. Empirical results on both public and industrial datasets show that PLHF outperforms prior output grading strategies for LLM prompt optimizations.
Think or Remember? Detecting and Directing LLMs Towards Memorization or Generalization
Dec 24, 2024


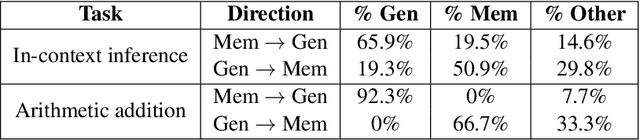
In this paper, we explore the foundational mechanisms of memorization and generalization in Large Language Models (LLMs), inspired by the functional specialization observed in the human brain. Our investigation serves as a case study leveraging specially designed datasets and experimental-scale LLMs to lay the groundwork for understanding these behaviors. Specifically, we aim to first enable LLMs to exhibit both memorization and generalization by training with the designed dataset, then (a) examine whether LLMs exhibit neuron-level spatial differentiation for memorization and generalization, (b) predict these behaviors using model internal representations, and (c) steer the behaviors through inference-time interventions. Our findings reveal that neuron-wise differentiation of memorization and generalization is observable in LLMs, and targeted interventions can successfully direct their behavior.
Benchmarking Large Language Model Uncertainty for Prompt Optimization
Sep 16, 2024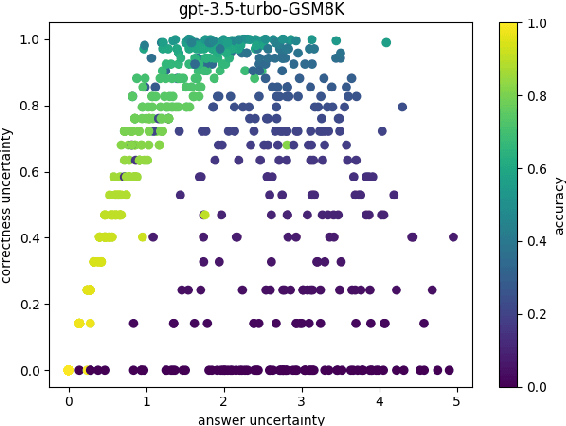
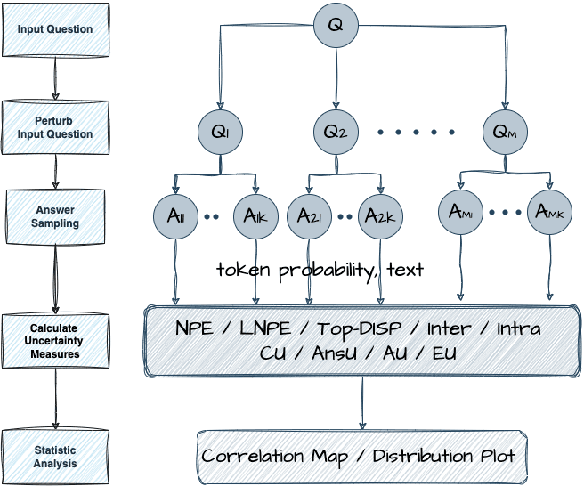
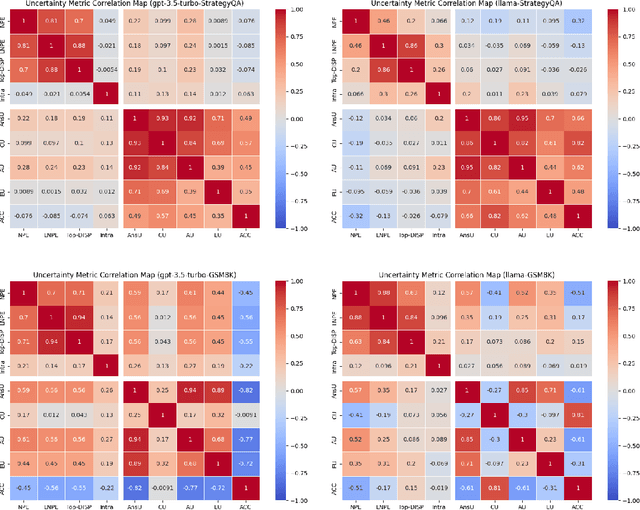
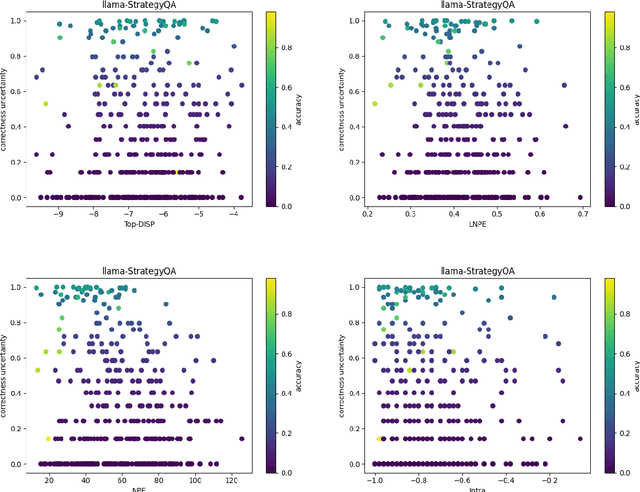
Prompt optimization algorithms for Large Language Models (LLMs) excel in multi-step reasoning but still lack effective uncertainty estimation. This paper introduces a benchmark dataset to evaluate uncertainty metrics, focusing on Answer, Correctness, Aleatoric, and Epistemic Uncertainty. Through analysis of models like GPT-3.5-Turbo and Meta-Llama-3.1-8B-Instruct, we show that current metrics align more with Answer Uncertainty, which reflects output confidence and diversity, rather than Correctness Uncertainty, highlighting the need for improved metrics that are optimization-objective-aware to better guide prompt optimization. Our code and dataset are available at https://github.com/0Frett/PO-Uncertainty-Benchmarking.
Enhance Modality Robustness in Text-Centric Multimodal Alignment with Adversarial Prompting
Aug 19, 2024Converting different modalities into generalized text, which then serves as input prompts for large language models (LLMs), is a common approach for aligning multimodal models, particularly when pairwise data is limited. Text-centric alignment method leverages the unique properties of text as a modality space, transforming diverse inputs into a unified textual representation, thereby enabling downstream models to effectively interpret various modal inputs. This study evaluates the quality and robustness of multimodal representations in the face of noise imperfections, dynamic input order permutations, and missing modalities, revealing that current text-centric alignment methods can compromise downstream robustness. To address this issue, we propose a new text-centric adversarial training approach that significantly enhances robustness compared to traditional robust training methods and pre-trained multimodal foundation models. Our findings underscore the potential of this approach to improve the robustness and adaptability of multimodal representations, offering a promising solution for dynamic and real-world applications.
Investigating Instruction Tuning Large Language Models on Graphs
Aug 10, 2024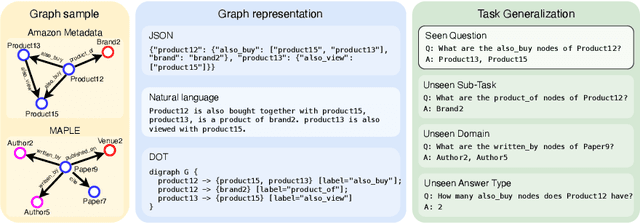
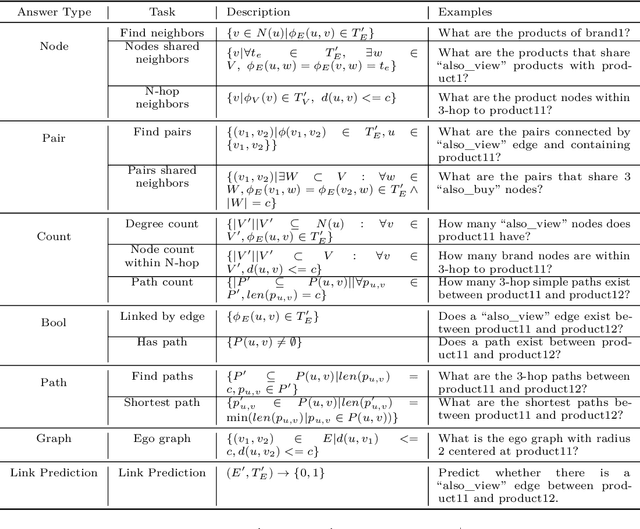

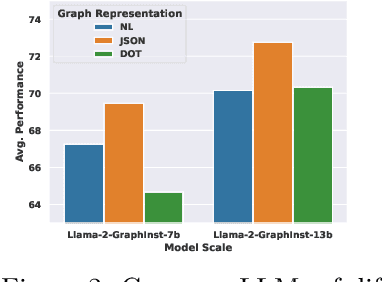
Inspired by the recent advancements of Large Language Models (LLMs) in NLP tasks, there's growing interest in applying LLMs to graph-related tasks. This study delves into the capabilities of instruction-following LLMs for engaging with real-world graphs, aiming to offer empirical insights into how LLMs can effectively interact with graphs and generalize across graph tasks. We begin by constructing a dataset designed for instruction tuning, which comprises a diverse collection of 79 graph-related tasks from academic and e-commerce domains, featuring 44,240 training instances and 18,960 test samples. Utilizing this benchmark, our initial investigation focuses on identifying the optimal graph representation that serves as a conduit for LLMs to understand complex graph structures. Our findings indicate that JSON format for graph representation consistently outperforms natural language and code formats across various LLMs and graph types. Furthermore, we examine the key factors that influence the generalization abilities of instruction-tuned LLMs by evaluating their performance on both in-domain and out-of-domain graph tasks.
Enhance the Robustness of Text-Centric Multimodal Alignments
Jul 06, 2024Converting different modalities into general text, serving as input prompts for large language models (LLMs), is a common method to align multimodal models when there is limited pairwise data. This text-centric approach leverages the unique properties of text as a modality space, transforming diverse inputs into a unified textual representation. This enables downstream models to effectively interpret various modal inputs. This study assesses the quality and robustness of multimodal representations in the presence of missing entries, noise, or absent modalities, revealing that current text-centric alignment methods compromise downstream robustness. To address this issue, we propose a new text-centric approach that achieves superior robustness compared to previous methods across various modalities in different settings. Our findings highlight the potential of this approach to enhance the robustness and adaptability of multimodal representations, offering a promising solution for dynamic and real-world applications.
Transferable Embedding Inversion Attack: Uncovering Privacy Risks in Text Embeddings without Model Queries
Jun 12, 2024This study investigates the privacy risks associated with text embeddings, focusing on the scenario where attackers cannot access the original embedding model. Contrary to previous research requiring direct model access, we explore a more realistic threat model by developing a transfer attack method. This approach uses a surrogate model to mimic the victim model's behavior, allowing the attacker to infer sensitive information from text embeddings without direct access. Our experiments across various embedding models and a clinical dataset demonstrate that our transfer attack significantly outperforms traditional methods, revealing the potential privacy vulnerabilities in embedding technologies and emphasizing the need for enhanced security measures.